来源:MySQL数据库联盟
这篇文章+执行计划,都掌握的话,我们可以优化80%的SQL了。
use martin; /* 使用martin这个database */drop table if exists index_test_04; /* 如果表index_test_04存在则删除表index_test_04 */CREATE TABLE `index_test_04` (`id` int NOT NULL AUTO_INCREMENT,`a` int DEFAULT NULL,`b` int DEFAULT NULL,`c` int DEFAULT NULL,`d` int DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_a` (`a`),KEY `idx_b_c` (`b`,`c`)) ENGINE=InnoDB CHARSET=utf8mb4;drop procedure if exists insert_index_test_04; /* 如果存在存储过程insert_index_test_04,则删除 */delimiter ;;create procedure insert_index_test_04() /* 创建存储过程insert_index_test_04 */begindeclare i int; /* 声明变量i */set i=1; /* 设置i的初始值为1 */while(i<=100000)do /* 对满足i<=100000的值进行while循环 */insert into index_test_04(a,b,c,d) values(i,i,i,i); /* 写入表index_test_04中a、b两个字段,值都为i当前的值 */set i=i+1; /* 将i加1 */end while;end;;delimiter ; /* 创建批量写入100000条数据到表index_test_04的存储过程insert_index_test_04 */call insert_index_test_04(); /* 运行存储过程insert_index_test_04 */insert into index_test_04(a,b,c,d) select a,b,c,d from index_test_04;insert into index_test_04(a,b,c,d) select a,b,c,d from index_test_04;/* 把index_test_04的数据量扩大到40万 */create table index_test_05 like index_test_04;insert into index_test_05 select * from index_test_04;
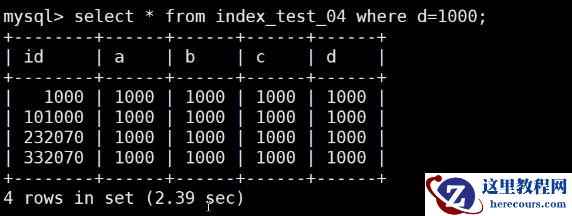
select * from index_test_04 where d = 1000;
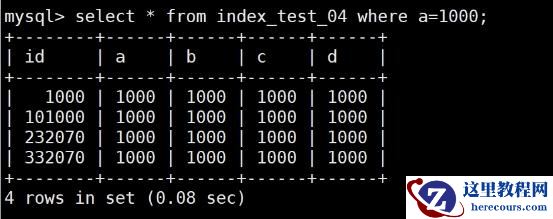
select * from index_test_04 where a = 1000;
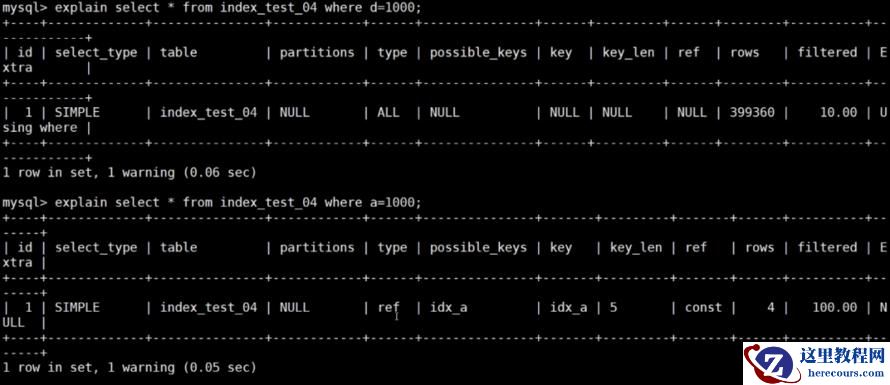
explain select * from index_test_04 where d = 1000;explain select * from index_test_04 where a = 1000;
select max(d) from index_test_04;
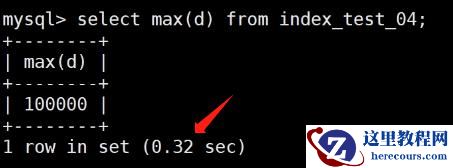
select max(a) from index_test_04;
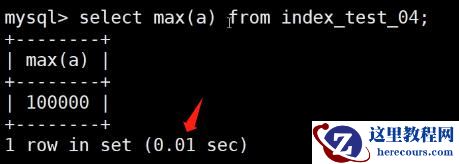
select count(*) from index_test_04;
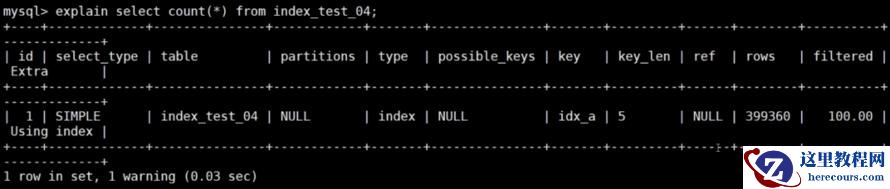
explain select count(*) from index_test_04;
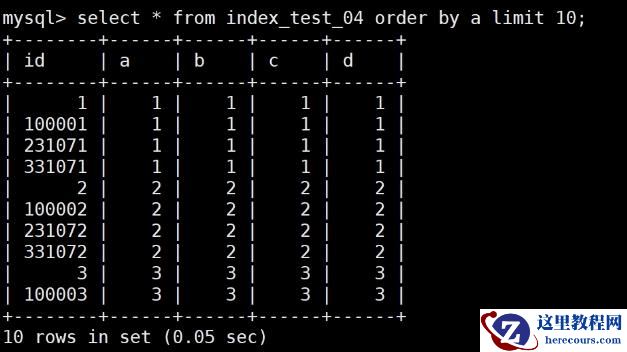
select * from index_test_04 order by a limit 10 ;
select * from index_test_04 order by d limit 10 ;
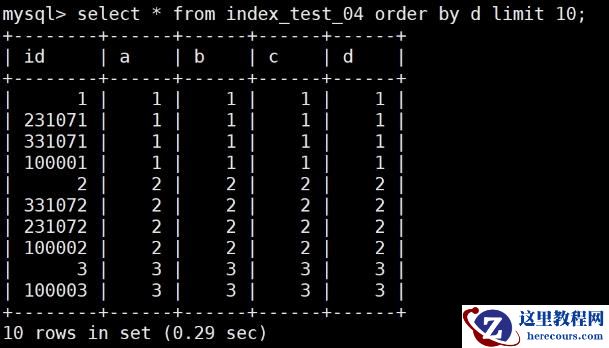
explain select * from index_test_04 order by a limit 10;explain select * from index_test_04 order by d limit 10;
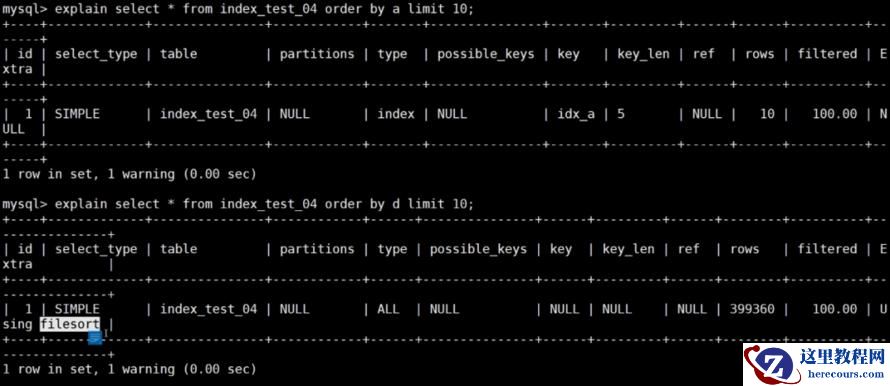
select * from index_test_04 order by b,c limit 10;
explain select * from index_test_04 order by b,c limit 10;
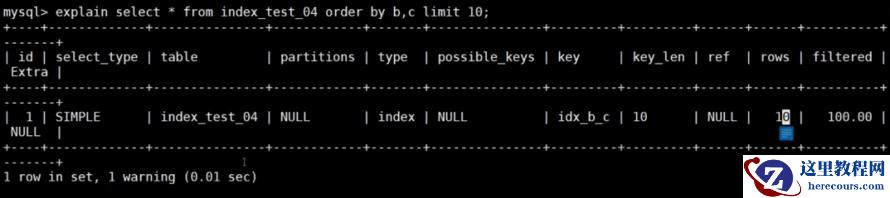
explain select a,d from index_test_04 where a=900;
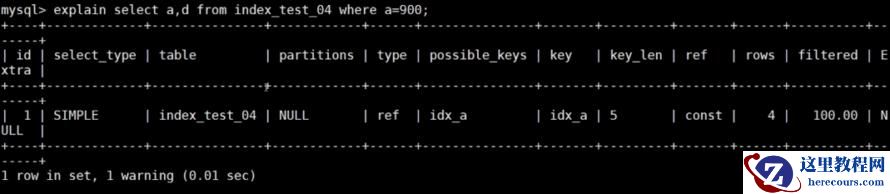
explain select b,c from index_test_04 where b=1000;
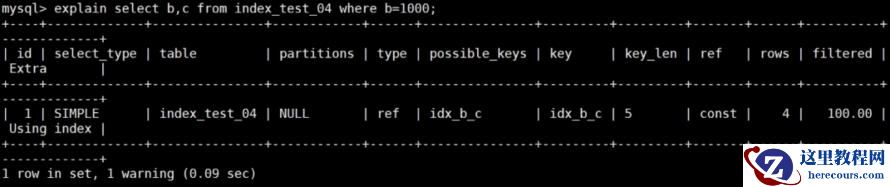
explain select * from index_test_04 tb1 inner join index_test_05 tb2 on tb1.a = tb2.a;
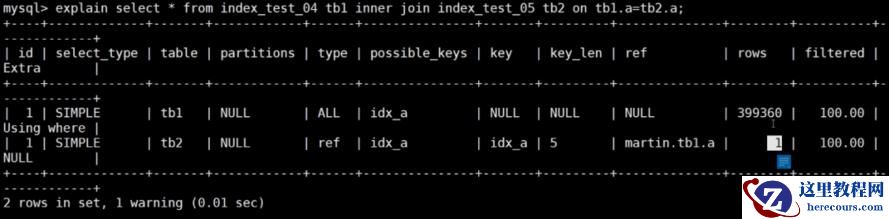
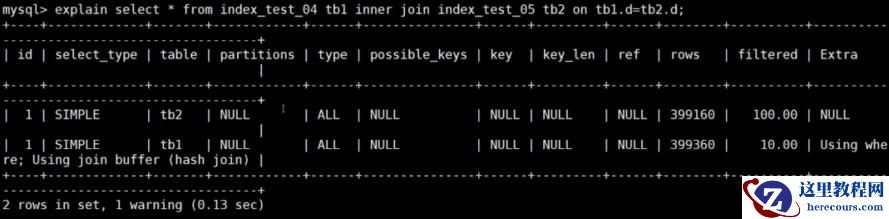
explain select * from index_test_04 tb1 inner join index_test_05 tb2 on tb1.d = tb2.d;