一、引言
对于MySQL数据库而言,ibdata1文件就是它的“心脏”。这个核心文件管理着所有InnoDB表的结构和信息(元数据),一旦它损坏或丢失,整个数据库实例将陷入瘫痪。本文将揭秘我们如何借助AI的力量,快速完上千张表的快速恢复
二、数据库宕机
事故现场:一台数据库服务器因意外操作,导致ibdata1文件被清空。数据库服务瞬间崩溃。
常规抢救无效:我们第一时间尝试了最后的救命稻草——将 innodb_force_recovery 参数设置为 6,试图强行启动数据库并进行备份。但结果是残酷的:MySQL启动后,无法执行正常的mysqldump备份。常规备份恢复手段失效。幸运的是.ibd,.frm文件依然存在。
面临的绝境:数据似乎就在那里(上千个.ibd文件),但我们却无法叫出它们的名字,无法让数据库重新识别它们
三、逐表恢复的“苦役”
万幸的是,MySQL提供了“运输表空间”(Transportable Tablespace)的机制。只要拥有单张表的.frm(表结构)和对应的.ibd(表数据)文件,理论上就能逐一“复活”每张表。
标准恢复流程:
1、读取结构:从 .frm 文件中提取出创建表的SQL语句。
2、运输数据:在新实例上创建空表 -> 丢弃其表空间 -> 拷贝旧.ibd文件 -> 重新导入。
然而, 现实是:我们面对的是 数千张表。手动重复以上步骤意味着:
巨大的工作量:数千次重复操作。
极高的错误风险:一次手误就可能导致数据损坏。
不可接受的时间成本:业务停摆等不起。
我们需要的不是一个手动流程,而是一个全自动的“批量救援机器人”
四、破局!召唤AI“外援”,编写自动化脚本
1、打造“结构侦察兵”:read_frm.sh
任务:智能遍历所有 .frm 文件,并使用mysqlfrm工具从中准确提取出每张表的创建语句(CREATE TABLE语句)。
2. 打造“数据运输队”:recover_data.sh
任务:接收“侦察兵”提供的信息,自动为每张表执行“创建空表 -> DISCARD TABLESPACE -> 复制.ibd文件 -> IMPORT TABLESPACE”这一系列高危、重复的核心操作。
同时必须包含严谨的错误处理、日志记录,并能循环处理表名列表。
最终:read_frm.sh -> 生成SQL文件 -> recover_data.sh -> 批量恢复数据
五、效果演示
1、批量提取表结构 sh read_frm.sh
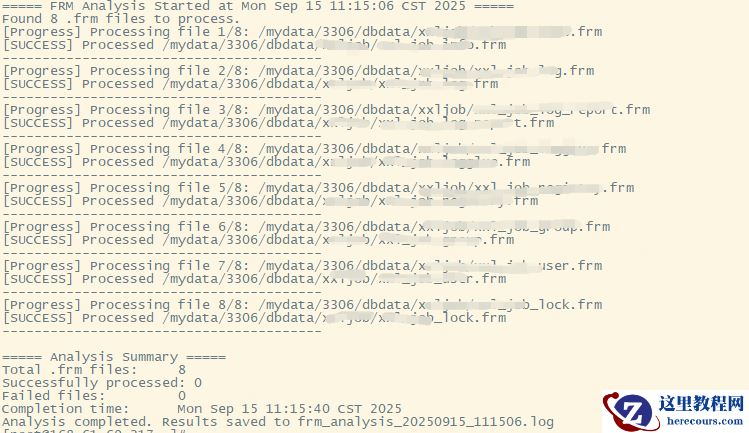
2、创建新的mysql实例->创建同名数据库
3、导入表结构:把read_frm.sh 生成文件导入到新库中
4、复制.ibd文件到新的数据库服务器的其他目录中,比如/tmp
5、批量恢复 sh recover_data.sh
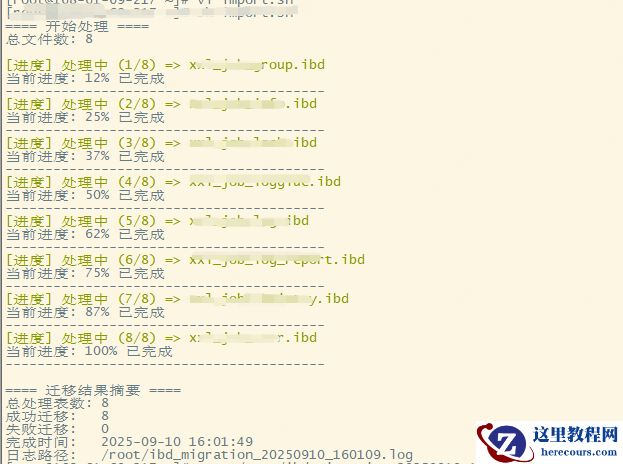
六、从“人工苦役”到“AI天堂”的视觉化呈现
| 方面 | 传统手动恢复 | AI双脚本流水线 |
|---|---|---|
| 预计耗时 | 2-3人日 (按5秒/表计算,不含疲劳、出错时间) | ~15分钟 (脚本执行时间,一键启动) |
| 操作方式 | 人工反复敲击重复命令,精神高度紧张。 | 终端中一键执行
./recover_data.sh,然后泡杯咖啡。 |
| 错误风险 | 极高。疲劳导致的误删除、命令输错、表遗漏难以避免。 | 趋近于0。脚本逻辑严谨,自动处理所有表,无疲劳问题。 |
| 心理压力 | 巨大。如同在悬崖边行走,每一次回车都心惊胆战。 | 轻松。脚本运行,日志翻滚,一切尽在掌控。 |
| 可复用性 | 几乎为0。本次操作无法积累为有效资产。 | 100%。脚本成为团队知识库资产,下次故障 分钟级响应。 |
| 过程可视化 |
$ mysql -e "CREATE TABLE ...;"
|
$ ./read_frm.sh
|
七、脚本代码
1:read_frm.sh
#!/bin/bash
# 定义变量
##FRM_DIR 数据库.frm 文件目录
FRM_DIR="/mydata/3306/xxx"
OUTPUT_FILE="frm_analysis_$(date +%Y%m%d_%H%M%S).sql"
##mysqlfrm命令的目录
MYSQLFRM_CMD="/bin/mysqlfrm"
##mysql数据库basedir 目录
MYSQL_BASEDIR="/mysql"
##指定一个新实例的可用的PORT端口
PORT="3334"
##指定一个新实例的启动用户
USER="root"
# 检查目录是否存在
if [ ! -d "$FRM_DIR" ]; then
echo "[ERROR] Directory $FRM_DIR does not exist!" >&2
exit 1
fi
# 检查mysqlfrm命令是否存在
if ! command -v "$MYSQLFRM_CMD" &> /dev/null; then
echo "[ERROR] mysqlfrm command not found!" >&2
exit 1
fi
# 创建输出文件
touch "$OUTPUT_FILE" || {
echo "[ERROR] Cannot create output file $OUTPUT_FILE" >&2
exit 1
}
# 获取文件总数和计数器
TOTAL_FILES=$(find "$FRM_DIR" -type f -name "*.frm" | wc -l)
CURRENT_COUNT=0
PROCESSED_FILES=0
FAILED_FILES=0
echo "===== FRM Analysis Started at $(date) ====="
echo "Found $TOTAL_FILES .frm files to process."
# 主处理循环(兼容性写法)
find "$FRM_DIR" -type f -name "*.frm" -print0 | while IFS= read -r -d '' frm_file; do
((CURRENT_COUNT++))
# 显示进度
printf "[Progress] Processing file %d/%d: %s\n" $CURRENT_COUNT $TOTAL_FILES "$frm_file"
# 执行mysqlfrm命令
if "$MYSQLFRM_CMD" --basedir="$MYSQL_BASEDIR" --port="$PORT" --user="$USER" "$frm_file" >> "$OUTPUT_FILE" 2>&1; then
echo "[SUCCESS] Processed $frm_file"
((PROCESSED_FILES++))
else
echo "[ERROR] Failed to process $frm_file"
((FAILED_FILES++))
fi
echo "----------------------------------------"
done
# 输出统计信息
{
echo ""
echo "===== Analysis Summary ====="
echo "Total .frm files: $TOTAL_FILES"
echo "Successfully processed: $PROCESSED_FILES"
echo "Failed files: $FAILED_FILES"
echo "Completion time: $(date)"
}
sed -i '/) ENGINE=InnoDB DEFAULT / s/$/;/' $OUTPUT_FILE
echo "Analysis completed. Results saved to $OUTPUT_FILE"
2:recover_data.sh
#!/bin/bash
# 配置参数(请根据实际环境修改)
SOURCE_DIR="/tmp" # 源.ibd文件目录
DEST_DIR="/mydata/3306/xxx" # 目标目录,即:新的数据库文件目录
MYSQL_CMD="/mysql/bin/mysql" # MySQL客户端绝对路径
MYSQL_USER="root" # MySQL用户名
MYSQL_HOST="127.0.0.1"
MYSQL_PASS="xxx" # MySQL密码
MYSQL_PORT="3306" # MySQL端口
MYSQL_DB="xxx" # 数据库名
SLEEP_TIME=2 # 操作间隔(秒)
# 获取脚本所在绝对路径
SCRIPT_DIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
LOG_FILE="${SCRIPT_DIR}/ibd_migration_$(date +%Y%m%d_%H%M%S).log"
# 初始化日志文件
init_log() {
echo "==== IBD表空间迁移日志 ====" > "$LOG_FILE"
echo "开始时间: $(date '+%Y-%m-%d %H:%M:%S')" >> "$LOG_FILE"
echo "源目录: $SOURCE_DIR" >> "$LOG_FILE"
echo "目标目录: $DEST_DIR" >> "$LOG_FILE"
echo "MySQL实例: ${MYSQL_USER}@127.0.0.1:${MYSQL_PORT}/${MYSQL_DB} " >> "$LOG_FILE"
echo "" >> "$LOG_FILE"
}
# 检查依赖项
check_dependencies() {
local errors=0
# 检查源目录
if [ ! -d "$SOURCE_DIR" ]; then
echo "[ERROR] 源目录不存在: $SOURCE_DIR" | tee -a "$LOG_FILE"
((errors++))
fi
# 检查目标目录
if [ ! -d "$DEST_DIR" ]; then
echo "[ERROR] 目标目录不存在: $DEST_DIR" | tee -a "$LOG_FILE"
((errors++))
fi
# 检查MySQL客户端
if [ ! -x "$MYSQL_CMD" ]; then
echo "[ERROR] MySQL客户端不可执行: $MYSQL_CMD" | tee -a "$LOG_FILE"
((errors++))
fi
return $errors
}
# 执行MySQL命令
exec_mysql() {
local sql="$1"
local table="$2"
if ! "$MYSQL_CMD" -u"$MYSQL_USER" -p"$MYSQL_PASS" -P"$MYSQL_PORT" \
--database="$MYSQL_DB" -h"$MYSQL_HOST" -e "$sql" >> "$LOG_FILE" 2>&1; then
echo "[ERROR] SQL执行失败: $table - ${sql:0:50}..." | tee -a "$LOG_FILE"
return 1
fi
return 0
}
# 处理单个表空间
process_ibd() {
local src_file="$1"
local table_name=$(basename "$src_file" ".ibd")
local dest_file="${DEST_DIR}/${table_name}.ibd"
{
echo "---- 处理表: $table_name ----"
echo "开始时间: $(date '+%Y-%m-%d %H:%M:%S')"
# 1. 丢弃表空间
echo "执行: ALTER TABLE ${table_name} DISCARD TABLESPACE"
if ! exec_mysql "ALTER TABLE ${table_name} DISCARD TABLESPACE" "$table_name"; then
echo "[FAILED] 丢弃表空间失败"
return 1
fi
# 2. 拷贝文件
echo "执行: cp ${src_file} ${dest_file}"
if ! /usr/bin/cp -v "${src_file}" "${dest_file}" >> "$LOG_FILE" 2>&1; then
echo "[FAILED] 文件拷贝失败"
return 1
fi
# 3. 导入表空间
echo "执行: ALTER TABLE ${table_name} IMPORT TABLESPACE"
if ! exec_mysql "ALTER TABLE ${table_name} IMPORT TABLESPACE" "$table_name"; then
echo "[FAILED] 导入表空间失败"
return 1
fi
# 4. 等待
echo "等待 ${SLEEP_TIME}秒..."
/bin/sleep $SLEEP_TIME
echo "完成时间: $(date '+%Y-%m-%d %H:%M:%S')"
echo "状态: 成功"
echo ""
} >> "$LOG_FILE" 2>&1
return $?
}
# 主流程
main() {
init_log
if ! check_dependencies; then
echo "依赖检查失败,请查看日志: $LOG_FILE" >&2
exit 1
fi
# 新增:启用nullglob并获取文件列表
shopt -s nullglob
local ibd_files=("$SOURCE_DIR"/*.ibd)
shopt -u nullglob
# 修改:获取准确的文件总数
local total=${#ibd_files[@]}
local current=0 success=0 fail=0
# 新增:空文件检查
if [ "$total" -eq 0 ]; then
echo "未找到任何.ibd文件,无需处理。" | tee -a "$LOG_FILE"
exit 0
fi
# 新增:打印总任务数
echo "==== 开始处理 ====" | tee -a "$LOG_FILE"
echo "总文件数: $total" | tee -a "$LOG_FILE"
echo "" | tee -a "$LOG_FILE"
# 修改:带进度显示的循环结构
for ibd_file in "${ibd_files[@]}"; do
((current++))
# 新增:进度提示(含彩色输出)
printf "\e[32m[进度] 处理中 (%d/%d) => %s\e[0m\n" \
"$current" "$total" "$(basename "$ibd_file")" | tee -a "$LOG_FILE"
# 原有处理逻辑
if process_ibd "$ibd_file"; then
((success++))
else
((fail++))
fi
# 新增:进度百分比
echo "当前进度: $((current*100/total))% 已完成" | tee -a "$LOG_FILE"
echo "----------------------------------------" | tee -a "$LOG_FILE"
done
# 输出摘要(拆分为多行tee命令更易读)
echo "" | tee -a "$LOG_FILE"
echo "==== 迁移结果摘要 ====" | tee -a "$LOG_FILE"
echo "总处理表数: $total" | tee -a "$LOG_FILE"
echo "成功迁移: $success" | tee -a "$LOG_FILE"
echo "失败迁移: $fail" | tee -a "$LOG_FILE"
echo "完成时间: $(date '+%Y-%m-%d %H:%M:%S')" | tee -a "$LOG_FILE"
echo "日志路径: $LOG_FILE" | tee -a "$LOG_FILE"
}
# 执行主函数
main
微信公众号:DB智能体












