一、需求场景分析
在实际的数据平台运营管理过程中,数据表的规模往往随着更多业务数据的接入以及数据应用的建设而逐渐增长到非常大的规模,数据管理人员往往希望能够利用元数据的分析来更好地掌握不同数据表的血缘关系,从而分析出数据的上下游依赖关系。
本文将介绍如何去根据MaxCompute InformationSchema中作业ID的输入输出表来分析出某张表的血缘关系。
二、方案设计思路
MaxCompute Information_Schema提供了访问表的作业明细数据tasks_history,该表中有作业ID、input_tables、output_tables字段记录表的上下游依赖关系。根据这三个字段统计分析出表的血缘关系
1、根据某1天的作业历史,通过获取tasks_history表里的input_tables、output_tables、作业ID字段的详细信息,然后分析统计一定时间内的各个表的上下游依赖关系。
2、根据表上下游依赖推测出血缘关系。
三、方案实现方法
参考示例一:
(1)根据作业ID查询某表上下游依赖SQL处理如下:
select t2.input_table, t1.inst_id, replace(replace(t1.output_tables,"[",""),"]","") as output_table from information_schema.tasks_history t1 left join ( select ---去除表开始和结尾的[ ] trans_array(1,",",inst_id, replace(replace(input_tables,"[",""),"]","")) as (inst_id,input_table) from information_schema.tasks_history where ds = 20190902 )t2 on t1.inst_id = t2.inst_id where (replace(replace(t1.output_tables,"[",""),"]","")) <> "" order by t2.input_table limit 1000;
结果如下图所示:

(2)根据结果可以分析得出每张表张表的输入表输出表以及连接的作业ID,即每张表的血缘关系。
血缘关系位图如下图所示:
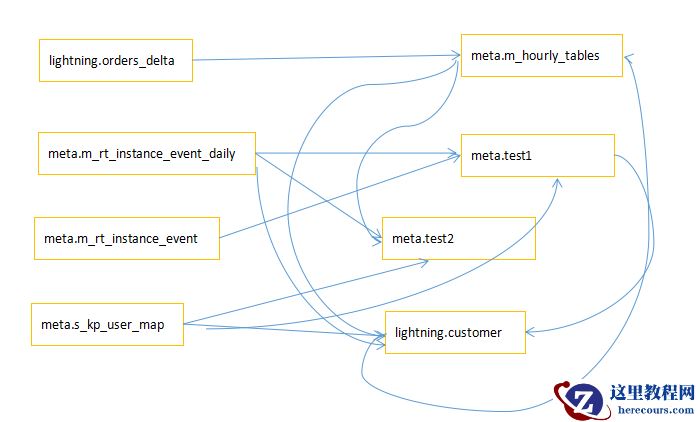
中间连线为作业ID,连线起始为输入表,箭头所指方向为输出表。
参考示例二:
以下方式是通过设置分区,结合DataWorks去分析血缘关系:
(1)设计存储结果表Schema
CREATE TABLE IF NOT EXISTS dim_meta_tasks_history_a ( stat_date STRING COMMENT '统计日期', project_name STRING COMMENT '项目名称', task_id STRING COMMENT '作业ID', start_time STRING COMMENT '开始时间', end_time STRING COMMENT '结束时间', input_table STRING COMMENT '输入表', output_table STRING COMMENT '输出表', etl_date STRING COMMENT 'ETL运行时间' );
(2)关键解析sql
SELECT
'${yesterday}' AS stat_date
,'project_name' AS project_name
,a.inst_id AS task_id
,start_time AS start_time
,end_time AS end_time
,a.input_table AS input_table
,a.output_table AS output_table
,GETDATE() AS etl_date
FROM (
SELECT
t2.input_table
,t1.inst_id
,replace(replace(t1.input_tables,"[",""),"]","") AS output_table
,start_time
,end_time
FROM (
SELECT
*
,ROW_NUMBER() OVER(PARTITION BY output_tables ORDER BY end_time DESC) AS rows
FROM information_schema.tasks_history
WHERE operation_text LIKE 'INSERT OVERWRITE TABLE%'
AND (
start_time >= TO_DATE('${yesterday}','yyyy-mm-dd')
and
end_time <= DATEADD(TO_DATE('${yesterday}','yyyy-mm-dd'),8,'hh')
)
AND(replace(replace(output_tables,"[",""),"]",""))<>""
AND ds = CONCAT(SUBSTR('${yesterday}',1,4),SUBSTR('${yesterday}',6,2),SUBSTR('${yesterday}',9,2))
)t1
LEFT JOIN(
SELECT TRANS_ARRAY(1,",",inst_id,replace(replace(input_tables,"[",""),"]","")) AS (inst_id,input_table)
FROM information_schema.tasks_history
WHERE ds = CONCAT(SUBSTR('${yesterday}',1,4),SUBSTR('${yesterday}',6,2),SUBSTR('${yesterday}',9,2))
)t2
ON t1.inst_id = t2.inst_id
where t1.rows = 1
) a
WHERE a.input_table is not null
;
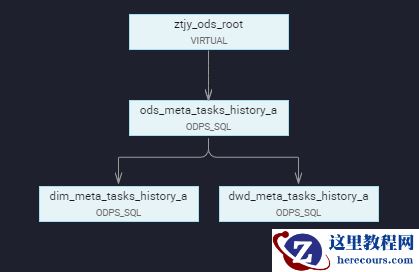
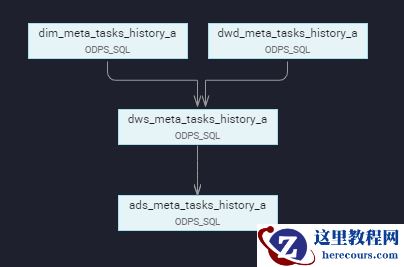
(3)任务依赖关系
(4)最终血缘关系
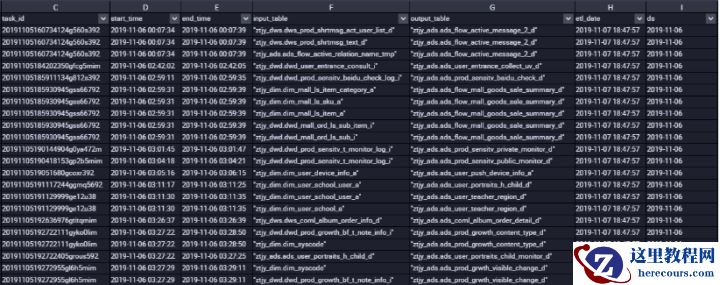
以上血缘关系的分析是根据自己的思路实践去完成。真实的业务场景需要大家一起去验证。所以希望大家有需要的可以根据自己的业务需求去做相应的sql修改。如果有发现处理不当的地方希望多多指教。我在做相应的调整。
原文链接
本文为阿里云内容,未经允许不得转载。
编辑推荐:
- 基于MaxCompute InformationSchema进行血缘关系分析03-02
- 腾讯云SQL Server 性能逆天,252万TPM国内无对手!03-02
- 车牌识别系统03-02
- 文通科技OCR证件识别|03-02
- wait_type SOS_WORKER导致数据库连接失败03-02
- 电脑桌面图标变大恢复调小图文教程03-02
- Intel英特尔Core i9-11900H跑分及参数性能详解03-02
- 电脑屏幕亮度/对比度调节方法大全03-02
下一篇:
相关推荐
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-

雷神推出 MIX PRO II 迷你主机:基于 Ultra 200H,玻璃上盖 + ARGB 灯效
2 月 9 日消息,雷神 (THUNDEROBOT) 现已宣布推出基于英
-

制造商 Musnap 推出彩色墨水屏电纸书 Ocean C:支持手写笔、第三方安卓应用
2 月 10 日消息,制造商 Musnap 现已在海外推出一款 Oce

热文推荐
- 基于MaxCompute InformationSchema进行血缘关系分析
- 腾讯云SQL Server 性能逆天,252万TPM国内无对手!
腾讯云SQL Server 性能逆天,252万TPM国内无对手!
26-03-02 - wait_type SOS_WORKER导致数据库连接失败

wait_type SOS_WORKER导致数据库连接失败
26-03-02 - 电脑桌面图标变大恢复调小图文教程

电脑桌面图标变大恢复调小图文教程
26-03-02 - Intel英特尔Core i9-11900H跑分及参数性能详解

Intel英特尔Core i9-11900H跑分及参数性能详解
26-03-02 - 电脑屏幕亮度/对比度调节方法大全

电脑屏幕亮度/对比度调节方法大全
26-03-02 - Intel英特尔Core i7-11390H跑分及参数一览表

Intel英特尔Core i7-11390H跑分及参数一览表
26-03-02 - Intel英特尔Core i7-11800H跑分及参数一览表

Intel英特尔Core i7-11800H跑分及参数一览表
26-03-02 - sqlserver服务启动失败-1067

sqlserver服务启动失败-1067
26-03-02 - 在 Flink 算子中使用多线程如何保证不丢数据?

在 Flink 算子中使用多线程如何保证不丢数据?
26-03-02