什么是分布式系统
拿一个最简单的例子,就比如说我们的图书管理系统。之前的系统包含了所有功能,比如用户注册登录、管理员功能、图书借阅管理等。这叫做集中式系统。也就是一个人干了好几件事。
后来随着功能的增多,用户量也越来越大。集中式系统维护太麻烦,拓展性也不好。于是就考虑着把这些功能分开。通俗的理解就是原本需要一个人干的事,现在分给n个人干,各自干各自的,最终取得和一个人干的效果一样。
稍微正规一点的定义就是:一个业务分拆多个子业务,部署在不同的服务器上。然后通过一定的通信协议,能够让这些子业务之间相互通信。
既然分给了n个人,那就涉及到这些人的沟通交流协作问题。想要去解决这些问题,就需要先聊聊分布式系统中的CAP理论。千万不要被这个看起来高大上的概念迷惑住。
CAP是什么
CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer’s theorem),指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)这三个基本需求,最多只能同时满足其中的2个。
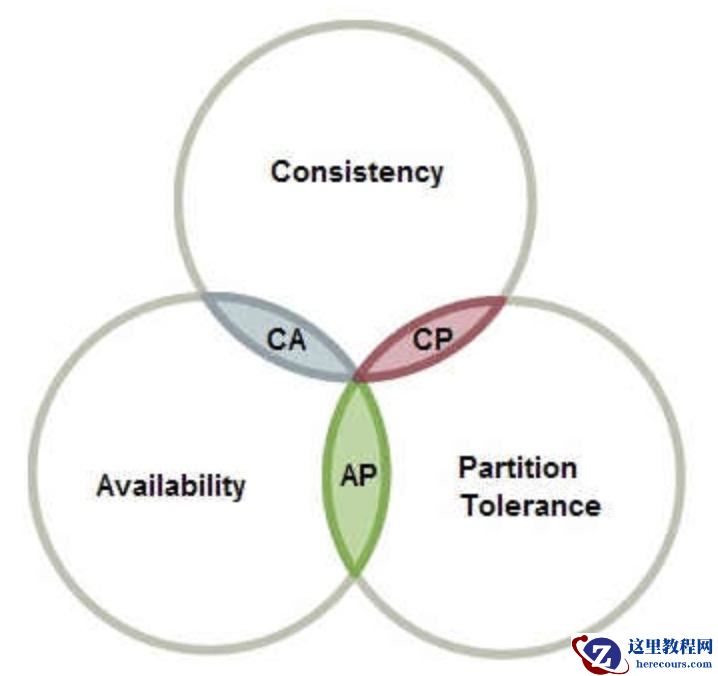
CAP的每个单项含义:
理解CAP理论的最简单方式是想象两个节点分处分区两侧:允许至少一个节点更新状态会导致数据不一致,即丧失了C性质。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了A性质。除非两个节点可以互相通信,才能既保证C又保证A,这又会导致丧失P性质。
论证CAP定理
通常来说,分区容错是无法避免的,因此可以认CA的P总是成立。CAP定理告诉我们,剩下的C和A无法同时做到,下面是一个详细的推论过程来展示CA之间的矛盾。
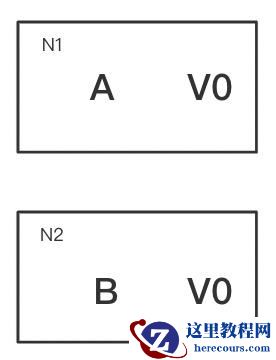
网络中有两个节点N1和N2,可以简单的理解N1和N2分别是两台计算机,他们之间网络可以连通,N1中有一个应用程序A,和一个数据库V,N2也有一个应用程序B和一个数据库V。现在,A和B是分布式系统的两个部分,V是分布式系统数据存储的两个子数据库。
此时假设用户向N1机器请求数据更新,程序A更新数据库V0为V1。分布式系统将数据进行同步操作M,将V1同步到N2中V0,使得N2中的数据V0也更新为V1,N2中的数据再响应N2的请求。
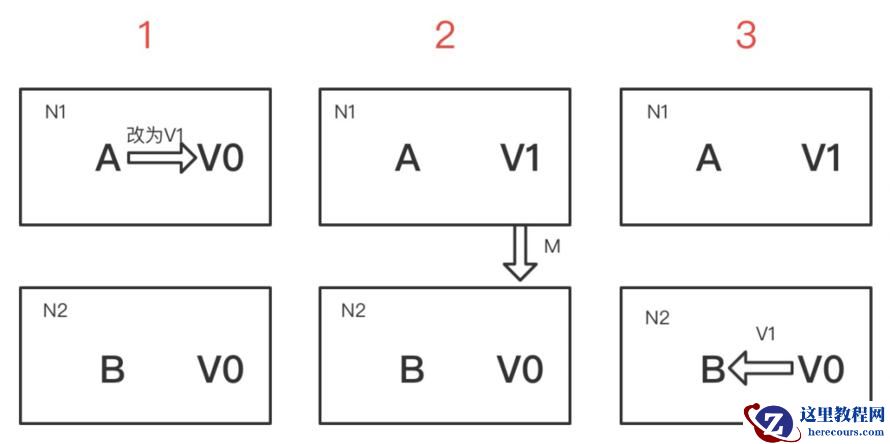
根据CAP原则定义,系统的一致性、可用性和分区容错性细分如下:
这是正常运作的场景,也是理想的场景。作为一个分布式系统,它和单机系统的最大区别,就在于网络。现在假设一种极端情况,N1和N2之间的网络断开了,我们要支持这种网络异常。相当于要满足分区容错性,能不能同时满足一致性和可用性呢?还是说要对他们进行取舍?
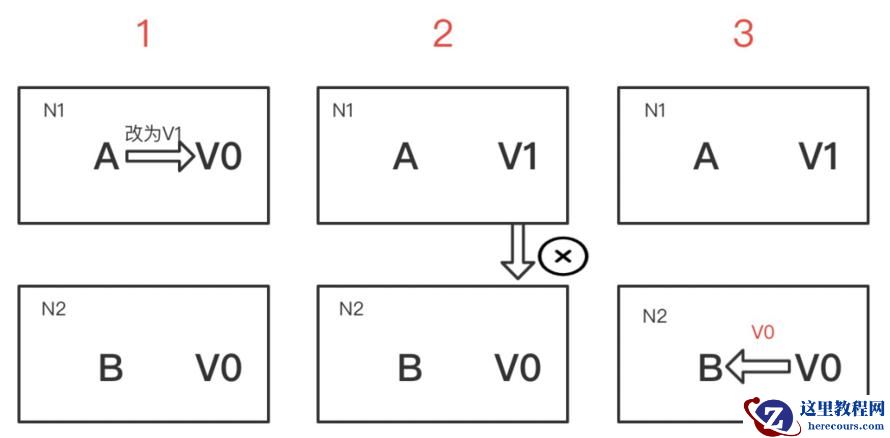
假设在N1和N2之间网络断开的时候,有用户向N1发送数据更新请求,那N1中的数据V0将被更新为V1。由于网络是断开的,所以分布式系统同步操作M无法进行,所以N2中的数据依旧是V0。这个时候,有用户向N2发送数据读取请求,由于数据还没有进行同步,应用程序没办法立即给用户返回最新的数据V1,怎么办呢?这里就有两种选择:
CAP原理的应用
互联网场景:
对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到N个9,即保证P和A,舍弃C(退而求其次保证最终一致性)。虽然某些地方会影响客户体验,但没达到造成用户流失的严重程度。
对于涉及到钱财这样不能有一丝让步的场景,C必须保证。网络发生故障宁可停止服务(或者只读不写),这是保证CA,舍弃P
数据库领域:
依据CAP理论,从应用的需求不同,我们选型数据库时,可以从三方面考虑:
下面是一张流传非常广泛的图,它展示了按照CAP中三选二对数据库系统的分类:
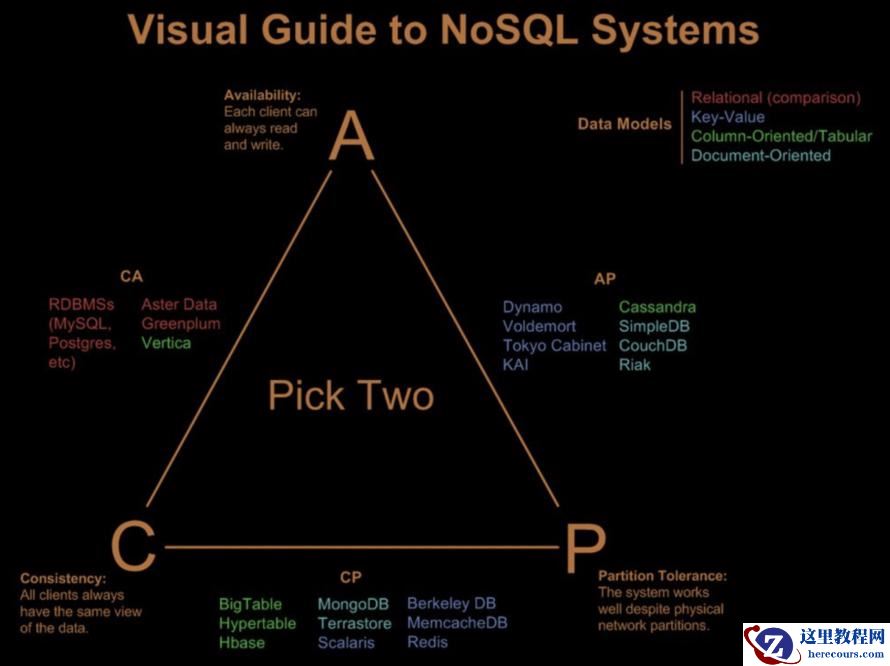
最后
我们明白了CAP的矛盾、原理、应用之后,在平时的工作中的取舍也就会更加清楚明了了,我们需要清楚什么场合下选用哪种特性。
举例来说,发布一张网页到 CDN,多个服务器有这张网页的副本。后来发现一个错误,需要更新网页,这时只能每个服务器都更新一遍。一般来说,网页的更新不是特别强调一致性。短时期内,一些用户拿到老版本,另一些用户拿到新版本,问题不会特别大。当然,所有人最终都会看到新版本。所以,这个场合就是可用性高于一致性。
大家也可以多思考一些其他特定的场景,然后分析一下到底应该选用哪种特性,欢迎留言讨论。





")






")