前言
当下,只要是一个初具规模的内容应用都具备个性化推荐系统。比如购物类的会有推荐商品模块,搜索条下有个性化的搜索关键词或词条补全词,社交类的有博主推荐,视频或文章推荐等等。这些功能除了要有庞大的数据量,还要有健全的数据存储仓库建设方案,以及后面对数据的清洗,排序,训练后的推荐模型算法。
但是,对于小公司或者说是小项目,在想法还未真正落地就设计大数据存储,推荐算法和一系列大型架构的方案,显然是不符合业务型产品开展的正常规律的。我想那些大厂早期开发应该也没有这么成熟的技术结构,都是不断迭代或者推倒重来一步步走过来的。
那么,在小项目早期安排了有关于推荐功能的那要如何解决呢? 如何做到下一次迭代在不重构的基础上添加协同过滤推荐? 下面就从视频推荐和用户推荐两个功能展开,用PHP和MySQL进行代码实现。

视频推荐
这里主要通过一个内容热度值进行排序推荐,热度由内容质量和发布时间差决定,时差越长,热度越低,内容质量越高热度越高。而内容质量由视频点赞数,收藏数和评论数外带权重决定,总体就是单位时间内点赞,收藏,评论越高,热度提升,视频就越往前靠。相对的就是发布时间越久,热度就会逐步降低,视频越往后靠。
另外我们还要设计两个参数用于手动调节视频的热度,提高就只需要增加内容质量,所以额外加一个数可以说是初始值。降低可以对时间差添加一个指数,也就是时间差的次方,可以理解是重力,也就是随着时间拉长,重力增加则热度成倍降低。
1. 公式
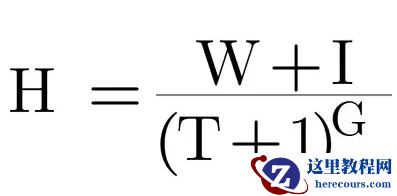
1.1. ”H“:视频热度值
1.2. ”W“:视频质量,质量值自定(点赞数*权重,收藏数*权重之和,或者点赞率(点赞量/阅读量),收藏率(收藏量/阅读量)之和)等。
1.3. ”I“:初始值,可以手动调节热度或者用于后期用户账号的权重。比如系统已经有了成长体系,账号发育规则基本完善了,用于实时计算账号的权重分配的流量池,权重提升,则后面发布的视频推荐力度大。
1.4. ”T“:时间差,由当前时间 - 发布时间产生,加一的原因是防止时间差为0(分母为零),不过有审核机制下,这种情况并不存在。
1.5. ”G":热度衰减重力,这个也是用于手动调节热度设置的控制参数。不过后期如果添加了举报或者智能复审等环节,再随着诸如点赞和账户权重评估失控热度飙升的情况下,对视频违规或不良表现或临时情况进行减小推荐。默认值最好是1,这种情况就是在同等质量下新发布的越往前。
2. 表结构
CREATE TABLE `hhyp_short_video` ( `id` int(11) NOT NULL AUTO_INCREMENT, `hsvn` varchar(255) DEFAULT '' COMMENT '短视频编号', `type` tinyint(1) DEFAULT '0' COMMENT '类型:1. 视频 2.图文', `user_id` int(11) DEFAULT '0', `video_url` varchar(255) DEFAULT '', `img_url` json DEFAULT NULL, `content` text COMMENT '内容', `market_goods_id` int(11) DEFAULT '0', `address_id` int(11) DEFAULT '0' COMMENT '地址ID', `lat` decimal(4,0) DEFAULT '0' COMMENT '纬度', `lng` decimal(4,0) DEFAULT '0' COMMENT '经度', `ip` varchar(100) CHARACTER SET utf8 DEFAULT '' COMMENT 'IP', `channel` tinyint(1) DEFAULT '0' COMMENT '渠道', `read_count` int(11) DEFAULT '0' COMMENT '浏览数', `like_count` int(11) DEFAULT '0' COMMENT '点赞数', `collect_count` int(11) DEFAULT '0' COMMENT '收藏数', `comment_count` int(11) DEFAULT '0' COMMENT '评论数', `share_count` int(11) DEFAULT '0' COMMENT '分享数', `is_top` tinyint(1) DEFAULT '0' COMMENT '是否置顶:0.否 1.是', `status` int(11) DEFAULT '0' COMMENT '0. 审核中 10. 推荐 20. 下架', `hot_int` int(11) DEFAULT '1' COMMENT '热度初始值', `gravity` int(11) DEFAULT '1' COMMENT '热度重力衰减值', `audit_time` int(11) DEFAULT '0' COMMENT '审核时间', `remark` text, `create_time` int(11) DEFAULT '0' COMMENT '创建时间', `delete_time` int(11) DEFAULT '0', `update_time` int(11) DEFAULT '0', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=107 DEFAULT CHARSET=utf8mb4;

3. 代码
public static function getList($map, $page = 1, $size = 20) { // 数据指标权重配置
$wcfg = [ 'like_weight' => 4, 'collect_weight' => 3, 'comment_weight' => 1
]; $timeUnit = 3600; // 单位小时
$where[] = ['delete_time', '=', 0]; $map = array_merge($where, $map); // 单位小时内,点赞/收藏/评论越多热度越高,发布越久热度越低
$alog = "(like_count*%s+collect_count*%s+comment_count*%s+hot_int)/pow((UNIX_TIMESTAMP(NOW())-create_time)/%s, gravity)"; $hotIndex = sprintf($alog, $wcfg['like_weight'], $wcfg['collect_weight'], $wcfg['comment_weight'], $timeUnit); $field = ["id, hsvn,type,user_id,video_url,img_url,content,market_goods_id,
like_count,collect_count,address_id,comment_count,share_count,create_time, $hotIndex as hot_index"]; $list = self::field($field)
->json(['img_url'], true)
->with([ 'user' => function ($query) { $query->withField('id, nickname, mobile, avatar');
}, 'marketGoods' => function ($query) { $query->withField('id, content,freight,user_id');
}, 'address' => function ($query) { $query->withField('id, mername');
}
])
->where($map)
->page($page, $size)
->order("hot_index desc")
->select(); return $list;
}

推荐用户,大部分是放在App里的个人中心感兴趣用户模块。有的是给用户推荐授权的通讯录好友,有的是根据行为数据,通过给用户打标签,再推荐与自己标签相似的用户等等方式。而我这里的用户推荐是放在发布视频的用户面板里,本来我想通过协同过滤的相似用户来做,由于数据太有限,加之我们业务本身就不能查看用户关注列表和粉丝列表,所以就暂时用了一个折中的方法,给用户推荐创作者关注的关注。
根据当前面板用户关注的用户里挑出粉丝数最多的前十个,然后再从这十个里分别挑出他们关注用户里粉丝最多的前十,最后合并去重,也就是给自己推荐打开用户关注的关注里粉丝最多的那批人。
1. 表结构
CREATE TABLE `hhyp_user_attention` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) NOT NULL DEFAULT '0' COMMENT '用户id', `comcemed_user_id` int(11) NOT NULL DEFAULT '0' COMMENT '关注的用户id', `create_time` int(11) DEFAULT '0' COMMENT '创建时间', `status` smallint(3) NOT NULL DEFAULT '0' COMMENT '关注状态 0未关注 1已关注', `update_time` int(11) DEFAULT '0' COMMENT '更新时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=352 DEFAULT CHARSET=utf8mb4;
2. 代码
通过查询子查询里指定用户里粉丝最多的前十人(分组排序),然后递归往前查询就形成关注链条,最后再合并查询结果。其实这个也很看数据的,当我真正把这个方法放上去的时候,会发现很多面板里没有用户推荐的数据,因为很多用户根据就没关注几个人。所以通过深度学习或者协同过滤做用户推荐可能要等待一段时间,等用户行为数据产生差不多的时候,我再出一下协同过滤的用户相似度推荐吧。
// 关注链列表
public static function grandadList($userIds = [], &$allList = [], &$level = 1) { $field = ["comcemed_user_id, count(*) as fans_count, {$level} as level"]; $list = self::field($field)
->where('comcemed_user_id', 'in', function ($query) use ($userIds) { $query->table('hhyp_user_attention')
->where('user_id', 'in', $userIds)
->where('status', '=', 1)
->field('comcemed_user_id');
})
->where('status', '=', 1)
->group('comcemed_user_id')
->order('fans_count desc')
->limit(10)
->select()
->toArray(); if ($list && $level < 4) { $level++; $comcemedUserIds = array_column($list, 'comcemed_user_id'); $list = self::grandadList($comcemedUserIds, $list, $level);
} $list = array_merge($allList, $list); return $list;
}

编辑推荐:
- 关于项目初期,数据量小的内容推荐的实现方法03-01
- 图解MySQL Undo log的存储机制及工作原理,3分钟精通!03-01
- 为什么需要插入意向锁?03-01
- 是时候了!MySQL 5.7 的下一站,不如试试 TiDB?03-01
- MySQL不会丢失数据的秘密,就藏在它的 7种日志里03-01
- MySQL:每次update一定会修改数据吗?03-01
- 什么是数据库的索引?03-01
- 缓存数据一致性探究03-01
相关推荐
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-

雷神推出 MIX PRO II 迷你主机:基于 Ultra 200H,玻璃上盖 + ARGB 灯效
2 月 9 日消息,雷神 (THUNDEROBOT) 现已宣布推出基于英
-

制造商 Musnap 推出彩色墨水屏电纸书 Ocean C:支持手写笔、第三方安卓应用
2 月 10 日消息,制造商 Musnap 现已在海外推出一款 Oce
热文推荐
- 关于项目初期,数据量小的内容推荐的实现方法

关于项目初期,数据量小的内容推荐的实现方法
26-03-01 - 图解MySQL Undo log的存储机制及工作原理,3分钟精通!

图解MySQL Undo log的存储机制及工作原理,3分钟精通!
26-03-01 - 为什么需要插入意向锁?

为什么需要插入意向锁?
26-03-01 - 是时候了!MySQL 5.7 的下一站,不如试试 TiDB?
是时候了!MySQL 5.7 的下一站,不如试试 TiDB?
26-03-01 - MySQL不会丢失数据的秘密,就藏在它的 7种日志里

MySQL不会丢失数据的秘密,就藏在它的 7种日志里
26-03-01 - MySQL:每次update一定会修改数据吗?

MySQL:每次update一定会修改数据吗?
26-03-01 - 什么是数据库的索引?

什么是数据库的索引?
26-03-01 - 缓存数据一致性探究

缓存数据一致性探究
26-03-01 - 【Seata源码领读】揭秘 @GlobalLock 隔离保障的微妙之处

【Seata源码领读】揭秘 @GlobalLock 隔离保障的微妙之处
26-03-01 - 数据库信息速递 10年的数据库使用习惯变革,数据库的使用习惯在被改变 (译)
")