关联比赛: 首届中文NL2SQL挑战赛
1. 任务描述
本次比赛的任务:根据Question、表格信息(包含列名、列类型、内容),预测对应的SQL语句(下图黄色部分)。比赛只涉及单表查询,需要预测的有4部分:挑选的列(sel),列上的聚合函数(agg),筛选的条件(conds),及条件间的关系(cond_conn_op)。
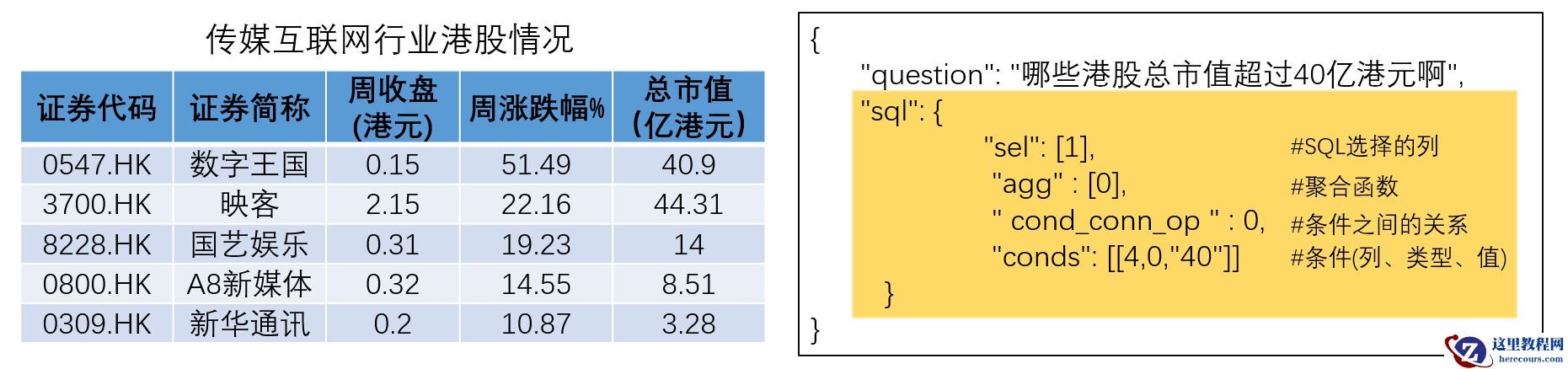
本次赛题将提供4万条有标签数据作为训练集,1万条无标签数据作为测试集。其中,5千条测试集数据作为初赛测试集,对选手可见;5千条作为复赛测试集,对选手不可见。
2. 评价指标
比赛的评分标准包括: Logic Form Accuracy: 预测完全正确的SQL语句。其中,列的顺序并不影响准确率的计算。 Execution Accuracy: 预测的SQL的执行结果与真实SQL的执行结果一致。排行榜以$Score_{lf}$与$Score_{ex}$的平均值排序。
3. 难点分析
NL2SQL方向有很多有代表性的数据集,任务最合适的类比数据集就是2017年salesforce提出的WikiSQL数据集,包含8w多数据和2w多表格。不过与其相比,此次比赛的数据集有4点不同:
不限制使用表格内容信息
存在conds value不能从question提取的样本
select agg存在多项
没有conds缺失的样本
其中影响最大的就是train中25%左右样本conds value不能直接从question提取。下表是我们对样本集的一些参数的分析,包括问题长度, 表格列数目 列总长度 最多sel和最多cond数目,这些参数决定了模型的超参数如何设置。
4. 解题方案
我们拆解出多个子任务:
把sel与agg结合当作多分类问题;
把cond_conn_op当作多分类问题;
把conds当作一个比较复杂的抽取问题
我们构建了多种类型神经网络模型,将这些任务进行联合学习。

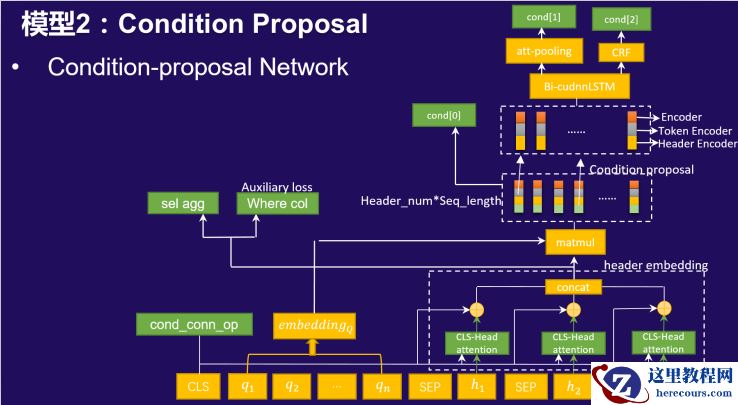
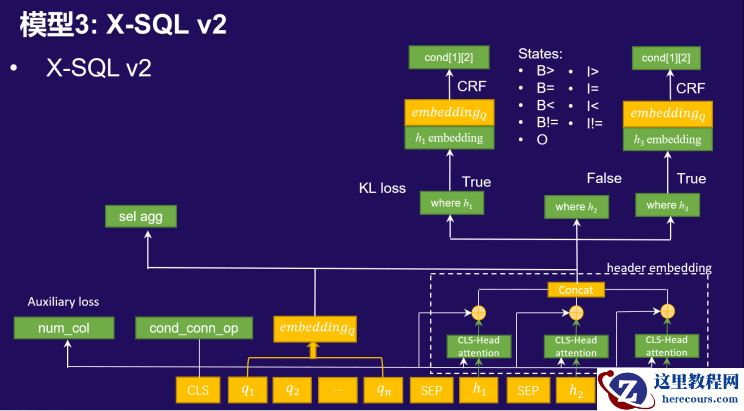
改进点
使用了12层transformer动态权重融合,极大的增强了模型的编码能力;
通过列的shuffle进行数据增强,提高了模型的鲁棒性,对于sel、cond的列选择准确率有很好的提升效果;
针对conds value不能从question提取的样本的问题,我们使用纯净的数据(conds value多能从question提取)训练模型。然后用训练好的模型预测不能提取的这批数据,选择置信度高的结果当作类标;
在X-SQL的基础上,增加辅助任务。比如预测sel、cond的数目,可以作为我们后续融合的过滤条件。这两个任务的预测效果都非常好,可以达到99%以上。
5. 结果
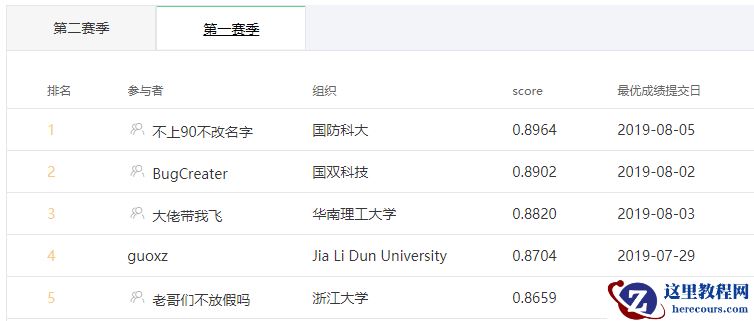
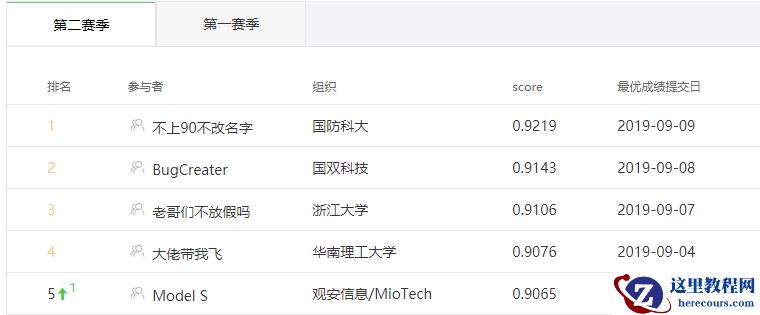
查看更多内容,欢迎访问天池技术圈官方地址: 首届中文NL2SQL挑战赛亚军比赛攻略_BugCreater_天池技术圈-阿里云天池
编辑推荐:
相关推荐
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-

雷神推出 MIX PRO II 迷你主机:基于 Ultra 200H,玻璃上盖 + ARGB 灯效
2 月 9 日消息,雷神 (THUNDEROBOT) 现已宣布推出基于英
-

制造商 Musnap 推出彩色墨水屏电纸书 Ocean C:支持手写笔、第三方安卓应用
2 月 10 日消息,制造商 Musnap 现已在海外推出一款 Oce









