自己原文公众号:
https://mp.weixin.qq.com/s/wyGjHLP2lSD0WhdJq5j4Ow
很多人都说数据库处理不了,到大数据中去处理。似乎有一种错误的认识,好像大数据很快一样?今天本文以MySQL为例。Oracle PG更加不用说了。
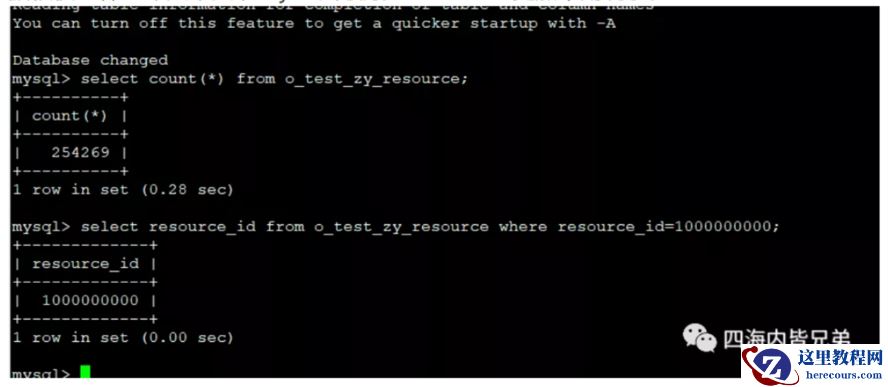
这个是MySQL的20多万count一下和查一条。可见全部count0.28秒,找一条更加不在话下应该是1ms的。
将这个表用OGG送到HDFS,hadoop的文件系统,用Hive来试试。HIve本来就是读磁盘文件。(其实这种MapReduce而且每次和磁盘交互的方式,而且HDFS还不支持修改。简直是智障。)
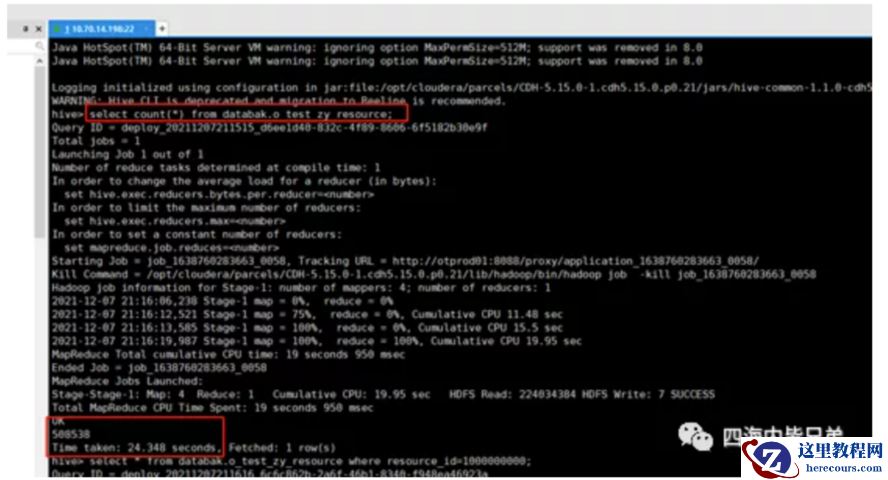 好吧Hive中count一下24秒这里之所以是50多万,是因为源库中update全表。而hive不支持修改,全过来。数据量翻了一倍,时间用了100倍。
好吧Hive中count一下24秒这里之所以是50多万,是因为源库中update全表。而hive不支持修改,全过来。数据量翻了一倍,时间用了100倍。
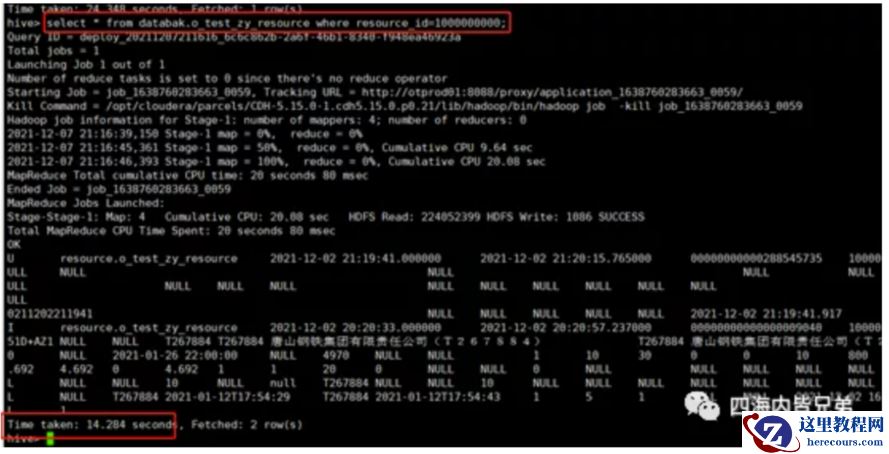
查其中一条用了14秒。慢了10000倍。
那么为什么还有大数据系统?主要是hadoop里面要是用hive去玩基本搞不动,一般都是impala去做的。区别是impala把hive的全部映射到内存中(再也没有智障的IO交互了)。然后全是内存在抗,又有多个机器,内存就变成可扩展的了。代价是N台强大的机器靠内存搞定。
不过各位看官看看,在百万级别的单表MySQL也就是秒出。妥妥满足要求,多表关联MySQL不擅长。但是Oracle 擅长啊。而且这里有一个非常重要的环节是无法回避的。就是从RDBMS(Oracle/MySQL/PostgreSQL/SQLServer/DB2)这些数据库做的修改和删除,大数据系统天生无法做到实时,而且对应Update和Delete的处理是非常繁琐,以至于在我个人看来,有这个时间和精力我不如把OLTP上的东西做做好,将OLTP做成HATP。一般的业务系统这样做还是做得到的。
千万不要以为报表天生就应该慢,我工作过的第二个公司,一天出一个报表一个报表15个小时。开发无法忍受找到我,只求一个小时完成。最后我处理后6秒出报表。所以报表不是就是慢,关系型数据库不见得慢,hadoop也不见得快(事实上就是慢)。成见是一座大山。












