来源:MySQL学习
本文讨论的锁都是innodb 的行锁,不涉及譬如MDL LOCK/TABLE LOCK等锁,这也是最常见的。
一、LOCK SYSTEM的拆锁改进简述
在8.0种lock system和5.7显著的不同就是进行的锁的拆分,主要是分为2个方面
/** Number of page shards, and also number of table shards.
Must be a power of two */
static constexpr size_t SHARDS_COUNT = 512;
因此8.0在LOCK SYSTEM MUTEX热点锁竞争方面已经有了改进,因此在大批量加锁的情况下,本热点锁已经在实际环境中少见了。比如在5.7 我们大批量加锁的时候可能有如下: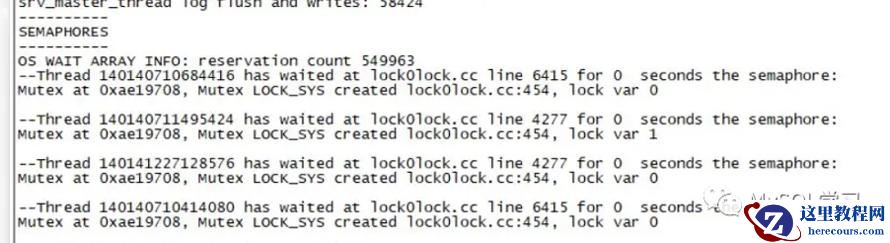
而在实际运维中8.0貌似还没见到过,这可能就得益于这里的拆分。
二、对行进行加锁
如果某个page已经包含了锁信息,通常会使用lock_rec_lock_slow函数进行加锁判定,
return (lock_strength_matrix[mode1][mode2] != 0)
static const byte lock_strength_matrix[5][5] = {
/** IS IX S X AI */
/* IS */ {TRUE, FALSE, FALSE, FALSE, FALSE},
/* IX */ {TRUE, TRUE, FALSE, FALSE, FALSE},
/* S */ {TRUE, FALSE, TRUE, FALSE, FALSE},
/* X */ {TRUE, TRUE, TRUE, TRUE, TRUE},
/* AI */ {FALSE, FALSE, FALSE, FALSE, TRUE}};
也就是通过兼容矩阵进行强度判定。当然这里判定的时候除了兼容矩阵强度判定还必须是当前事务的锁才行,因此如下:
lock->trx == trx
要满足这一条才是前提。并且这里从语法来讲有个完美转发右值引入的方式,尽量节省内存消耗。
实际上需要找到的是是否有事务持有锁,而堵塞了本事务需要获取的锁,那么也需要对LOCK SYSTEM的rec_hash进行迭代,同上面一样,也是通过Lock_iter::for_each进行的遍历,但是lambda函数不一样,这里主要调用的是lock_rec_has_to_wait函数进行判定,需要满足的条件主要是:
return (lock_compatibility_matrix[mode1][mode2]);
trx != lock2->trx
这里对于SQL线程持有的锁会设置为高优先级,这个会特殊处理,对于高优先级来讲当持有锁的trx释放后,会优先持有锁,这个在后面会看到。
经过这个过程就能找到本次加锁需要等待的锁资源是哪个。
先是需要新建一个RecLock的辅助结构,主要是线程结构、事务结构、锁模式、索引名称、page no/heap no作为构造参数。然后调用rec_lock.add_to_waitq,先将锁模式设置为 LOCK_WAIT,如下:
bool wait = m_mode & LOCK_WAIT
然后创建lock_t结构并且为其分配内存,在分配内存的时候,innodb有一个rec_pool的概念,在初始化的时候就已经初始化了REC_LOCK_CACHE(8)个lock_t结构,如果加锁不多那么分配内存这一块就直接从rec_pool中拿,否则需要实际分配内存,其构造主要是输入的space/page no/heap no/锁模型等信息,主要最后会调用lock_rec_set_nth_bit来设置lock_t结构的bit位,并且lock->trx->lock.n_rec_locks这个信息+1,这个信息是我们show engine看到的锁数量的信息。接着需要做的就是将建立好的lock_t结构放入响应的链表或者属性中,调用的是RecLock::lock_add,这是我们如下
上面将本次等待锁的信息建立好了,并且放入了响应的链表或者属性中,接下来就是要设置本事务的等待事务,这个主要用于进行解锁或者死锁监控会用到,调用的函数为lock_create_wait_for_edge,其中就是将本事务的lock.blocking_trx设置为堵塞者的事务id,同时这个信息也是打印堵塞源头的信息。
接下来要设置本事务本锁的相关信息,调用RecLock::set_wait_state,比如如下,
innodb_trx中的trx_wait_started和事务状态就来自这里,show engine 里面的事务状态也是这个。
接下来一个简单的函数 que_thr_stop(m_thr),这个函数主要是如果处于等待啊状态TRX_QUE_LOCK_WAIT,则设置线程属性QUE_THR_LOCK_WAIT,一旦设置为这个属性就会获取一个LOCK_SYSTEM的slot(srv_slot_t),然后根据slot的event进行等待和唤醒,这个在lock monitor监控线程再详细描述。
然后就是返回DB_LOCK_WAIT给上层,最后会通过状态QUE_THR_LOCK_WAIT将本线程堵塞,并且等待lock monitor监控线程的唤醒。
这里还需要注意一点,对于SQL线程的判定有额外的流程,也就是thd_report_row_lock_wait函数调入,可以看到SQL线程的锁有更改的优先级。
这里需要注意的是,并不一定一定要新建lock_t结构,如果本事务已经有了相关的lock_t结构,则设置一个bit位就可以了,判定的标准如下,(函数lock_rec_find_similar_on_page):
但是这里好像只是获取了LOCK SYSTEM的rec_hash响应链表(cell)的第一个lock_t结构,并没有全部获取如下:
first_lock = lock_rec_get_first_on_page(hash, block)
当然如果上面的条件不成立就需要调用RecLock::create,新建lock_t结构,并且调用如下:
三、总结
这里我们看到如下:
下一篇我们来分析一下lock monitor线程的超时唤醒方式,然后再来看lock monitor线程的死锁检测方式。
四、代码流程
lock_rec_lock_slow
locksys::owns_page_shard(block->get_page_id())
注意这个锁,对lock_sys mutex的优化
->lock_rec_has_expl(checked_mode, block, heap_no, trx);
该session 是否已经包含了 本模式的或者更强模式的锁
如果是则不需要锁判断了
->lock_rec_other_has_conflicting,本函数返回是否有需要等待的锁
进行锁冲突判定,如果返回找到的锁wait_for,就是拥有更强锁
->RecID rec_id{block, heap_no}
通过block和heapno构建rec id
->is_supremum = rec_id.is_supremum()
是否为sup伪列
->Lock_iter::for_each(rec_id, [=](const lock_t *lock) {return (!(lock_rec_has_to_wait(trx, mode, lock, is_supremum))
使用迭代,带入的为lambda函数,内部也就是循环比对
->hash_get_nth_cell(hash_table,hash_calc_hash(rec_id.m_fold, hash_table))
首先根据rec信息进行hash查找,在lock_sys的hash结构中进行查找,找到相应的链表
也就是lock_sys->rec_hash
->for (auto lock = first(list, rec_id); lock != nullptr; lock = advance(rec_id, lock))
遍历链表信息,每个信息是一个lock_rec_t结构
->!std::forward<F>(f)(lock) 完美转发,右值引用
回调 lambda函数,进去= 值捕获
->lock_rec_has_to_wait
->is_hp = trx_is_high_priority(trx)
sql线程拥有更高的优先级
->lock_mode_compatible
进行锁强度判定,特殊情况为如果线程优先级更高则忽略
及lock_compatibility_matrix兼容性矩阵
->进行额外的判定
如果返回为true则表明有其他事务的锁需要等待,如果为false
则不需要等待
如果需要等待,则 return (lock),返回等待的lock
->(wait_for != nullptr)
如果等待的锁不为空,这里注意几个属性SKIP LOCKED / NOWAIT是语句设置的时候的属性
这里会进行锁的判定,这里跳过SELECT_SKIP_LOCKED/SELECT_NOWAIT
->SELECT_ORDINARY
->RecLock rec_lock(thr, index, block, heap_no, mode)
新建一个RecLock结构,lock rec的内存结构,调用的为其构造函数
m_thr(thr),m_trx(thr_get_trx(thr)),m_mode(mode),m_index(index),m_rec_id(rec_id)
->trx_mutex_enter(trx)
上事务结构锁
Mutex protecting the fields `state` and `lock`
->rec_lock.add_to_waitq(wait_for) RecLock::add_to_waitq
输入参数为需要等待的lock_t结构
->m_mode |= LOCK_WAIT
首先将锁设置为LOCK_WAIT
->prepare()
RecLock::prepare
做简单检查先不考虑
->lock_t *lock = create(m_trx, prdt)
进行创建lock_t结构,调用RecLock::create
->lock_alloc(trx, m_index, m_mode, m_rec_id, m_size)
RecLock::lock_alloc,这里可以看到输入的信息都是
已经通过前面获取的信息比如锁模型,当前事务结构,space/page no/heap no等等
->(trx->lock.rec_cached >= trx->lock.rec_pool.size() ||sizeof(*lock) + size > REC_LOCK_SIZE)
如果((gdb) p trx->lock.rec_pool.size() $2 = 8)加锁的lock_t结构数量大于了8个就需要分配内存了
否则直接从pool里面拿,系统预先分配了REC_LOCK_CACHE的lock_t结构内存,就是8个。
->lock->trx = trx/lock->index = index/lock->type_mode = LOCK_REC | (mode & ~LOCK_TYPE_MASK)
/memset(&lock[1], 0x0, size)/ rec_lock.page_id = rec_id.get_page_id()
/lock_rec_set_nth_bit(lock, rec_id.m_heap_no)
设置相关信息,将锁的信息进行记录,并且lock->trx->lock.n_rec_locks.fetch_add +1
最后返回这个lock_t结构相关的变量
->RecLock::lock_add
将这个lock_t结构放入到hash结构中
->bool wait = m_mode & LOCK_WAIT;
是否处于等待状态
->lock->index->table->n_rec_locks.fetch_add(1, std::memory_order_relaxed);
增加锁定的行数 +1
->if (!wait)
是否处于等待状态,如果不是
lock_rec_insert_to_granted(lock_hash, lock, m_rec_id)
->首先获取cell,使用头插法插入到链表的头部
否则
lock_rec_insert_to_waiting(lock_hash, lock, m_rec_id)
->直接插入到响应cell的尾部
->locksys::add_to_trx_locks(lock)
->UT_LIST_ADD_LAST(lock->trx->lock.trx_locks, lock)
将锁结构加入到事务的trx_lock_t中
->lock->trx->lock.trx_locks_version++
locks版本+1
->if (wait)
->lock_set_lock_and_trx_wait
->trx->lock.wait_lock = lock; //写入
->trx->lock.wait_lock_type = lock_get_type_low(lock);
如果是处于等待状态,则将这个锁放入到事务的trx_lock_t->wait_lock中
->lock_create_wait_for_edge
输入参数为当前事务的trx(waiter)和等待的trx(被堵塞blocker)
waiter->lock.blocking_trx.store(blocker)
记录当前等待的事务的堵塞源头事务,存储一条边,记录了堵塞者
->RecLock::set_wait_state
m_trx->lock.wait_started = ut_time();
m_trx->lock.que_state = TRX_QUE_LOCK_WAIT;
m_trx->lock.was_chosen_as_deadlock_victim = false;
以上设置事务lock的状态,show engine中事务的状态就是它
case TRX_QUE_LOCK_WAIT:fputs("LOCK WAIT ", f);break;
并且innodb_trx中的状态也会根据其进行判定,fill_trx_row->trx_get_que_state_str
也是一样的状态
同时innodb_trx中的trx_wait_started也是来自这里,如果等待了就设置为时间,没有等待则为NULL
stopped = que_thr_stop(m_thr)
用于返回用于加锁等待的 判定QUE_THR_LOCK_WAIT
->thd_report_row_lock_wait
使用当前线程和需要等待的线程,如果是SQL线程则需要根据seqnumber进行死锁判定
if (self != nullptr && wait_for != nullptr && is_mts_worker(self) &&is_mts_worker(wait_for))
->Commit_order_manager::check_and_report_deadlock(self, wait_for);
if (mngr != nullptr && self_w->c_rli == wait_for_w->c_rli &&wait_for_w->sequence_number() > self_w->sequence_number())
这里根据sequence_number进行判定
->Commit_order_manager::report_deadlock
在研究
->return (DB_LOCK_WAIT)
返回状态DB_LOCK_WAIT
->trx_mutex_exit(trx);
进行解锁,也就是上面的过程是在trx_t的mutex下进行的
->返回堵塞状态DB_LOCK_WAIT
以上是堵塞的流程
->如果没有堵塞则
->lock_rec_add_to_queue
-> type_mode |= LOCK_REC;
-> if (!(type_mode & LOCK_WAIT))
如果不处于等待状态,因为lock_rec_add_to_queue函数并不是只有
这里才会调用,调用的地方还很多,这里看起来不会处于LOCK_WAIT
状态
->lock_hash_get(type_mode)/lock_rec_get_first_on_page(hash, block)
通过lock_system hash结构找到相关的第一个lock_t结构
->lock_rec_find_similar_on_page
主要是通过对hash的链表进行for循环,看本事务是否已经有合适的lock_t结构了,如果有则只需要设置响应的bit位就可以了。主要比对的方式
1、事务是同一个
2、锁模式相同
3、并且此lock_t的bit结构能够容纳下
->lock_rec_set_nth_bit(lock, heap_no)
如果找到就进行bit位设置
->否则就需要新建新建lock_t结构,并且调用的也是RecLock::create
并且加锁trx_mutex_enter(trx),当然也包含了加入到lock_system
hash结构中,流程如上,不在详细描述。



:加锁流程")






