来源:MySQL数据库联盟
讨论了一些MySQL相关的问题,这里就来总结一下,大家也可以一起在留言区讨论。
1 Xtrabackup是不是一直都用的ftwrl,有没有用到backup lock
先说答案:5.6+,是ftwrl(FLUSH TABLES WITH READ LOCK),8.0是LOCK INSTANCE FOR BACKUP
判断这类问题,有两个解决思路:
一个是查看官方文档:
https://docs.percona.com/percona-xtrabackup/8.0/how-xtrabackup-works.html
有下面截图这一段:

还有一个方法:
通过实验验证,备份过程开启general log,看会执行哪些命令。
2 Orch切换主从拓扑之后,为什么找不到复制用户?
Orchestrator切换,某个从库会报错:
Fatal error: Invalid (empty) username when attempting to connect to the master server. Connection attempt terminated
查了Github的issues,发现也有人遇到同样的问题
https://github.com/openark/orchestrator/issues/323
原因:
master_info_repository 没设置成 'TABLE'
解决办法:
master_info_repository设置成table
实际在Orch的文档中也提过:
https://github.com/openark/orchestrator/blob/master/docs/install.md
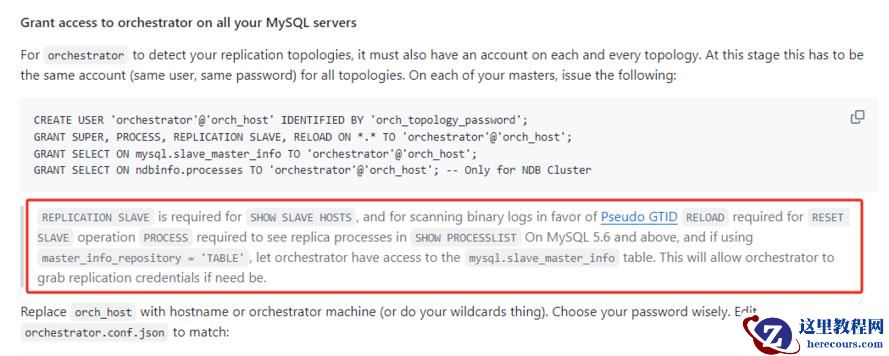
但也没说不配置成table问题的严重性。
大家在使用Orch的时候,需要注意这个细节。
3 获取慢查询有哪些方案
方案一:ELK
Elasticsearch, Logstash, and Kibana
方案二:PMM
这个方案可以跳转之前的一篇文章:
PMM 监控 MySQL。
方案三:ClickTail+ClickHouse+Grafana
这个方案可以跳转之前的两篇文章:
ClickTail+CH 实现 MySQL 慢查询实时展示
使用 Grafana 展示 ClickHouse 数据
4 线上有张表数据100多万,700多M,但是磁盘碎片有4个T,这种能直接drop掉吗 ?还是有什么方式可以删掉?
不能直接删除,要当成4T的表处理,给数据文件.ibd创建一个硬链接,这样drop就很快了。
过程为:
ln table_name.ibd table_name.ibd.bak
在drop表
最后再删除物理文件:
for i in `seq 4096 -1 1 ` ; do sleep 1; truncate -s ${i}G table_name.ibd.bak; done rm -f table_name.ibd.bak
当然,如果是云上RDS,就需要找云厂商,研究怎么安全的删除,毕竟我们不能操作机器。
5 MySQL binlog里面的时间,有些不是顺序的。一般在什么情况下发生?是因为主库并发执行的事务原因吗?
我做了一个这样的实验:

最终解析之后,就出现了下图这种情况:
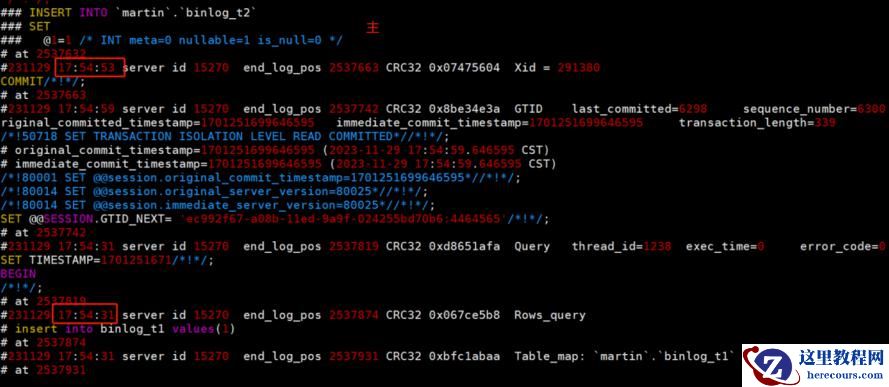
Binlog记录位置靠后的,时间点还靠前。
从库其实也一样的。
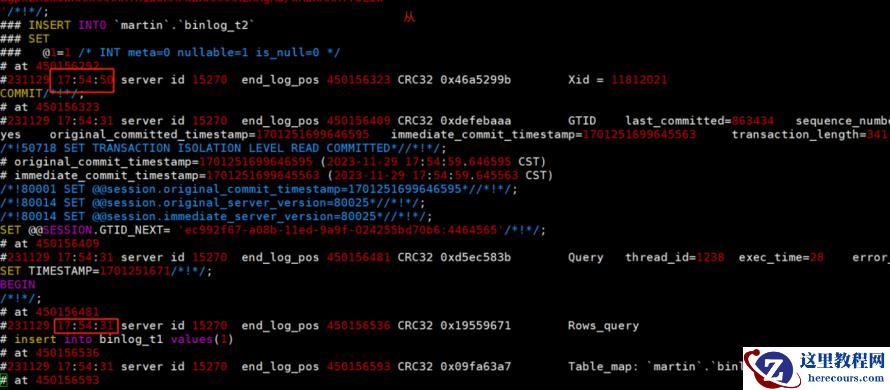
也就是并发事务,先执行SQL的,后面再提交(什么时候提交,什么时候记录Binlog),可能会出现时间在前面的事务,Binlog位置在后面,看起来像乱序了。
6 keepalived+主从,如果发生了vip漂移,那老的主启动,是不是不能同步数据了,这样会不会导致数据不一致?
一般建议是keepalived+双主,也就是两套数据库互为主备,这样及时切换了,反向还是同步的,那原来的主还是一直同步新主数据的。
但是一般只建议用一个VIP,也就是只在一个主上写,另外,如果要避免主键冲突,建议是主从跳主键的形式,比如主的主键 1 3 5,从的主键 2 4 6。
当然,现在推荐使用其他两款高可用方案:
InnoDB Cluster,可以参考之前写的部署文档:InnoDB Cluster的部署;
Orchestrator,可以参考之前写的部署文档:Orchestrator实现MySQL故障切换。












