1 、数据同步需求
自动识别源表中数据所归属的分公司进行自动同步,即将源表中 A 分公司的数据同步到A 公司数据库表,源表中B 分公司的数据同步到B 公司数据库表,以此类推。
2 、实现思路
l 一般ETL工具实现思路: 建立同步到A分公司流程,抽取源表数据 ->过滤出 A分公司 ->将过滤后的数据加载到 A公司数据库表。再建立同步到 B分公司流程,有多少个分公司就建立多少条流程。
缺点:开发工作量随分公司数量成正比,当所有表存在变更时需要对所有 流程进行修改,日常运行监控、维护困难。
优点:当某个分公司数据库表有变更时,只需要维护对应的流程,不影响其他流程。
l Restcloud ETL 工具实现思路: 创建1个主流程、 1个子流程,主流程用于获取需要同步的分公司并作为变量参数,并逐个输出给子流程。子流程获取主流程的变量参数作为数据过滤条件及动态获取对应目标数据源。
主流程工作原理:通过执行 SQL 脚本做Groupby 分组计算出要同步的分公司并作为变量参数,利用【逐行拆分输出组件】控制循环调用子流程,逐个将变量参数传送给子流程。

创建 1 个子流程,获取主流程输出数据作为参数条件抽取需要同步的数据,及需要调取的数据源。

缺点:存在一定限制,如要求所有分公司的表名称、表结构相同。
优点:工作量小,日常运行监控、维护便捷。
3 、示例
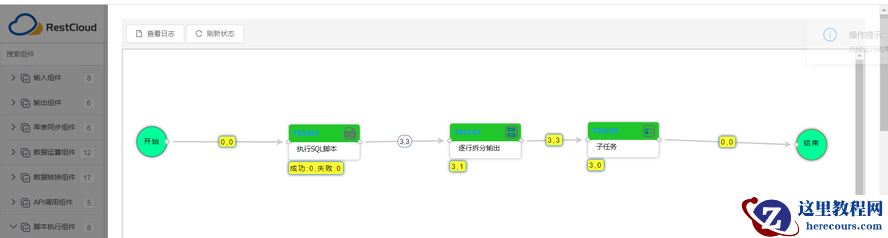
3 .1 建立主流程
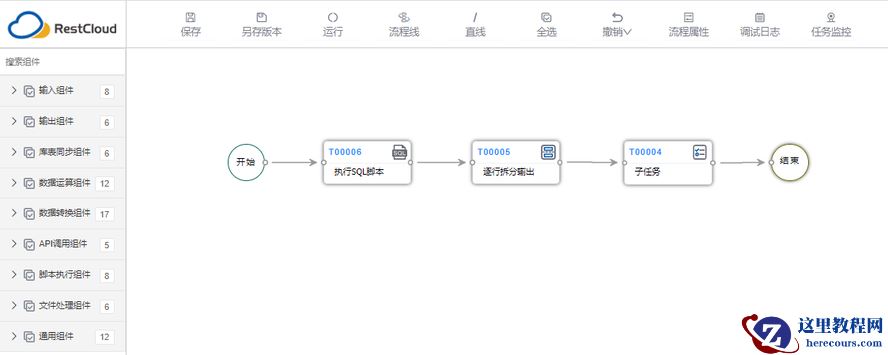
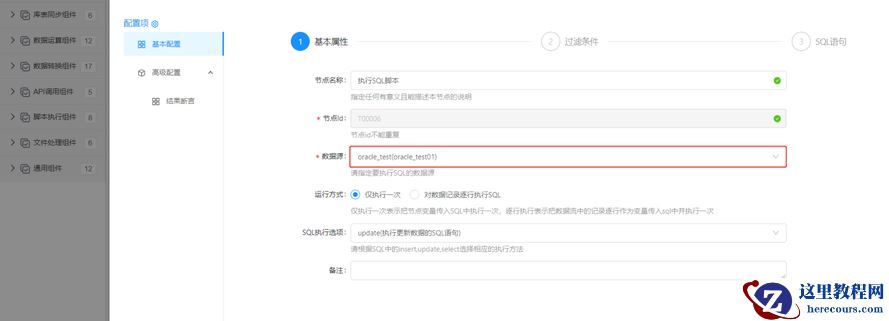
3.1.1 配置【执行SQL脚本】组件
配置基本属性:指定读取源表的数据源
配置过滤条件:此处无需过滤数据,下一步跳过该项配置
配置SQL 语句 : 编写SQL 已经做 Groupby 分组计算出要同步的分公司并作为变量参数。
如果有存储分公司名单与数据源对应代码表,此处可以直接用【表输入】组件获取
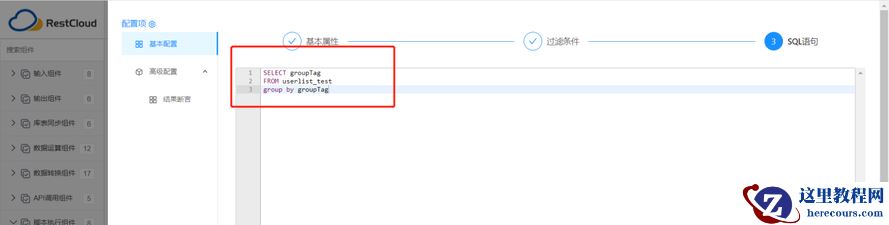
保存退出,完成【执行SQL 脚本】配置。
3 .1.2 配置【逐行拆分输出】组件
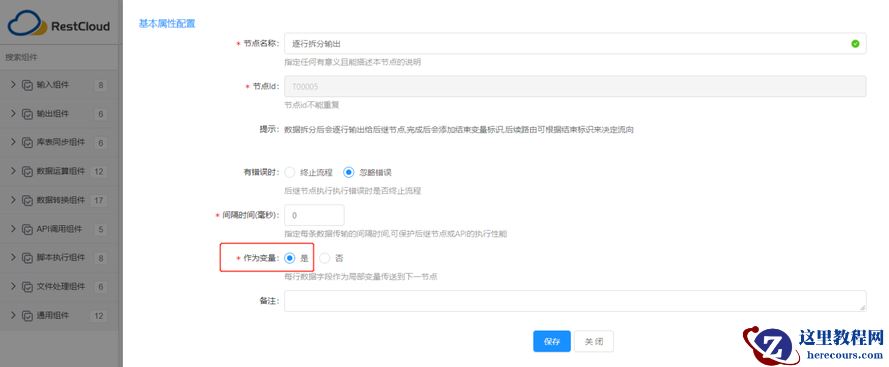
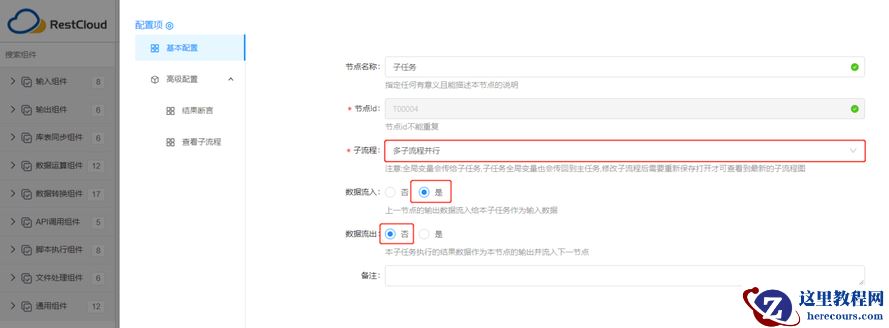
3 .1.3 配置【子任务】组件
选择已配置后的子流程,选择数据流入(接收主流程输出数据)
3 .2 建立子流程
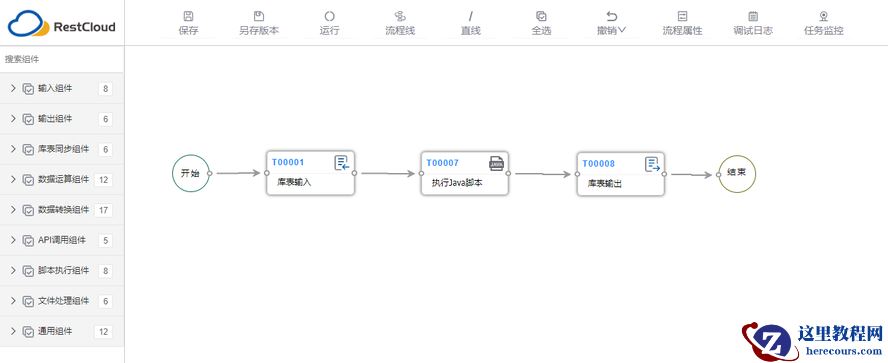
3 .2.1 配置【库表输入】
配置基本属性:指定读取源表的数据源
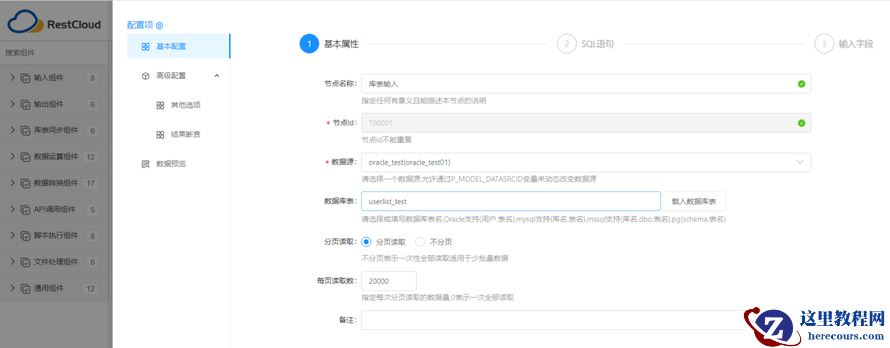
配置SQL 语句:增加数据过滤条件参数
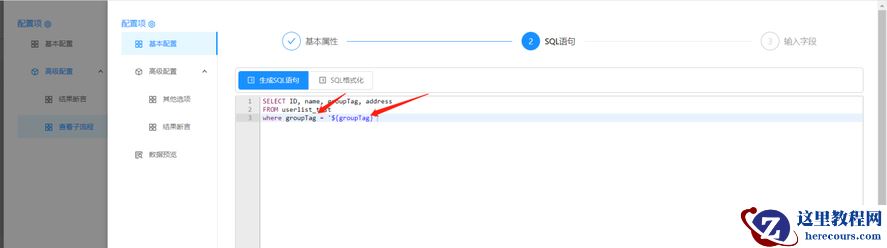
配置输入字段:系统自动读取,无需配置。直接点击保存退出完成 【库表输入】组件配置。
3 .2.2 配置【执行Java 脚本】
配置基本属性:无需修改配置,直接下一步。
配置Java 代码:代码逻辑(通过判断输入的参数值获取对应同步的目标数据源)
如输入参数A ,对应同步到数据源“ Stephen_MySql01 ” , Stephen_MySql01 为配置A 公司的的数据源名称。
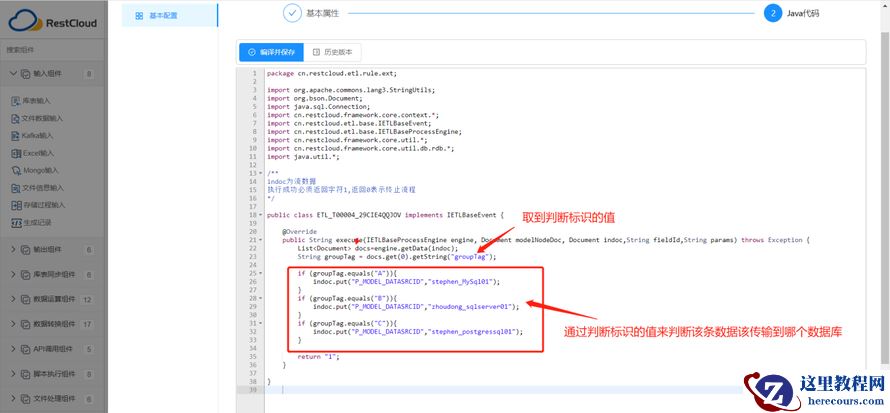
直接点击编译并保存,退出完成 【执行Java 脚本】组件配置
3 .2.3 配置【库表输出】
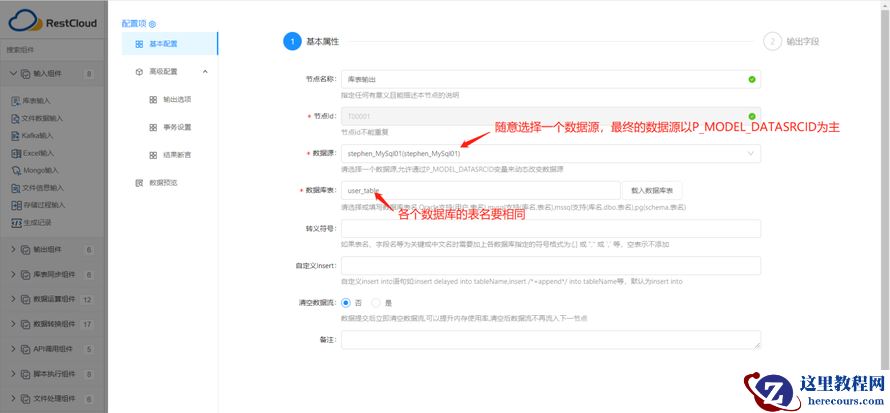
配置基本属性:指定读取源表的数据源(此处根据参数动态获取指定输出数据源)
配置输出字段:根据目标表的字段情况,手工点击新增列完成输出字段配置。
由于数据源是动态原因,流程在不运行情况下无法获取到对应表,因此无法自动获取表结构。
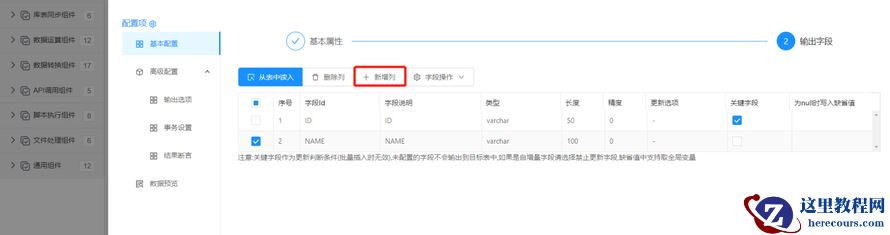
输出字段配置完成后,点击保存完成 【库表输出】配置。
3 .3 测试
3 .3.1 用例数据
源表数据如下:

3 .3.2 效果要求:
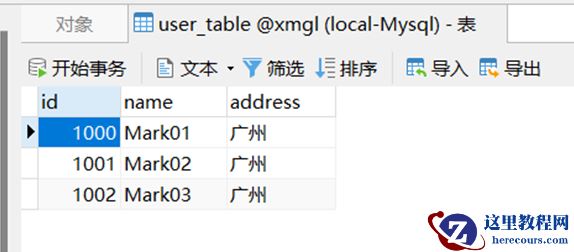
address 为“广州”的数据同步到 mysql数据库
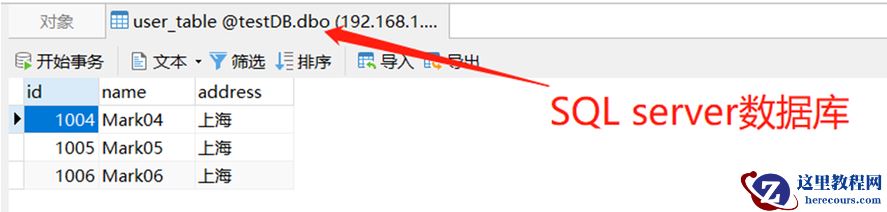
address 为“上海”的数据同步到 SQL serve 数据库
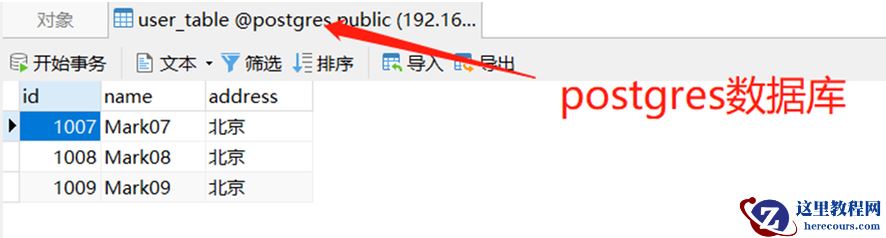
address 为“北京”的数据同步到 Postgres 数据库
3 .3.3 运行结果
数据库结果
标识为“广州”的,就将该条数据插入到 mysql 数据库
标识为 “上海” 的,就将该条数据插入到SQL server 数据库
标识为 “北京” 的,就将该条数据插入到postgres 数据库








")



