1. story
也许你经常会被问到,库里某个表最近一年的内每个月的数据量增长情况。当然如果你有按月分表比较好办,挨个
show table status,如果只有一个大表,那估计要在大家都休息的时候,寂寞的夜里去跑sql统计了,因为你只能获取当前的表信息,历史信息追查不到了。
除此以外,作为DBA本身也要对数据库空间增长情况进行预估,用以规划容量。我们说的表信息主要包括:
环境
在 python 2.7 环境下编写的,2.6,3.x没测。
运行需要
MySQLdb、
influxdb两个库:
$ sudo pip install mysql-python influxdb
配置
settings_dbs.py配置文件
DBLIST_INFO:列表存放需要采集的哪些MySQL实例表信息,元组内分别是连接地址、端口、用户名、密码
用户需要select表的权限,否则看不到对应的信息.
InfluxDB_INFO:influxdb的连接信息,注意提前创建好数据库名
mysql_info
设置为
None可输出结果为json.
创建influxdb上的数据库和存储策略
存放2年,1个复制集:(按需调整)
CREATE DATABASE "mysql_info" CREATE RETENTION POLICY "mysql_info_schema" ON "mysql_info" DURATION 730d REPLICATION 1 DEFAULT
看大的信息类似于: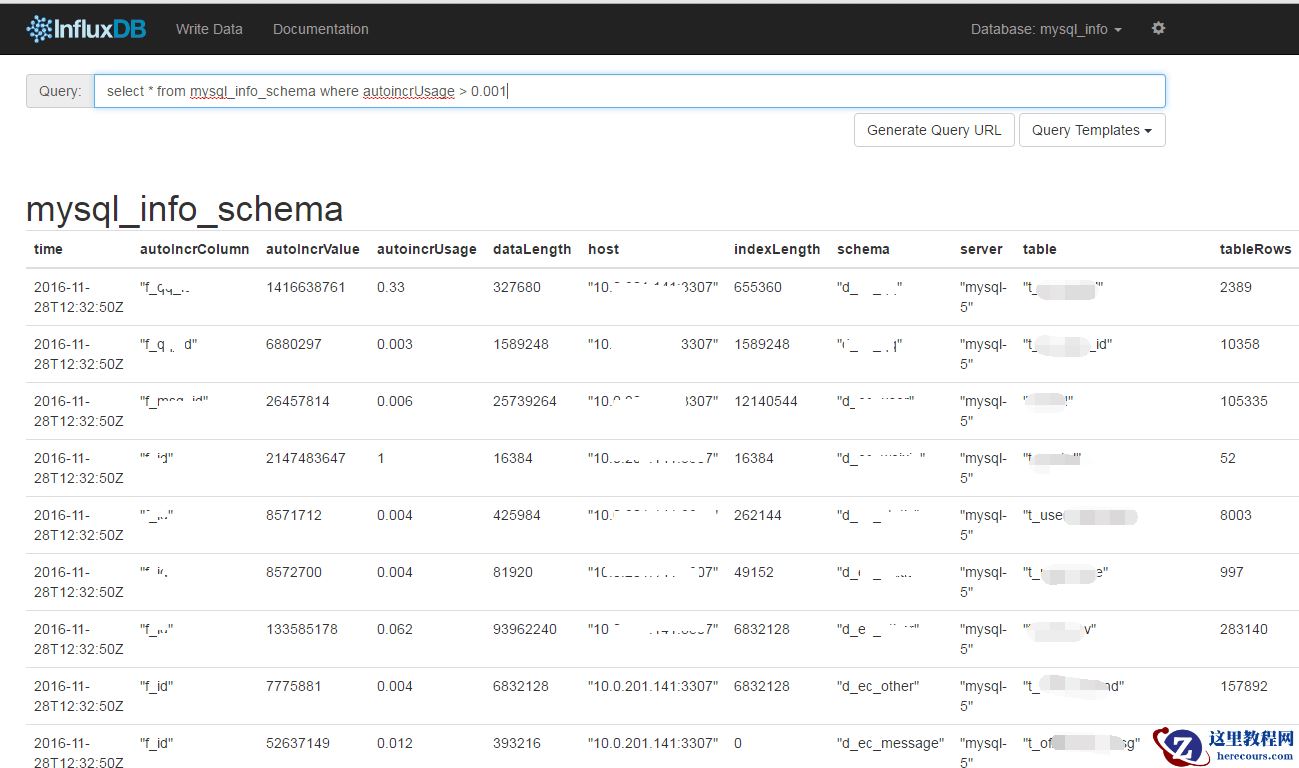
放crontab跑
可以单独放在用于监控的服务器上,不过建议在生产环境可以运行在mysql实例所在主机上,安全起见。
一般库在晚上会有数据迁移的动作,可以在迁移前后分别运行
mysql_schema_info.py来收集一次。不建议太频繁。
40 23,5,12,18 * * * /opt/DBschema_info/mysql_schema_info.py >> /tmp/collect_DBschema_info.log 2>&1
生成图表
导入项目下的
grafana_table_stats.json到 Grafana面板中。效果如下:
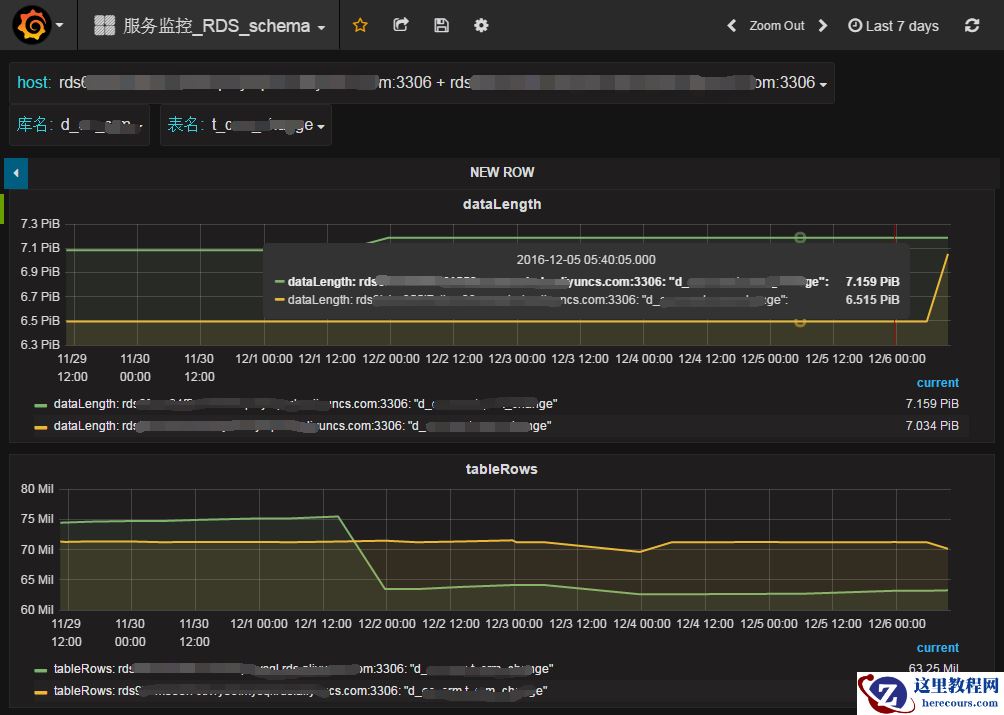
表数据大小和行数
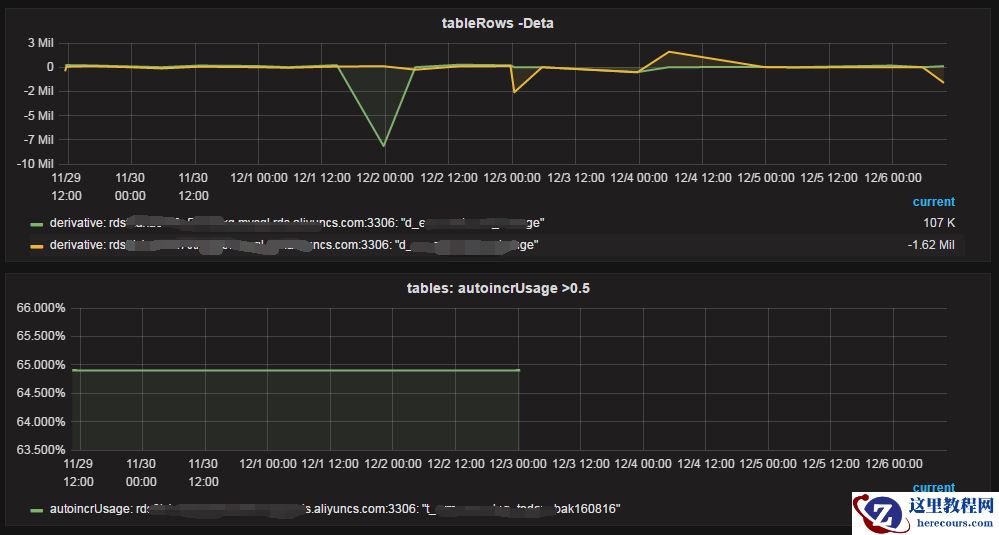
每天行数变化增量,auto_increment使用率
4. More
分库分表情况下,全局唯一ID在表里无法计算 autoIncrUsage
实现上其实很简单,更主要的是唤醒收集这些信息的意识
可以增加 Graphite 输出格式



")
")
")


")
")

密码在Linux(CentOS)下如何重置(图文)")
")