在我们开发系统过程中,我们系统经常会存储用户信息,用户信息中记录用户的身份证,邮件,手机号等信息,有时候系统在登录时,可以支持使用邮箱,身份证,手机号来登录信息系统。
那么经常执行的sql语句就是
select userid,email from myuser where email='xxxxx@mail.com';
或者
select userid, phone from myuser where phone='1403333xxxx';
或者
select userid,idcade from myuser where idcade='372501xxxxxxxxxxxxxxx0001';
我们今天要讨论的问题是: 如何在邮箱,身份证,手机号这样的字符串的字段上建立合理的索引。
用户信息表如下:
mysql> create table myuser(ID bigint unsigned primary key,username varchar(64),idcade varchar(18),email varchar(64), phone varchar(11),... )ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; 假如:我们要使用邮件登录信息 select id,email from myuser where email='xxxxx@mail.com'; 我们可以知道,如果email这个字段上没有索引,那么这个语句就只能做全表扫描。
全表扫描的缺点有很多, 导致大量 I/O 操作,CPU 和内存资源消耗高,响应时间慢:数据量越大,扫描时间越长,用户体验差。
同时,MySQL是支持前缀索引的,也就是说,你可以定义字符串的一部分作为索引。默认地,如果你创建索引的语句不指定前缀长度,那么索引就会包含整个字符串。
比如,在email字段上创建索引的语句:--整个字段的索引mysql> alter table myuser add index ind_email (email);或-- 前缀索引mysql> alter table myuser add index ind_pro_email (email(6));
第一个语句创建的 ind_email 索引里面,包含了每个记录的整个字符串;
第二个语句创建的 ind_pro_email 索引里面,对于每个记录都是只取前6个字节。
那么,这两种不同的定义在数据结构和存储上有什么区别呢?
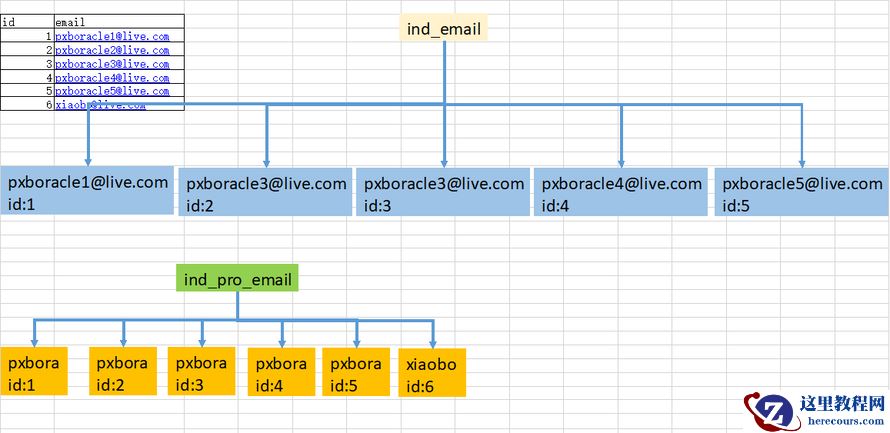
从图中你可以看到, ind_email索引要存储字段所有的值,占用空间大, ind_pro_email只取前6个字符email(6),这个索引结构中每个邮箱字段都只取前6个字节(即:pxbora),所以占用的空间会更小,这就是使用前缀索引的优势。
但是这同时带来的问题是,可能会增加额外的记录扫描次数,扫描5次。
接下来,我们一起看看下面这个语句,在这两个索引定义下分别是怎么执行的。
mysql> select id, username, idcade, phone,email from myuser where email='pxboracle3@live.com';
使用索引 ind_email情况:
执行顺序是这样的:
-
从 ind_email索引树找到满足索引值是 pxboracle3@live.com的这条记录,取得ID2的值3;
-
到主键上查到主键值是ID2的行,判断email的值是正确的,将这行记录加入结果集;(这步要回表)
-
取 ind_email索引树上刚刚查到的位置的下一条记录,发现 email=' pxboracle4@live.com ’已经不满足email=' pxboracle3@live.com’的条件了,循环结束。
这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行。
使用索引 ind_pro_email(即email(6)索引结构):
执行顺序是这样的:
-
从 ind_pro_email索引树找到满足索引值是pxbora的记录,找到的第一个是ID值是1;
-
到主键上查到主键值是ID值是1的行,判断出email的值不是 pxboracle3@live.com,这行记录丢弃;
-
取 ind_pro_email上刚刚查到的位置的下一条记录,发现仍然是pxbora,取出ID值是2, 判断出email的值不是 pxboracle3@live.com ,这行记录丢弃;
-
取 ind_pro_email 上刚刚查到的位置的下一条记录,发现仍然是pxbora,取出ID值是3,再到ID索引上取整行然后判断,这次值对了,将这行记录加入结果集;
-
重复上一步,直到在 ind_pro_email上取到的值不是pxbora时,循环结束。
在这个过程中,要回主键索引取6次数据,也就是扫描了6行。
通过对比,我们发现,使用前缀索引后,可能会导致查询语句读数据的次数变多。
那么有没有办法解决这个问题那?
回答是,当然有了,我们只需要多截取一些字节,就能区分了。
比如我们可以一点一点的截取,获得截取多少位,能保障数据的唯一性。
在我们这个例子,对于这个查询语句来说,索引 ind_pro_email不是email(6)而是email(10),也就是说取email字段的前10个字节来构建索引的话,即满足前缀pxboracle3的记录只有一个,也能够直接查到ID值是3的记录,只扫描一行就结束了。
也就是说 使用前缀索引,只有计算好截取字段长度,就可以做到既节省空间,又不用额外增加太多的查询成本。
于是,你就有个问题:当要给字符串创建前缀索引时,有什么方法能够确定我应该使用多长的前缀呢?
实际上,我们在建立索引时关注的是区分度,区分度越高越好。因为区分度越高,意味着重复的键值越少。因此,我们可以通过统计索引上有多少个不同的值来判断要使用多长的前缀。
首先,你可以使用下面这个语句,算出这个列上有多少个不同的值:
mysql> select count(distinct email) as L from myuser ;
然后,依次选取不同长度的前缀来看这个值,比如我们要看一下4~7个字节的前缀索引,可以用这个语句:
mysql> select count(distinct left(email,4))as L4, count(distinct left(email,5))as L5, count(distinct left(email,6))as L6, count(distinct left(email,7))as L7, count(distinct left(email,8))as L8, count(distinct left(email,9))as L9, count(distinct left(email,10))as L10, count(distinct left(email,11))as L11, from myuser ;
当然,使用前缀索引很可能会损失区分度,所以你需要预先设定一个可以接受的损失比例,比如5%。然后,在返回的L4~L10中,找出不小于 L * 95%的值,假设这里L10、L11都满足,你就可以选择前缀长度为10。




")






