来源:安瑞哥是码农
这段时间一直在探寻,有哪可以方便、快捷、优雅地导出mysql,或者相关的常用SQL数据库数据的手段和方法。
从最近调研和测试的几篇文章中可以看出来,我已经测试过以下这些数据导入手段:
1. 数据库的外部表+物化视图:当时测试对象是从mysql导数据到Clickhouse,经验证,不靠谱;
2. DataX:能满足读取需要,但是默认只能读取mysql全量的历史数据,想要读取增量数据,必须要根据字段进行条件筛选,以批处理方式多次启动来满足,使用会相对比较麻烦;
3. Flink CDC:目前为止,最省事的mysql数据导入方案(前提是已经具备Flink开发环境),能很好的满足历史数据+增量(变化)数据的捕获,缺点就是支持的数据库种类还不够多,且对版本都有要求;
4. Spark JDBC 和 Flink JDBC:跟DataX的数据读取原理一样,更适合一次性读取历史全量数据,且都只能以「批处理」方式来进行,对于增量(变化)数据的获取,有很大的局限性(也是只能通过字段条件筛选)。
而今天呢,我在 flink 的官网里,偶然看到了 Maxwell ,说可以作为一种CDC 的数据格式被 Flink 识别和处理。
于是就想着,咦... 这个工具我好像还没用过,之前只是听说,要不今天就给大家测试一下看看,对比上面使用过的同步方案,Maxwell 这个货到底用起来怎么样?
(PS:用完一圈后发现,Maxwell这个小东西想玩好,没有想象的那么容易。)
0. 看官网
可能确实因为功能相对比较简单,所以Maxwell的官方文档跟Flink,Spark这样的大组件相比,就显得简洁很多。
从官网的描述来看,Maxwell是一款专门针对mysql变化数据捕获的CDC工具,因为能识别和捕获的数据源单一,所以就注定了它只是一款相对小众、精致的数据传输工具。
虽然Maxwell只能读取mysql数据源,但是却可以将其读取后的数据写入到多个不同的目标存储中。

其中常见的有kafka、数据文件、Redis以及rabbitmq。
但如果想在项目中,支持相对纯粹的流式计算,kafka才是我们用得最多的数据输出(producer)方案。
1. 安装部署
官方提供了两种主流的部署方式,一个为 tar.gz 的压缩包,另一个为docker。
但为了更加方便搞清楚Maxwell的技术实现原理,观察其中的目录结构和配置文件,我决定通过用压缩包的方式来安装。
但这里比较坑爹的地方在于,这个安装包是放在GitHub上面的,所以如果没有梯子的话,下载起来会有点费劲。
费老半天劲下载下来后(我下载的最新版),解压查看目录结构长这样:
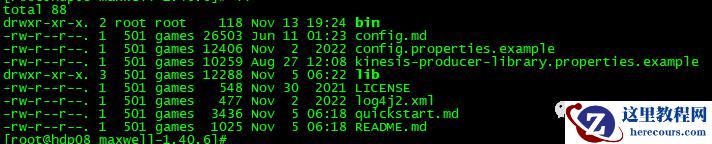
结构非常简单,每个配置文件我都打开瞅了一眼,如果你有一定的英文阅读基础,你会发现,就光看这几个配置,以及它给的注释,跟官网资料上的很多描述都是一样的。
为了进一步揭开Maxwell的神秘面纱,咱再来看看lib目录里都有啥,要知道,像这样的软件,它支持什么样的功能,以及能跟哪些版本的外部软进行通信,其实秘密全都隐藏在这个lib目录里。
既然官网说Maxwell只支持读mysql,但是支持哪个版本,它却并没有告诉我们,而这个秘密,我们只能通过lib目录下的jar包来揭晓。
通过搜索关键词「mysql」,可以搜索出如下的jar包:

也就是说,当前版本的Maxwell,应该可以确定支持到mysql8.0.28。
用同样的办法来查看我最关心的kafka版本(因为后续数据写kafka的场景一定是最多的):
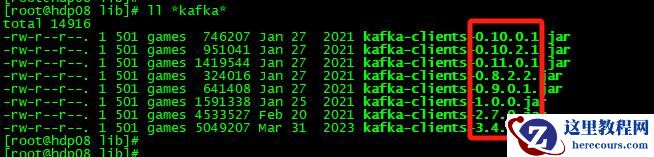
可以看到,kafka支持的版本就多了,从低版本的0.8开始,一直到最新的3.4,几乎全线覆盖。
2. 开始使用
根据官网的案例,或者解压后安装包里面的README文件,里面有比较详细的步骤来告诉你如何操作。
2.1 创建maxwell专有库
这里需要先创建一个专门的库名,然后maxwell导入程序在启动时,会在这个库下创建一些表,来保存maxwell在导数据时候,需要保存的一些必要信息,比如已经导入了哪些表,导入binlog的offset等等,目的是用来记录maxwell的数据导入状态。
注意:官网对这块的描述(或者说解释)是缺失的,很容易让第一次部署的人懵逼,还以为这个库就是mysql已经存在的,需要被导数据的目标库,容易让人误解。
所以严格来说,步骤应该如下:
create database maxwell;
CREATE USER 'maxwell'@'%' IDENTIFIED BY 'XXXXXX';
GRANT ALL ON maxwell.* TO 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
之后,该库会自动生成这些表(在第一次运行bin/maxwell命令之后):

PS:至于mysql的配置修改部分,因为我用的mysql8,binlog是默认开启的,其他默认配置也都符合要求,所以理论上不用做任何修改。
2.2 修改 maxwell 配置
从解压后的 Maxwell 安装包来看,它的目录结构非常简陋,甚至都没有专门的配置文件夹(比如conf目录):

如果不指定的话,maxwell进程会默认会读取图中框出来的这个文件名,但因为它本不存在,所以需要将那个带example后缀的配置文件,给复制一份出来。
而关于这个配置文件的内容,其实很多地方因为可以在maxwell导入程序的命令行中指定(比如host、用户名、密码之类),因此这里面绝大部分的配置可以不用动。

当然,如果你用来保存Maxwell元数据信息的库名也是这个的话(默认就是maxwell),其实连这里都不用改。
至此,maxwell 的准备工作就都做好了,接下来就可以启动一个导入任务看看,到底能不能顺利读到mysql的数据。
2.3 有个坑
根据官网的案例,开始启动一个最简单的maxwell任务,并将读取到的mysql数据输出到控制台:

一起动,就报出上面的错,原因很简单,因为我当前服务器用的Java8环境,而这个maxwell相关的包都是在Java11环境下编译的。
解决办法有两个:
第一:降低 maxwell 的版本,让其符合 Java8 环境;
第二:升级当前服务器环境的JDK到11以上。
为了方便,我选择了第二种,将服务器的JDK升级到JDK17,至此,这个问题消失。
2.4 正确的玩法
解决完上面这个问题后,继续运行那个命令,这回不报错了:

但是,你会发现这个输出啥玩意也没有呢,不像Flink CDC,会主动把当前表中的存量历史数据给同步出来。
关键具体怎么玩,官方文档我没有找到直接的提示信息,那就只能靠摸索,摸着摸着,我就发现了在bin目录下,有这么个命令:
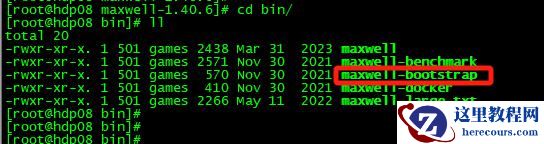
凭借我的经验,这个命令应该比较重要。
果然,在官网找到了我要的信息:
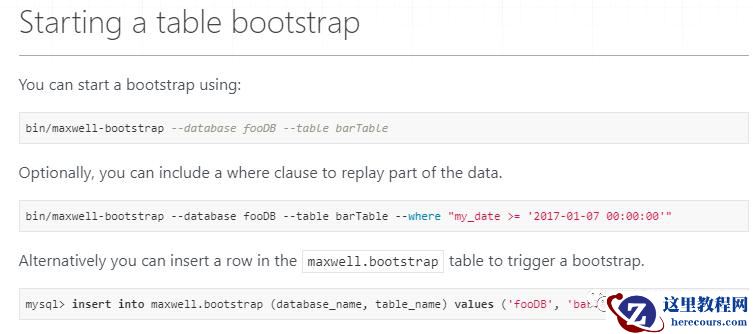
也就是说,想要用刚才那个命令读取某张表的数据,必须要通过这个命令来具体指定。
比如,我现在mysql的test库里,有张表test01,有如下数据:
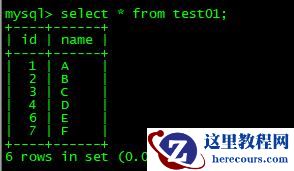
然后,我想要同步这种表,但是光启动刚在那个同步命令是不够的,还需要用这个bootstrap命令,来告诉Maxwell来具体同步谁。
于是,需要运行如下这个命令(该命令默认会同步整张表的历史数据,如果想通过条件筛选,可以加where子句):

接着,你就能看到刚那个阻塞住的控制台,输出如下内容:
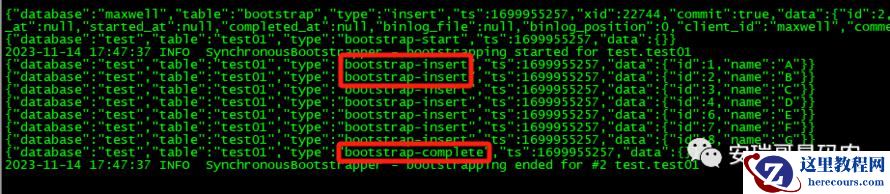
已经把test01这张表的历史数据全部读取了出来。
与此同时,对应的Maxwell元数据表bootstrap,也记录了当前的状态信息:

然后我继续分别用insert、update、delete操作几条数据:
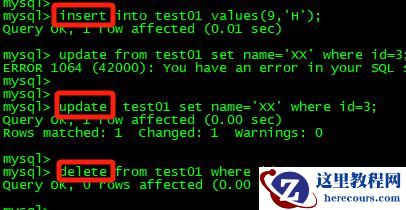
得到如下输出:

可以看到,跟Flink CDC不一样的是,Maxwell没有对delete的数据做对应的输出,只记录了insert和update。
此外,如果你现在停掉当前 Maxwell 的进程,然后再次启动,进程是不会读取历史数据的,只会捕获新增和变化的数据,不像Flink CDC 必须通过savepoint恢复才能做到。
随后,我也尝试了将 producer 从stdout改为kafka,也能顺利写入(没有坑,好评),毕竟它支持的 kafka 版本还挺多的。
最后
经过这么一番对 Maxwell 的调研和使用,基本上把它的核心功能摸了个八九不离十。
要说优点呢:软件本身比较小巧,不需要启动额外服务,使用起来也比较简单,通过启动一个阻塞式的命令就可以同步数据;
缺点呢:对JDK版本要求较高,且只能读取mysql数据源,输出端(producer)也支持的不够丰富,官方文档过于简洁,缺少一些必要的解释信息,有的地方会让初次阅读的人不明所以,容易懵逼。
至于它的使用场景:如果说你当前环境没有Flink,但有kafka,且同时又想能以流的方式获取mysql数据源的增量数据(mysql要支持binlog),那么Maxwell是适合的。
总之对它的评价是:小巧、小众、使用体验勉强凑合的一款数据同步工具。
对于Maxwell,你怎么看?







")


")
")
