来源:阿里云开发者
阿里妹导读
文章导读
一、场景描述
二、常见的优化方法
2.1.Mapjoin
SELECT /*+MAPJOIN(dim)*/ * FROM (SELECT * FROM dwd_tbl) base LEFT OUTER JOIN (SELECT * FROM dim_tbl) dimON base.dim_key = dim.dim_key
SELECT * FROM (SELECT * FROM dwd_tbl) base LEFT OUTER JOIN (SELECT * FROM dim_tbl) dimON IF(COALESCE(base.dim_key,'')='',CONCAT('HIVE_',RAND()),base.dim_key) = dim.dim_key
SELECT * FROM ( SELECT *,CAST(RAND()*10 AS BIGINT) AS ext_a FROM dwd_tbl) base LEFT OUTER JOIN ( SELECT * FROM dim_tbl LATERAL VIEW EXPLODE(SPLIT('0;1;2;3;4;5;6;7;8;9',';')) tt AS ext_b -- 或者Join一个用于倍数膨胀的小表) dimON base.dim_key = dim.dim_keyAND base.ext_a = dim.ext_b
2.4.热点数据单独处理/SkewJoin
热点数据单独处理的方案的核心点在于将热点数据提取出来单独处理,热点数据可以用Mapjoin的方式完成关联维表热点记录行,非热点则使用普通的shuffle模式的join方案完成关联。
-- Step01:热点数据记录提取INSERT OVERWRITE TABLE tmp_hot_list PARTITION (dt = '${bizdate}')SELECT dim_shop_id AS hot_idFROM main_tableWHERE dt = '${bizdate}'GROUP BY dim_shop_idHAVING COUNT(1) > 10000;INSERT OVERWRITE TABLE final_result_table PARTITION (dt = '${bizdate}')-- Step02:热点数据处理,使用MapJoin完成处理SELECT /*+MAPJOIN(a2,a3)*/a1.trade_no AS trade_no,a1.dim_shop_id AS shop_id,a3.shop_name AS shop_name,a3.shop_type AS shop_typeFROM (SELECT * FROM main_table WHERE dt = '${bizdate}') a1-- Step02-1:主表用JOIN关联热点表进行热点记录筛选JOIN (SELECT * FROM tmp_hot_list WHERE dt = '${bizdate}') a2 -- 热点数据清单ON a1.dim_shop_id = a2.dim_shop_id-- Step02-2:热点维度数据处理LEFT OUTER JOIN (SELECT /*+MAPJOIN(b2)*/ b1.*FROM (SELECT * FROM dim_table_info WHERE dt = '${bizdate}') b1JOIN (SELECT * FROM tmp_hot_list WHERE dt = '${bizdate}') b2 -- 热点数据清单ON b1.dim_shop_id = b2.dim_shop_id) a3ON a1.dim_shop_id = a3.dim_shop_idUNION ALL-- Step03:非热点数据处理,使用普通Join完成处理,两张表均需要进行ShuffleSELECT /*+MAPJOIN(a12)*/a11.trade_no AS trade_no,a11.dim_shop_id AS shop_id,a13.shop_name AS shop_name,a13.shop_type AS shop_typeFROM (SELECT * FROM main_table WHERE dt = '${bizdate}') a11-- Step03-1:主表用ANTI JOIN关联热点表进行剔除LEFT ANTI JOIN (SELECT * FROM tmp_hot_list WHERE dt = '${bizdate}') a12ON a11.dim_shop_id = a12.dim_shop_id-- Step03-2:非热点维度数据处理LEFT OUTER JOIN (SELECT /*+MAPJOIN(b12)*/ b11.*FROM (SELECT * FROM dim_table_info WHERE dt = '${bizdate}') b11LEFT ANTI JOIN (SELECT * FROM tmp_hot_list WHERE dt = '${bizdate}') b12ON b11.dim_shop_id = b12.dim_shop_id) a13ON a11.dim_shop_id = a13.dim_shop_id;
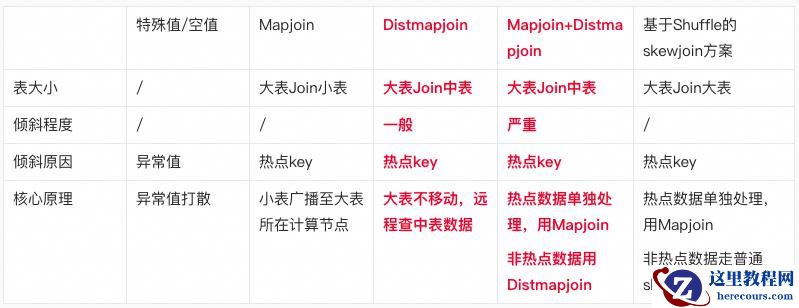
2.5.方案总结
三、一种新的思路 WithDistmapjoin~
3.1.核心思路
3.2.代码实现
3.3.真实效果
四、方案总结











以下 checksum table 不一致的问题")
")