使用数据库做开发、测试、演示或者执行一些短期的工作负载时,通常伴随着高昂的成本和复杂的配置问题。传统的数据库托管方式,例如 VPS,云虚拟机或者托管服务,不仅会持续产生费用,还会产生存储成本和配置开销。甚至在数据库闲置时,仍需要为资源付费。
但是否可以仅在需要时启动数据库,利用廉价(甚至免费的)对象存储保存数据,工作完成后销毁环境,同时几乎零成本且不丢失数据呢?一种可行的实现方法是将 GitHub Actions 作为临时计算环境,同时使用 S3(或兼容 S3 的服务)作为持久化存储,再通过安全隧道实现临时公网访问。
重要提示:
此方法仅适用于短期集成测试、临时演示或快速开发任务。 请勿滥用 GitHub Actions,请勿持续运行数据库或当作长期服务平台。GitHub Actions 设计初衷是 CI/CD,而非为持久化服务提供免费的计算资源。如果需要持续或长期运行的数据库托管,请考虑其他服务,或在受控环境中设置自托管的 GitHub Runner,并确保遵守 GitHub 使用协议。
核心思路
核心思路是:
- 使用 GitHub Actions 执行临时计算:按需启动兼容 MySQL 的数据库,作为 CI/CD 或测试工作流的一部分。
- 兼容 S3 的对象存储持久化:将数据库的数据存储在对象存储(如 AWS S3 或 Cloudflare R2)中。确保临时环境销毁后,数据仍能安全存储在外部存储系统中。
- 可公开访问的隧道:将数据库临时暴露到互联网,用于测试或演示。
- 仅适合短期使用:数据库仅在工作流执行窗口内运行,工作流结束后释放临时计算资源。这一方式不适用于长期托管解决方案。
薅羊毛提示:使用兼容 S3 服务的免费额度,比如 Cloudflare R2,可零成本实现,更香了。
应用场景
不推荐用于以下场景:
注意:如有长期使用需求,建议使用 自托管 Runner,自行管理资源,遵循使用规则。
GitHub Actions 工作流示例
以下是一个 GitHub Actions 工作流示例,演示了如何在短时间内启动 WeSQL 数据库,使用对象存储持久化数据,并提供隧道实现临时访问。如需复用该工作流,可参考 README 中的步骤。
name: Start WeSQL Clusteron:
workflow_dispatch:jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Configure AWS CLI
run: |
aws configure set aws_access_key_id ${{ secrets.WESQL_OBJECTSTORE_ACCESS_KEY }}
aws configure set aws_secret_access_key ${{ secrets.WESQL_OBJECTSTORE_SECRET_KEY }}
aws configure set default.region ${{ secrets.WESQL_OBJECTSTORE_REGION }}
- name: Start WeSQL Server
run: |
export WESQL_OBJECTSTORE_BUCKET=${{ secrets.WESQL_OBJECTSTORE_BUCKET }}
export WESQL_OBJECTSTORE_REGION=${{ secrets.WESQL_OBJECTSTORE_REGION }}
export WESQL_OBJECTSTORE_ACCESS_KEY=${{ secrets.WESQL_OBJECTSTORE_ACCESS_KEY }}
export WESQL_OBJECTSTORE_SECRET_KEY=${{ secrets.WESQL_OBJECTSTORE_SECRET_KEY }}
docker run -itd --network host --name wesql-server \
-p 3306:3306 \
-e MYSQL_CUSTOM_CONFIG="[mysqld]\n\
port=3306\n\
log-bin=binlog\n\
gtid_mode=ON\n\
enforce_gtid_consistency=ON\n\
log_slave_updates=ON\n\
binlog_format=ROW\n\
objectstore_provider='aws'\n\
repo_objectstore_id='tutorial'\n\
objectstore_bucket='${WESQL_OBJECTSTORE_BUCKET}'\n\
objectstore_region='${WESQL_OBJECTSTORE_REGION}'\n\
branch_objectstore_id='main'" \
-v ~/wesql-local-dir:/data/mysql \
-e WESQL_CLUSTER_MEMBER='127.0.0.1:13306' \
-e MYSQL_ROOT_PASSWORD=${{ secrets.WESQL_ROOT_PASSWORD }} \
-e WESQL_OBJECTSTORE_ACCESS_KEY=${WESQL_OBJECTSTORE_ACCESS_KEY} \
-e WESQL_OBJECTSTORE_SECRET_KEY=${WESQL_OBJECTSTORE_SECRET_KEY} \
apecloud/wesql-server:8.0.35-0.1.0_beta3.38
- name: Wait for MySQL port
run: |
for i in {1..60}; do
if nc -z localhost 3306; then
echo "MySQL port 3306 is ready!"
exit 0
fi
echo "Waiting for MySQL port 3306..."
sleep 5
done
echo "Timeout waiting for MySQL port 3306"
exit 1
- name: Start and parse Serveo tunnel
run: |
# Just a neat trick: start a tunnel and parse out the assigned port
nohup ssh -o StrictHostKeyChecking=no -R 0:localhost:3306 serveo.net > serveo.log 2>&1 &
sleep 5
TUNNEL_LINE=$(grep 'Forwarding TCP' serveo.log || true)
if [ -z "$TUNNEL_LINE" ]; then
echo "No forwarding line found"
exit 1
fi
HOST="serveo.net"
PORT=$(echo "$TUNNEL_LINE" | sed 's/.*Forwarding TCP connect from .*:\([0-9]*\)/\1/')
echo "MySQL Public Access:"
echo "Host: $HOST"
echo "Port: $PORT"
echo "Connect: mysql -h $HOST -P $PORT -u root -p${{ secrets.WESQL_ROOT_PASSWORD }}"
echo "HOST=$HOST" >> $GITHUB_ENV
echo "PORT=$PORT" >> $GITHUB_ENV
- name: Write Connection Info to S3
run: |
# Just a convenience: store connection info in S3 so you can find it later
cat << EOF > connection_info.txt
host=$HOST
port=$PORT
username=root
password=${{ secrets.WESQL_ROOT_PASSWORD }}
mysql_cli="mysql -h $HOST -P $PORT -u root -p${{ secrets.WESQL_ROOT_PASSWORD }}"
EOF
aws s3 cp connection_info.txt s3://${{ secrets.WESQL_OBJECTSTORE_BUCKET }}/connection_info.txt
echo "Connection info is now in s3://${{ secrets.WESQL_OBJECTSTORE_BUCKET }}/connection_info.txt"
- name: Keep session running
run: |
# Keep the workflow alive so the database stays accessible.
echo "Press Ctrl+C or cancel the workflow when done."
tail -f /dev/null
工作流详解(附赠小技巧)
连接数据库
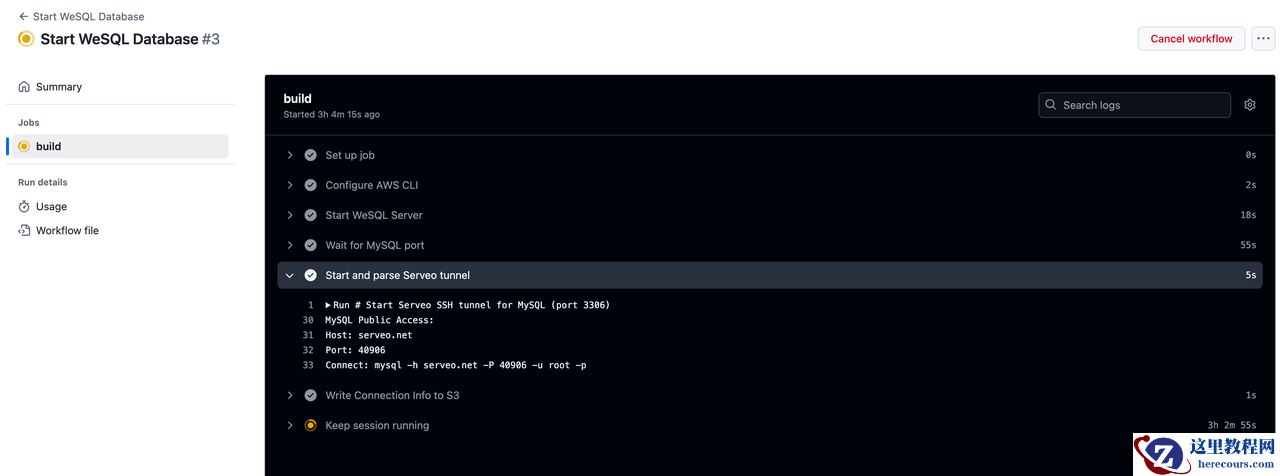
工作流正常运行后,可通过 Action 日志获取数据库
Host 和
Port 信息。如需本地连接,可修改以下示例中的信息后执行:
mysql -h serveo.net -P <PORT> -u root -p<YOUR_PASSWORD>
数据持久化与重启
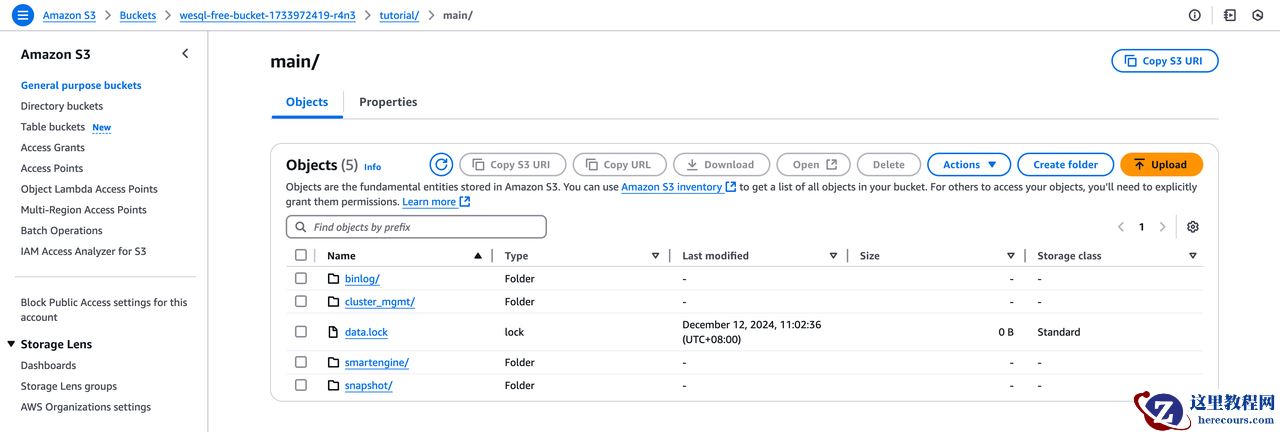
这个方法的核心优势在于:Runner 终止后,容器虽然消失,但数据仍然保存在对象存储中。下次运行 GitHub 工作流时,WeSQL 会从 S3、R2 或者其他兼容 S3 的存储服务中恢复数据。这意味着即使计算环境是短暂的,您的数据库却能长期存在。
您可以在 S3 的存储桶中查看所有数据:
安全注意事项
总结
此方法颠覆了传统“租用服务器并保持其长期运行”的数据库模式。通过 GitHub Actions 提供临时计算能力,并搭配 S3 持久存储,您可以拥有按需运行、零成本且随时可用的 Serverless 数据库,非常适合快速测试或演示。
下次需要临时数据库环境时,不妨试试这种方法,告别高成本的虚拟机或托管实例!










