索引大家可以理解为一本书里的目录,方便大家快速定位到自己要的章节,哪么在数据库里也一样,如果一个表数据有
1000
行数据,如何更快的查询到满足条件的记录,哪么索引就可以派上用场了,索引跟表一样,有自己的存储空间,只是表现形式不一样。
索引有很多种:分区和非分区索引、常规
B
树索引、位图(
bitmap
)索引、翻转(
reverse
)索引等。其中,
B
树索引属于最常见的索引,今天我们讲解下
B
树索引的原理。
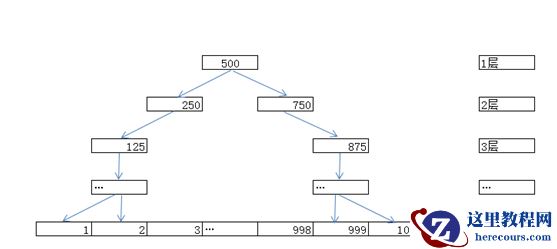 上图是表示有
1000
行记录的二叉树结构,从顶层根节点到底层叶节点一共只有
10
层
,假设我们只要查询
ID=600
这行,如果在没有索引情况下,要对表做整表扫描,从第
1
行开始扫,发现
ID=1
条件不成立,继续扫第二行,直到最后一行,相当于扫描了
1000
行,大家可能不理解为什么扫描到第
600
行后还要扫描呢,因为系统不知道是否有重复的
ID=600
记录呀,所以必须全部扫描后再返回数据,哪现在我们有了索引,系统是如何快速找到记录的呢,数据库系统会维护上图的这样一个结构,首先找根节点发现
600>500,
则往右边找下一层(第二层),
600<750
,则往左边找下一层。整个过程如下:
500->750->625->562->594->……->600
整个过程只要了
10
次,所以一下就从
1000
次减到只要
10
次了,是不是效率上来了,不过在工业中,我们的记录会要多得多,要是有
1
亿条呢,按这种情况也要查询
30
次以上了,效率也慢下来了,就有了
B+
树,就是在每一层中不是只做二叉,而是做多叉分开。如下图:
上图是表示有
1000
行记录的二叉树结构,从顶层根节点到底层叶节点一共只有
10
层
,假设我们只要查询
ID=600
这行,如果在没有索引情况下,要对表做整表扫描,从第
1
行开始扫,发现
ID=1
条件不成立,继续扫第二行,直到最后一行,相当于扫描了
1000
行,大家可能不理解为什么扫描到第
600
行后还要扫描呢,因为系统不知道是否有重复的
ID=600
记录呀,所以必须全部扫描后再返回数据,哪现在我们有了索引,系统是如何快速找到记录的呢,数据库系统会维护上图的这样一个结构,首先找根节点发现
600>500,
则往右边找下一层(第二层),
600<750
,则往左边找下一层。整个过程如下:
500->750->625->562->594->……->600
整个过程只要了
10
次,所以一下就从
1000
次减到只要
10
次了,是不是效率上来了,不过在工业中,我们的记录会要多得多,要是有
1
亿条呢,按这种情况也要查询
30
次以上了,效率也慢下来了,就有了
B+
树,就是在每一层中不是只做二叉,而是做多叉分开。如下图:
 做了
8
叉树后我们的层级只要
4
层了,这样对大数据记录访问的次数就减少了。
优点:
1
:快速查询我们需要的数据,比如
ID=600
。
2
:对范围查询也能很快查询出来,比如
ID>500 AND ID<600
,因为在索引里已是一个排序的记录,找到最少的一条后,直接读取索引的下一条,直到条件不成立。
缺点:因为系统要维护这个索引,增加存储空间,维护资源,在做表插入和删除记录时会影响性能。
做了
8
叉树后我们的层级只要
4
层了,这样对大数据记录访问的次数就减少了。
优点:
1
:快速查询我们需要的数据,比如
ID=600
。
2
:对范围查询也能很快查询出来,比如
ID>500 AND ID<600
,因为在索引里已是一个排序的记录,找到最少的一条后,直接读取索引的下一条,直到条件不成立。
缺点:因为系统要维护这个索引,增加存储空间,维护资源,在做表插入和删除记录时会影响性能。
语法:
CREATE
INDEX
index_name
ON
table
(
column
[,
column
]...);
CREATE
INDEX
idx_t_sales_user_no
ON
t_sales (user_no);
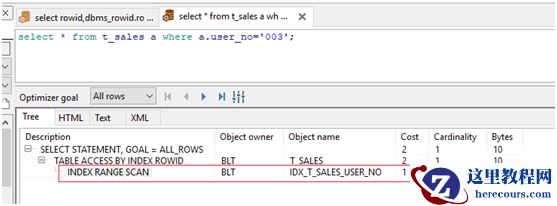
我们再来看下查询有索引字段脚本的执行计划,标红色的表示我们这个脚本是有走索引的。
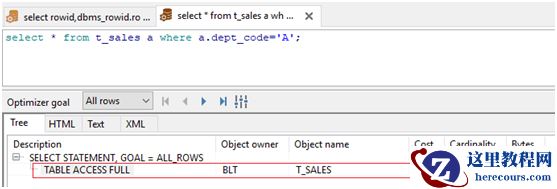
 下面是执行一个没有索引字段的脚本,执行计划是全表扫描了。
下面是执行一个没有索引字段的脚本,执行计划是全表扫描了。










![实战演练丨SCN太大引发ORA-600[2252]](https://www.herecours.com/d/file/efpub/2026/03-03/20260303130611831800.jpg?x-oss-process=style/bb "实战演练丨SCN太大引发ORA-600[2252]")

")