昨天聊了下 S QLSERVER 的 s pinlock ,当时我认为 s pinlock 是与 Oracle LATCH 相对应的结构,事实上碎片化的阅读会带来一些知识掌握的不准确。 Oracle的L ATCH 是通过 s pin 来实现锁的获取的, s pin 是 L ATCH 获取轻量级锁的一种方式。而在 SQLSERVER 中, L ATCH 和 s pinlock 被设计成两种轻量级锁,分别用于不同的场景。 Oracle有 shared pool , l ibrary cache 等结构,可以用 s hared pool 闩锁来保护整个共享池,共享池中新增的一些乱七八糟的数据结构可以通过 s hared pool 闩锁以及 m utex 来实现串行化访问保护。
S QLSERVER 中并无此类机制,因此对于一些重度访问的内存结构,设计了 L ATCH 来保护,而其他的一些数据结构,使用 s pinlock 。在 S QLSERVER 中,总是使用 s pinlock 来保护那些访问十分快速的内存结构。
L ATCH 是 SQL Server 的 S QL引擎用来保证内存结构的一致性的轻量级 原子操作用来保护 索引、数据页和内部结构 等结构, 例如 B 树中的非叶页。 L ATCH 仅存在于 S QL 引擎内部。 SQL Server 使用缓冲 L ATCH来保护缓冲池中的页面,并使用 I/O LATCH来保护尚未加载到缓冲池中的页面。每当向 SQL Server 缓冲池中的页面写入或读取数据时,工作线程必须首先获取该页面的缓冲 L ATCH。有多种缓冲 L ATCH类型可用于访问缓冲池中的页面,包括独占 L ATCH (PAGELATCH_EX) 和共享 L ATCH(PAGELATCH_SH)。
当 SQL Server 访问一个尚未加载到缓冲池中的页面时,将通过一个异步 I/O 操作 将该页面加载到缓冲池中。如果 SQL Server 需要等待 I/O 子系统响应,它将根据请求类型等待独占 (PAGEIOLATCH_EX) 或共享 (PAGEIOLATCH_SH) I/O LATCH;这样做是为了防止另一个工作线程使用不兼容的 L ATCH将同一页面加载到缓冲池中。 L ATCH还用于保护对缓冲池页面以外的内部存储器结构的访问;这些被称为非缓冲 L ATCH。
P AGELATCH 的争用在多 CPU 系统 十分常见。当多个线程同时尝试获取相同内存结构的不兼容 L ATCH 时,就会发生 L ATCH 争用。闩锁是一种内部并发控制机制, SQL 引擎会自动确定何时使用它们。因为 闩锁 的行为是确定性的, 数据库 S CHEMA 的设计,表、索引等的设计会影响闩锁争用 。
非缓存页的闩锁名称为 L ATCH_XX ,其中 “_ XX ”后缀表示了闩锁的模式(P AGEIOLATCH/PAGELATCH 也使用后缀表示模式)。 SQL Server 的 闩锁 模式可以总结如下:
l KP—— 保持 L ATCH ,确保引用的结构不会被破坏。当线程想要查看缓冲区结构时使用。因为 KP LATCH 兼容除销毁( DT )之外的所有 L ATCH ,因此 KP 闩锁被认为是 “ 轻量级 ” 的,这意味着使用它时对性能的影响最小。由于 KP 闩锁与 DT 闩锁不兼容,它会阻止任何其他线程破坏引用的结构。 KP 闩锁将防止它引用的结构被 lazywriter 进程破坏 (脏块写盘并释放缓冲);
l SH -- 共享闩锁,需要读取引用的结构(例如读取数据页)。多个线程可以同时访问共享闩锁下的资源以进行读取。
l UP—— 更新闩锁,与 SH (共享闩锁)和 KP 兼容,但不兼容其他闩锁,因此不允许 EX 闩锁写入引用的结构。
l EX—— 独占闩锁,阻止其他线程写入或读取引用的结构。一个使用示例是修改页面内容以保护页面 损坏 。
l DT -- 销毁闩锁,必须在销毁引用结构的内容之前获取。例如, lazywriter 进程必须获取一个 DT 闩锁以释放一个干净的页面,然后再将其添加到可供其他线程使用的空闲缓冲区列表中。
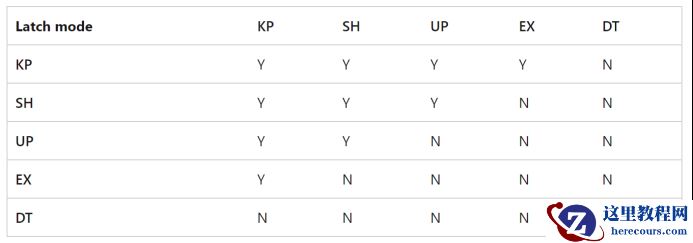

上面的描述中关于闩锁兼容性的描述,可以用上表来表示。如果我们看到一个闩锁,可以通过 ”_” 之后的后缀来区分其模式。比如 P AGEIOLATCH_EX 是一个独享的 P AGEIOLATCH , L ATCH_DT 是一个非缓冲区保护的销毁闩锁。
和 Oracle的子闩锁类似,S QLSERVER 也存在类似的结构,称为 s uperlatch 或者 s ublatch 。目的是使用多个子闩锁来提高闩锁的并发性能。 S QLSERVER 使用多线程结构,并采用缓冲区动态扩展的方式。因此 s uperlatch 机制与 N UMA 架构做了一些优化,使之更好的适应 N UMA 。
随着基于 NUMA 的 多路 / 多核系统的出现越来越多, SQL Server 2005 开始 引入了 SuperLatches ,也称为子闩锁, s uperlatch 仅在具有 32 个或更多逻辑处理器的系统上 自动启用 。Superlatch 提高了 SQL 引擎在高并发 OLTP 工作负载中某些 场景的 效率;例如,当某些页面具有重度只读共享 (SH) 访问模式,但很少写入。具有这种访问模式的页面的一个示例是 B 树(即索引)根页面; SQL 引擎要求在 B 树中的任何级别发生页面拆分时,在根页面上保留一个共享闩锁。在插入繁重和高并发的 OLTP 工作负载中,页面拆分的数量将随着吞吐量的增加而大幅增加,这会降低性能。
SuperLatches 可以提高访问共享页面的性能,其中多个并发运行的工作线程需要 SH 闩锁。为此, SQL Server 引擎会将此类页面上的闩锁动态提升为 SuperLatch 。
SuperLatch 将单个闩锁划分为一组子闩锁结构,每个 CPU 内核 分配一个 子闩锁,因此主闩锁成为代理重定向器,只读闩锁不需要全局状态同步。这样做时, 访问某个内存 总是分配给特定 CPU 的 worker 线程 只需要获取分配给本地调度程序的共享 (SH) 子闩锁。
在为 大型服务器 设计的高吞吐量系统上, 必定 会出现高并发 的闩锁 争用, 在此类系统中存在闩锁争用是十分正常的现象 。但是当闩锁争用和闩锁等待类型等待时间大到足以降低 CPU 利用率的情况 下,系统的整体吞吐量会严重下降。 识别和识别闩锁争用的迹象很重要,所以让我们 必须有能力来分析这种情况。 SQL Server 闩锁的预期行为(与每秒事务数相关)是每秒事务数将随着平均 SQL Server 闩锁等待时间的增加而增加,其本身以缓慢的速度增加 。如果数据库并发增长的趋势与闩锁等待的趋势十分接近,那么闩锁争用并没有产生额外的负面影响。如果闩锁等待幅度远远超过数据库负载的增长,那么就说明闩锁出现了严重的争用。这个判断原则在大多数情况下是有效的。
我已经比较长时间没有仔细阅读数据库厂商官方的白皮书了,通过这两天的学习,我学到了一个分析数据的方法。实际上有些指标之间是存在较为同步的关联关系的,通过上升或者下降的幅度(可以通过统计学方法计算出一个可评估的度量)之间的对比,可以发现一些系统的性能问题。以前我们做了一个指标关联性分析工具,用于发现数据库某个指标异常可能存在的问题。实际上用这种更为简单的算法,也可以发现系统中存在的一些背离预期行为的场景,并用于告警。
可能有朋友有些疑问,高并发必然有 L ATCH 争用,必然有 s pinlock 问题,为什么还要去这么较真的分析其原理呢?分析闩锁与 s pinlock 的一些原理的问题并不是仅仅为了分析原理,而是要更好的用到诊断中。通过理解这些内部原理,我们可以更好的了解 S QL SERVER 的缓存区、 I O 、 S QL 引擎的工作原理,掌握 S QL SERVER 复杂问题的分析诊断与问题溯源的能力。
通过这几天的 S QL SERVER 内部原理的一些零散的学习,在我的脑子里 S QL SERVER 与 Oracle 的差别越来越清晰。分析问题的时候,既可以运用 Oracle 的一些已知原理去分析 S QL SERVER 的问题,又可以不僵化的刻舟求剑。今天早上我重新梳理了一下 S QL SERVER IO 问题分析的诊断思路,为这个思维导图增加了一些细节。
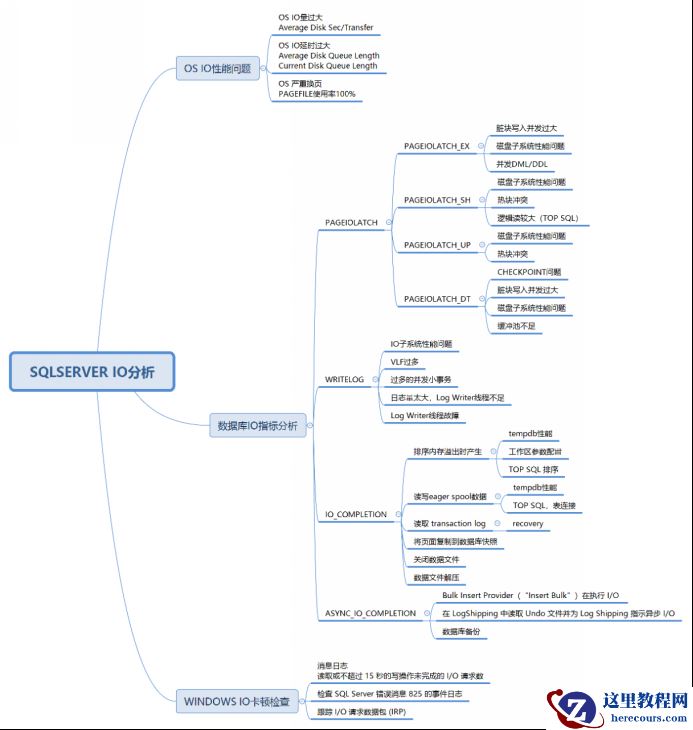 利用上面这张图去分析
S
QL SERVER
的问题,基本上能够覆盖大部分常见问题了。我们将把这个知识图谱建立在
D
-SMART
中。利用自动化工具来自动分析
S
QL SERVER
的
IO
性能问题。实际上大多数知识图谱都是通过这样的方法构建出来的。有一些是基于专家经验,有一些是基于官方文档,有一些是基于生产环境中遇到的案例与实践。
利用上面这张图去分析
S
QL SERVER
的问题,基本上能够覆盖大部分常见问题了。我们将把这个知识图谱建立在
D
-SMART
中。利用自动化工具来自动分析
S
QL SERVER
的
IO
性能问题。实际上大多数知识图谱都是通过这样的方法构建出来的。有一些是基于专家经验,有一些是基于官方文档,有一些是基于生产环境中遇到的案例与实践。












