1 、 MGR 介绍
MySQL Group Replication ( MGR )组复制在 5.1.17 版本中开始引入,基于” paxos ”协议实现的数据一致性和高可用的集群方案,用于解决异步或者半同步复制可能产生的不一致性。它是 mysql 自带的插件 (group_replication.so) ,支持节点的故障自动检测、弹性扩展等功能,同时还支持单主或多主写,自动检测冲突,保证数据的最终一致性。
与 MHA 相比, MGR 通过“ paxos ”协议进行自动选举主节点,保证多数派原则集群就可以正常服务,自动切换,减少了人工介入成本;在选举前, MGR 会一直感知节点的状态,对于异常节点不会参与选举过程。
通过查询 performance_schema 下的 replication_group_members 表可以知道 MGR 集群中节点的状态,如下:
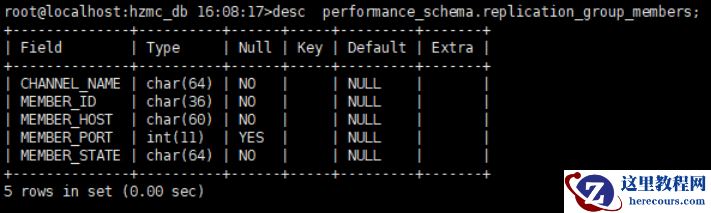
· CHANNEL_NAME : 显示的值永远为 group_replication_applier
· MEMBER_ID : 节点 serer_uuid
· MEMBER_PORT : 节点服务端口,取值为 server_port 指定的端口
· MEMBER_HOST : 如果没有配置 report_host 选项,那么取值为机器的 hostname ,可以通过 report_host 配置指定具体的 IP
对于 MGR 架构来讲,节点新增或发生故障,又该如何进行处理,参考如下:
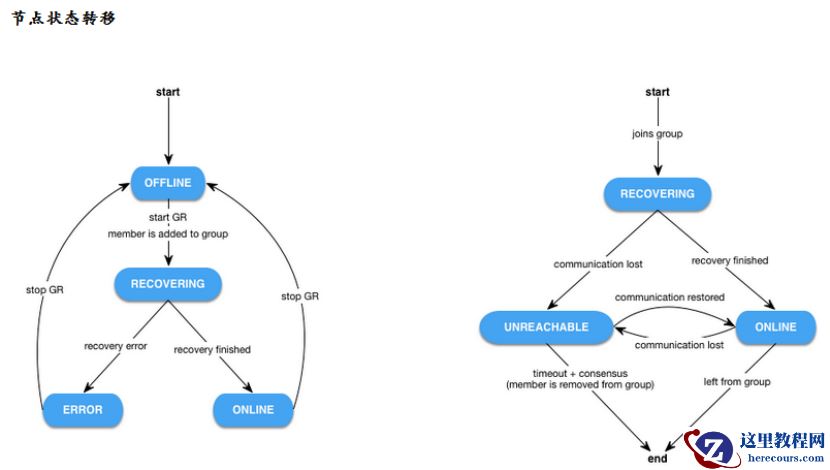
当一个节点加入一个 MGR 组,其状态先会变成 RECOVERING ,表示当前节点正处于恢复阶段,这个阶段,节点会选择集群中一个节点 (donor 节点 ) ,利用传统的异步复制做恢复。当数据能够成功追平,节点的状态将会变成 ONLINE ,这个过程中通过其他节点也可以看到该节点的状态,不管是 RECOVERING 还是最后的 ONLINE 。
假如该节点在 RECOVERING 阶段出现了异常 ( 选 donor 进行复制失败 or 在 donor 追数据的过程中失败),那么该节点的状态将会变成 ERROR ,注意,这时候在其他节点上查询时,发现该 RECOVERING 节点已经从组里面被踢出。
另外,如果一个 ONLINE 节点失去与其他节点的通讯(可能因为节点 crash 或者网络异常),则该节点在其他节点上面查询到的状态将会是 UNREACHABLE 。如果这个 UNREACHABLE 节点在规定的超时时间内没有恢复过来,那么节点将会被踢出去。这个规定的超时时间是多少呢?下面会讲这个时间在集群失去这个节点是否可用的条件下是不一样的。
可疑的 UNREACHABLE 状态。 UNREACHABLE 节点在规定的超时时间内如果没有恢复过来,那么节点将会被踢出去。这个规定的超时时间,取决于集群失去这个节点下还是不是达到可用状态( MGR 采用多副本,在 2N+1 个节点集群中,集群只要 N +1 个节点还存活着,数据库就能稳定的对外提供服务)。假设失去这个节点,集群仍然可用,那么这个 UNREACHABLE 的超时时间很短,几乎看不到这个状态;但是,如果失去这个节点后集群马上不可用,那么这个 UNREACHABLE 节点的超时时间,近似于无线大,将会一直处于 UNREACHABLE!
2 、故障模拟
3 节点组成的集群,最开始 3 个节点均为 ONLINE 状态

模拟主节点异常宕机,例如 OOM ,直接 kill -9 主实例( doris01 ),通过其他可用节点查询到,那一个 kill 掉的实例从集群中被踢走了 :

接下来我们再 kill 掉新的一个主实例( doris02 )
这个时候,如果 doris02 实例有会话一直未退出,则 UNREACHABLE 状态将一直持续,而且此时,集群不满足 N + 1 ,集群已经不可用。待会话全部退出后,该实例也将从集群中被踢出


3 、解决方案
1 、主节点可以重启成功,即前面 kill 掉的节点能正常起来,再加入 GR 组
启动 doris01 主节点,并加入 MGR 组
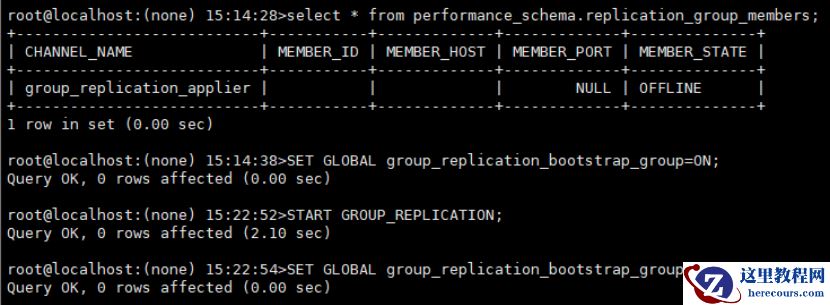
启动 doris02 从节点、重启 doris03 从节点,再执行分别执行以下命令,重新加入 MGR 组里

查看集群状态,三个节点均为 ONLINE ,表示集群恢复正常可用

2 、主节点重启失败,即前面 kill 掉的节点无法正常起来, doris03 节点降为单实例,然后重建 MGR 集群
重启 doris03 实例,状态变为 OFFLINE

禁用 readonly 参数

应用程序切换到该实例即可使用
模拟基于 doris03 实例,重新搭建 MGR
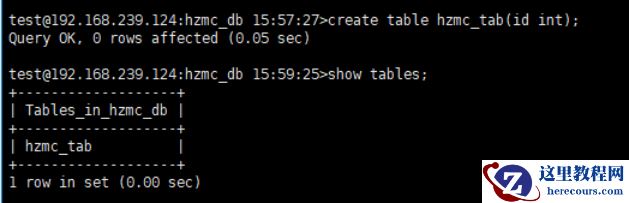
doris03 实例上,创建个新库 hzmc_db ,模拟业务在写入数据
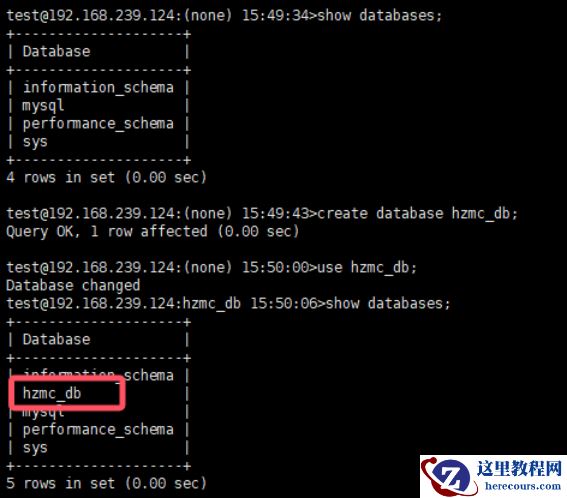
doris03 ,启动单主模式,并模拟写上数据写入
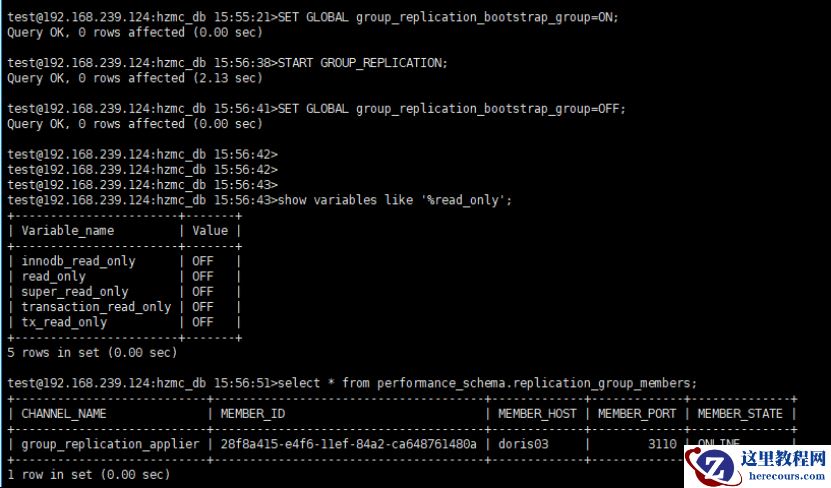
修复 doris01 、 doris02 ,并成功启动后,分别执行 START GROUP_REPLICATION;
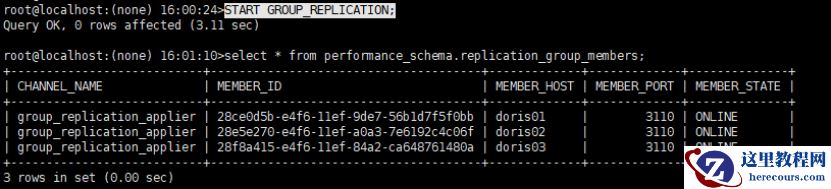
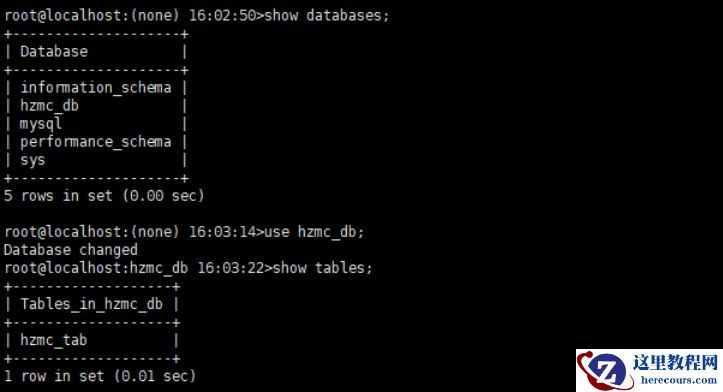
doris01 、 02 上验证, hzmc_tab 已同步过去,修复完成
如果 doris01 、 doris02 无法修复,按新增节点的方式,扩容两个节点即可












