网上都是PMM Percona Monitoring and Management的安装部署文章,今天我出一个使用PMM的教学文章,寻找数据库负载最高的语句例子。
一、
问题
PMM Query Analytics
的查询分析器使用方法
二、下面用一个例子来介绍查询分析器的使用方法,介绍各个参数的意思。先上图
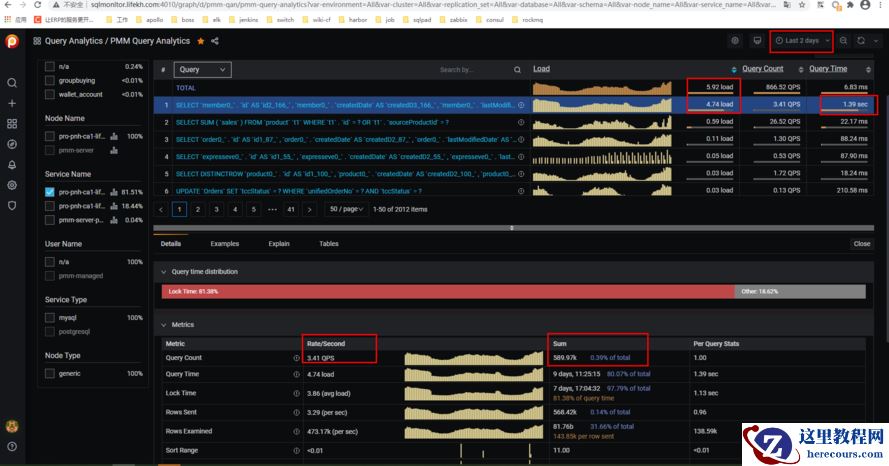 这个图意思是:我选择了
2
天取样时间,对
load
进行排序,选择一条
sql
语句,这条
sql
语句每秒执行
3.41
次,
2
天时间里总共执行了
589970
次,
sql
负载占整个
sql
的负载是
80%
。这个是很高很高的了。
如上图,我选择了
sql
语句
select member0_.id as id2_166_, member0_.createdDate as createdD3_166_, member0_.lastModifiedDate as lastModi4_166_, member0_.version as version5_166_, member0_.isEnabled as isEnable6_166_, member0_.isLocked as isLocked7_166_, member0_.lastLoginDate as lastLogi8_166_, member0_.lastLoginIp as lastLogi9_166_, member0_.lockDate as lockDat10_166_, member0_.mobile as mobile11_166_, member0_.operatorNo as operato12_166_, member0_.address as address57_166_, member0_.amount as amount58_166_, member0_.area_id as area_id67_166_, member0_.attributeValue0 as attribu18_166_, member0_.attributeValue1 as attribu19_166_, member0_.attributeValue2 as attribu30_166_, member0_.attributeValue3 as attribu31_166_, member0_.attributeValue4 as attribu32_166_, member0_.attributeValue5 as attribu33_166_, member0_.attributeValue6 as attribu34_166_, member0_.attributeValue7 as attribu35_166_, member0_.attributeValue8 as attribu36_166_, member0_.attributeValue9 as attribu37_166_, member0_.balance as balance38_166_, member0_.birth as birth59_166_, member0_.commissionBalance as commiss60_166_, member0_.email as email14_166_, member0_.encodedPassword as encoded15_166_, member0_.frozenAmount as frozenA42_166_, member0_.frozenCommissionBalance as frozenC61_166_, member0_.gender as gender62_166_, member0_.headimgurl as headimg63_166_, member0_.memberRank_id as memberR68_166_, member0_.name as name16_166_, member0_.nickname as nicknam64_166_, member0_.phone as phone52_166_, member0_.point as point65_166_, member0_.safeKeyExpire as safeKey53_166_, member0_.safeKeyValue as safeKey54_166_, member0_.username as usernam17_166_, member0_.zipCode as zipCode66_166_ from Users member0_ where member0_.dtype=
?
and member0_.operatorNo=
?
得到了下面表格的一些计算数据:
三、
名称解释
query time
: 这里的
query time
和
mysql
的慢日志里面query time 两个概念是一样的吗? 答案是:2个概念是不一样的。这个是什么意思呢?这个
query time ,
是这条语句总共执行了
9 days,11:25:15
这么长时间,总共执行了
589.97k
次,得到的平均执行时间是
817200/589970=1.39 sec
。这里有个奇怪的问题是,我取样的时间是
2days,
仔细看图,为什么这条语句执行时间是
9
天又
11
个小时呢?这里埋个问题。
Load
:这里的
load
我没有真正看出来了含义,表示
sql
执行时间的负载。这里要注意
sql
负载占比百分比才有意义。这条
sql
语句占比
80%
,说明数据库大部分时间用于执行这条语句。
Query count
:执行次数,本条语句执行
589970
次,
qps
是
3.41
Rows examined
:每次执行扫描的行数
473170,
为了执行这条语句,数据库每次需要扫描
473170
条记录才能得到这一条记录,哎呀,好累呀,计算机干活还是很卖力的,每次执行这条语句都要查询这么多记录。
query time
是这条语句的平均执行时间,慢日志查询的
query time
是本条语句当前执行时间。
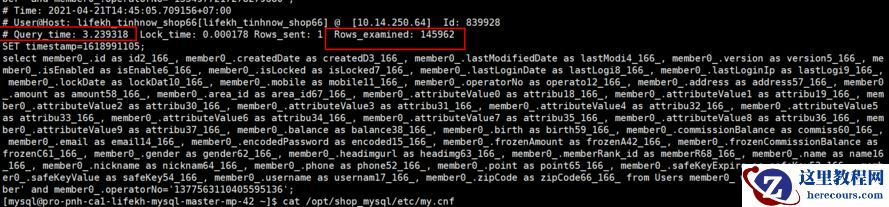
发现这条语句有问题后,我去慢查询日志看,
慢查询日志有2G大,找到了慢日志sql:
这个图意思是:我选择了
2
天取样时间,对
load
进行排序,选择一条
sql
语句,这条
sql
语句每秒执行
3.41
次,
2
天时间里总共执行了
589970
次,
sql
负载占整个
sql
的负载是
80%
。这个是很高很高的了。
如上图,我选择了
sql
语句
select member0_.id as id2_166_, member0_.createdDate as createdD3_166_, member0_.lastModifiedDate as lastModi4_166_, member0_.version as version5_166_, member0_.isEnabled as isEnable6_166_, member0_.isLocked as isLocked7_166_, member0_.lastLoginDate as lastLogi8_166_, member0_.lastLoginIp as lastLogi9_166_, member0_.lockDate as lockDat10_166_, member0_.mobile as mobile11_166_, member0_.operatorNo as operato12_166_, member0_.address as address57_166_, member0_.amount as amount58_166_, member0_.area_id as area_id67_166_, member0_.attributeValue0 as attribu18_166_, member0_.attributeValue1 as attribu19_166_, member0_.attributeValue2 as attribu30_166_, member0_.attributeValue3 as attribu31_166_, member0_.attributeValue4 as attribu32_166_, member0_.attributeValue5 as attribu33_166_, member0_.attributeValue6 as attribu34_166_, member0_.attributeValue7 as attribu35_166_, member0_.attributeValue8 as attribu36_166_, member0_.attributeValue9 as attribu37_166_, member0_.balance as balance38_166_, member0_.birth as birth59_166_, member0_.commissionBalance as commiss60_166_, member0_.email as email14_166_, member0_.encodedPassword as encoded15_166_, member0_.frozenAmount as frozenA42_166_, member0_.frozenCommissionBalance as frozenC61_166_, member0_.gender as gender62_166_, member0_.headimgurl as headimg63_166_, member0_.memberRank_id as memberR68_166_, member0_.name as name16_166_, member0_.nickname as nicknam64_166_, member0_.phone as phone52_166_, member0_.point as point65_166_, member0_.safeKeyExpire as safeKey53_166_, member0_.safeKeyValue as safeKey54_166_, member0_.username as usernam17_166_, member0_.zipCode as zipCode66_166_ from Users member0_ where member0_.dtype=
?
and member0_.operatorNo=
?
得到了下面表格的一些计算数据:
三、
名称解释
query time
: 这里的
query time
和
mysql
的慢日志里面query time 两个概念是一样的吗? 答案是:2个概念是不一样的。这个是什么意思呢?这个
query time ,
是这条语句总共执行了
9 days,11:25:15
这么长时间,总共执行了
589.97k
次,得到的平均执行时间是
817200/589970=1.39 sec
。这里有个奇怪的问题是,我取样的时间是
2days,
仔细看图,为什么这条语句执行时间是
9
天又
11
个小时呢?这里埋个问题。
Load
:这里的
load
我没有真正看出来了含义,表示
sql
执行时间的负载。这里要注意
sql
负载占比百分比才有意义。这条
sql
语句占比
80%
,说明数据库大部分时间用于执行这条语句。
Query count
:执行次数,本条语句执行
589970
次,
qps
是
3.41
Rows examined
:每次执行扫描的行数
473170,
为了执行这条语句,数据库每次需要扫描
473170
条记录才能得到这一条记录,哎呀,好累呀,计算机干活还是很卖力的,每次执行这条语句都要查询这么多记录。
query time
是这条语句的平均执行时间,慢日志查询的
query time
是本条语句当前执行时间。
发现这条语句有问题后,我去慢查询日志看,
慢查询日志有2G大,找到了慢日志sql:
 四、现在开始优化这条语句。
看下现在执行计划:
四、现在开始优化这条语句。
看下现在执行计划:
 这条语句用到了索引
key,
不过仍然很慢,执行时间需要
3
秒。检索了
40401
条记录。
看下这个表建立了哪些索引?
这条语句用到了索引
key,
不过仍然很慢,执行时间需要
3
秒。检索了
40401
条记录。
看下这个表建立了哪些索引?
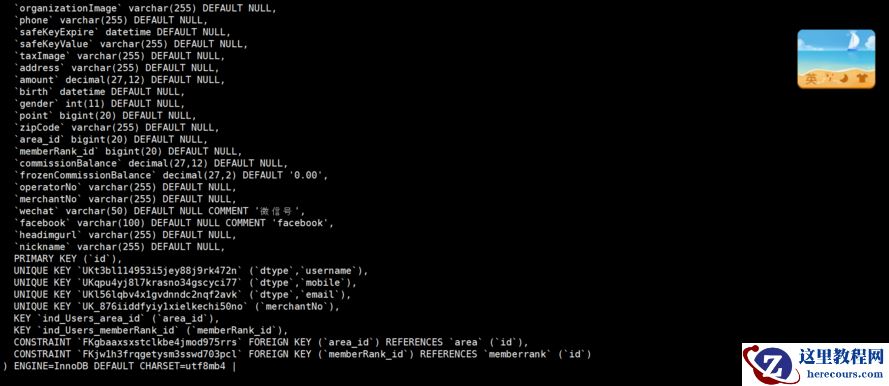 果然有
UKt3bl114953i5jey88j9rk472n
这个索引。
那为什么还是这么慢呢?这里思考
2
分钟接着往下看:
因为这个索引
(`dtype`,`username`)
能检索到的数据量还是比较大的,不够高效,用了这个索引还要检索40401条记录。那现在建立一个更加高效的索引:
create index idx_users_operatorno_2 on users(operatorNo,dtype);
这个时候你再来看执行计划:
果然有
UKt3bl114953i5jey88j9rk472n
这个索引。
那为什么还是这么慢呢?这里思考
2
分钟接着往下看:
因为这个索引
(`dtype`,`username`)
能检索到的数据量还是比较大的,不够高效,用了这个索引还要检索40401条记录。那现在建立一个更加高效的索引:
create index idx_users_operatorno_2 on users(operatorNo,dtype);
这个时候你再来看执行计划:
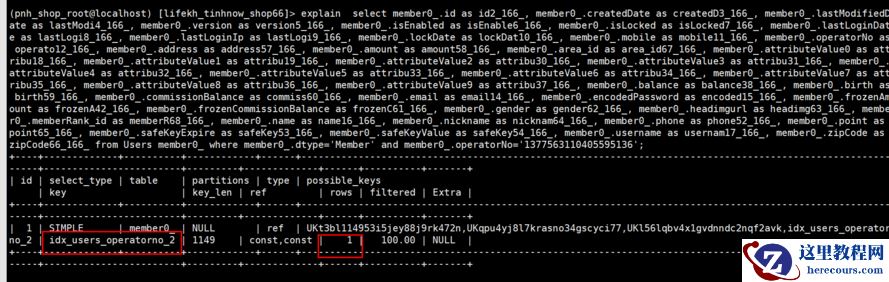 看到没有,使用了我新建立的索引,检索数据变成
1
条,这样,再执行一下这条语句,就是
0.01
秒。好了问题解决。
看到没有,使用了我新建立的索引,检索数据变成
1
条,这样,再执行一下这条语句,就是
0.01
秒。好了问题解决。
四、 刚刚说的 PMM 的 query time 和慢查询的 query time 计算方法不一样,假如,如果,我需要方便的从 PMM 的界面得到 sql 语句一次查询的 query time,该怎么操作 呢? 答案:缩短取样时间。 五、 总结:用 PMM 查询分析,用 load 排序,可以找到负载最大的 sql ,优化这个 sql ,整个数据库的负载就下来了。为什么呀?其实你可以思考下,数据库是什么?可以这样理解:就是一个不停执行 sql 语句然后返回结果给用户的机器嘛,没有了慢查询 sql ,数据库负载降低,吞吐量就会提高,表现就会快嘛。











