一、索引原理
索引是提高数据库查询性能的一个重要方法。
使用索引用可快速找出某个列中包含特定值的行。不使用索引,必须从第一条记录开始读,可能要读完整个表,才能找出相关的行。
使用索引就像查字典一样,我们可以根据拼音、笔画、偏旁部首等排序的目录(索引),快速查找到需要的字。
之前介绍MySQL存储引擎的文章( 聊一聊MySQL的存储引擎),测试对比了两种存储引擎(MyISAM或者InnoDB),使用主键索引查询,效率快了几十倍。
虽然索引大大提高了查询(select)速度,但同时也会降低更新(insert,update,delete)表的速度,因为更新表时,数据库不仅要更新和保存数据,还要更新和保存索引文件。当然索引文件也占用存储空间。
二、索引失效的场景
索引虽然加快了查询效率,但使用方法不当,就会出现索引失效。
下面实际操作,列举一些索引失效的场景。
CREATETABLE
customer(
id
INTAUTO_INCREMENT,
companyVARCHAR(30),
nameVARCHAR(30),
sex
enum('male','female'),
age
INT,
phoneVARCHAR(30),
addressVARCHAR(60),
PRIMARYKEY
(id));
CREATEINDEX
index_company ON customer(company);
CREATEINDEX
index_age ON customer(age);
CREATEINDEX
index_phone ON customer(phone);
CREATEINDEX
index_phone_name ON customer(phone,name);
上面创建了一个客户表,以及三个单列索引和一个组合索引,我们来查看一下索引:

6 rows inset (0.01 sec)
上面显示包括一个默认的主键索引,还有三个单列索引,两个组合索引项。其中主键索引为唯一(unique)索引,索引类别(Index_type)显示为BTREE,实际为B+树。
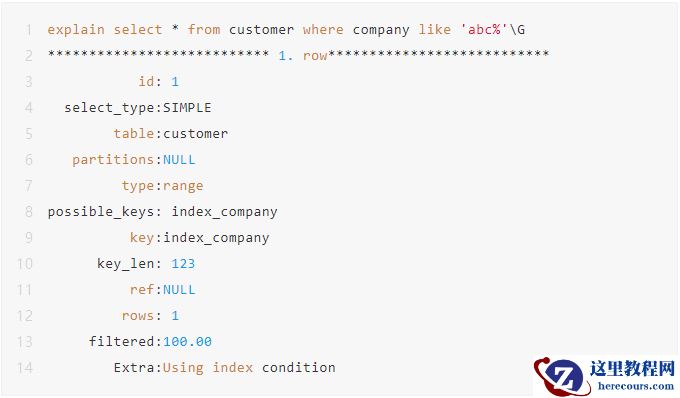
2.1 模糊匹配LIKE以 % 开头,会导致索引失效。

应该把模糊匹配放到最右边。
2.2 索引列进行计算,会导致索引失效。
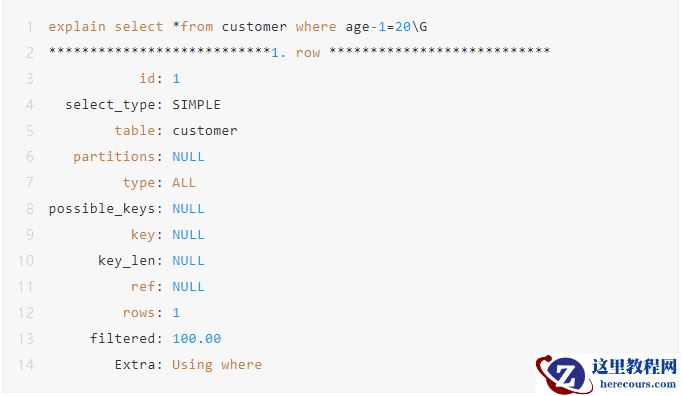
应该把运算放在右边。
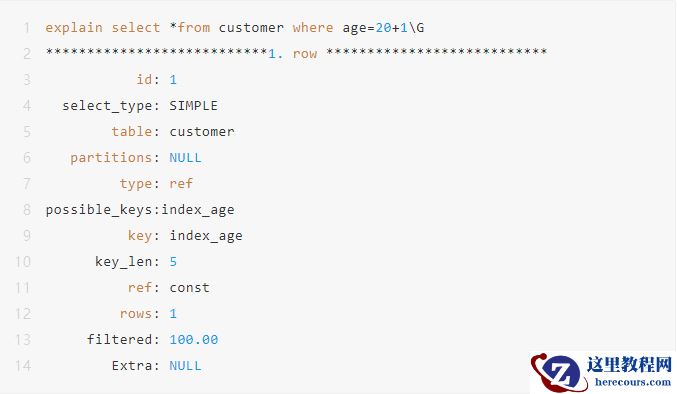
2.3 索引列使用函数,会导致索引失效。
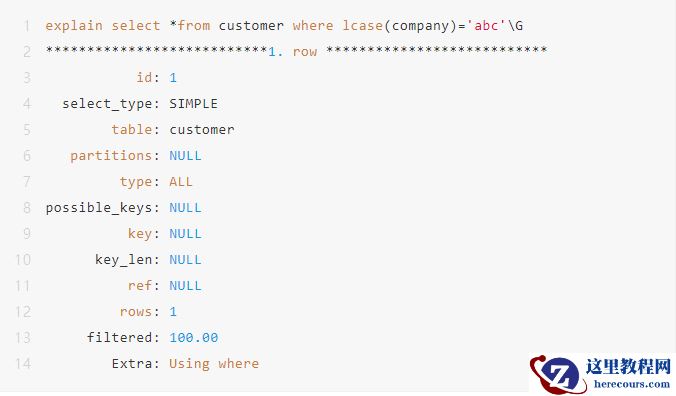
2.4 索引列类型转换,会导致索引失效。

应该保持原有类型,避免类型转换。
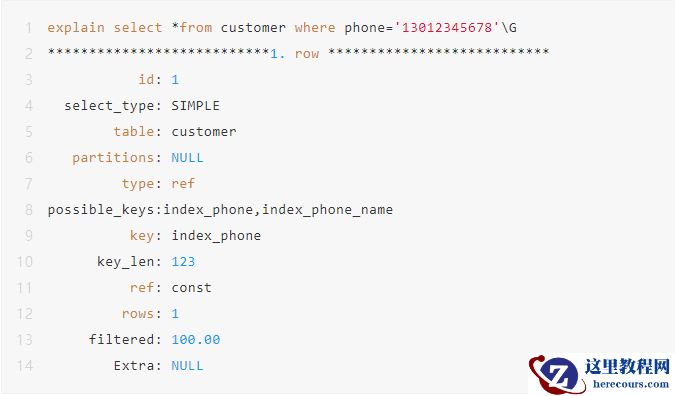
2.5 索引列比较字符集不一致时,会导致索引失效。
按照上面客户表的格式,创建两个供应商的表supplier、supplier_utf8,字符集分别为utf8mb4、utf8。 关于字符集可以看看之前文章( 聊一聊MySQL的字符集 )。




可以看到字符集一样的,一个表使用了索引,另一个表走了全表扫描。

字符集不一样的,两个表都走了全表扫描。
这种情况隐蔽性比较强,经常业务上线了才被发现。
2.6 使用 or 查询,不论另一项是否为索引列,都会导致索引失效。

不过如果非要使用 or进行查询,可以利用MRR功能,对回表查询进行排序优化。
2.7 组合索引,没有使用第一列索引,会导致索引失效。
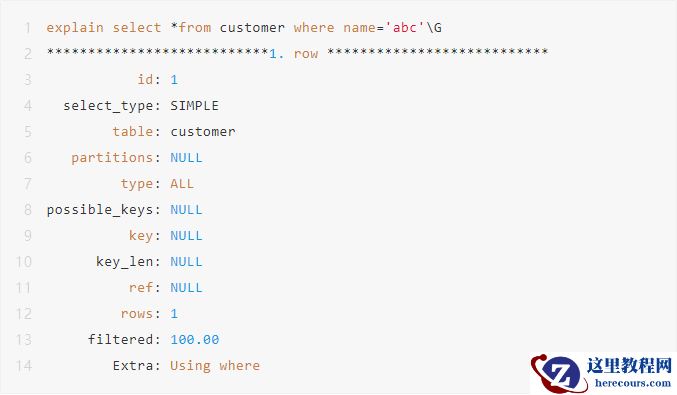
组合索引并不要求按照排列顺序,下面可以用到索引。
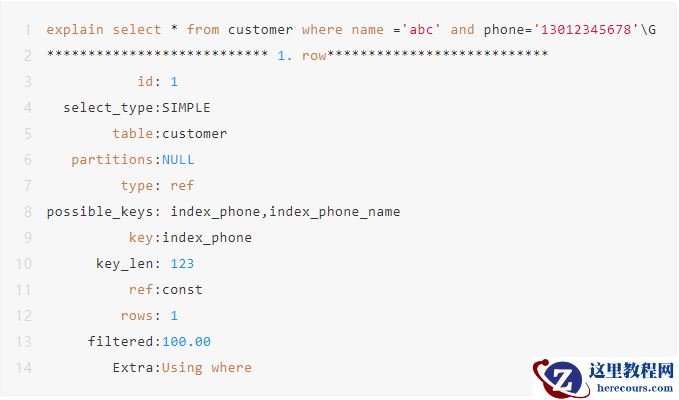
如果数据库预计使用全表扫描比使用索引快,则不使用索引。MySQL最新版本中,对索引判断有了很大改善,之前版本使用 in,!= ,<>,is null,is not null 会导致索引失效,最新版测试,还是使用了索引查询。
MySQL5.6引入了MRR(Multi-Range Read Optimization),专门来优化:二级索引的范围扫描并且需要回表的情况。
它的原理是,将多个需要回表的二级索引根据主键进行排序,然后一起回表,将原来的回表时进行的随机 I/O ,转变成顺序 I/O ,降低查询过程中的 I/O 开销,同时减少缓冲池中数据页被替换的频次。
MySQL5.7引入了 Generated Column,如果确实需要对索引列进行计算等操作,可以采用虚拟列的方式来处理,比如创建客户表时增加对应的列,公司名称小写 lcase_company ,和实岁 full_age , 并建立索引。


之后直接对 Cenerated Column 进行查询,就相当于计算列用到了索引。
三、索引的使用规范
在使用索引的时候,不仅要注意避免索引失效,也要遵循一定的规范,以便高效的使用索引。
下面总结了一些规范建议, 可以用来参考,并非绝对真理 。
3.1 单表的索引数建议不超过5个,组合索引的字段原则上不超过3个。
3.2 尽量不要在较长字符串的字段上建立索引,可以设置索引字段前缀长度。
3.3 选择在查询过滤中使用率较高,如 where,orderby,group by 的列建立索引。
3.4 不要在区分度不高的列上建立索引,比如性别等,利用不了索引性能。
3.5 不要在经常更新的列上建立索引,数据更新也会更新索引,影响数据库性能。
3.6 建立组合索引时,区分度最高,或者查询频率最高的,放在最左侧。
3.7 合理利用覆盖索引来满足查询要求,避免回表查询,减少I/O开销。
3.8 删除不再使用、少使用、或者重复的索引,减少数据更新的开销。
3.9 利用explain来判断查询语句,是使用了索引,还是走了全表扫描。
KunlunDB项目已开源 【GitHub:】 https://github.com/zettadb 【Gitee:】 https://gitee.com/zettadb
END











