导读
明代著名的心学集大成者王阳明先生在《传习录》中有云:
道无精粗,人之所见有精粗。如这一间房,人初进来,只见一个大规模如此。处久,便柱壁之类,一一看得明白。再久,如柱上有些文藻,细细都看出来。然只是一间房。
是的,知识理论哪有什么精粗之分,只是人的认识程度不同而已。笔者在初创公司摸爬滚打数年,接触了各式各样的Java服务端架构,见得多了自然也就认识深了,就能分辨出各种方案的优劣了。这里,笔者总结了一些初创公司存在的Java服务端问题,并尝试性地给出了一些不成熟的解决方案。
1.系统不是分布式
随着互联网的发展,计算机系统早就从单机独立工作过渡到多机器协同工作。计算机以集群的方式存在,按照分布式理论构建出庞大复杂的应用服务,早已深入人心并得到广泛地应用。但是,仍然有不少创业公司的软件系统停留在"单机版"。
1.1.单机版系统抢单案例
这里,用并发性比较高的抢单功能为例说明:
// 抢取订单函数
public synchronized void grabOrder(Long orderId, Long userId) {
// 获取订单信息
OrderDO order = orderDAO.get(orderId);
if (Objects.isNull(order)) {
throw new BizRuntimeException(String.format("订单(%s)不存在", orderId));
}
// 检查订单状态
if (!Objects.equals(order.getStatus, OrderStatus.WAITING_TO_GRAB.getValue())) {
throw new BizRuntimeException(String.format("订单(%s)已被抢", orderId));
}
// 设置订单被抢
orderDAO.setGrabed(orderId, userId);
}
以上代码,在一台服务器上运行没有任何问题。进入函数grabOrder(抢取订单)时,利用synchronized关键字把整个函数锁定,要么进入函数前订单未被人抢取从而抢取订单成功,要么进入函数前订单已被抢取导致抢取订单失败,绝对不会出现进入函数前订单未被抢取而进入函数后订单又被抢取的情况。
但是,如果上面的代码在两台服务器上同时运行,由于Java的synchronized关键字只在一个虚拟机内生效,所以就会导致两个人能够同时抢取一个订单,但会以最后一个写入数据库的数据为准。所以,大多数的单机版系统,是无法作为分布式系统运行的。
1.2.分布式系统抢单案例
添加分布式锁,进行代码优化:
// 抢取订单函数
public void grabOrder(Long orderId, Long userId) {
Long lockId = orderDistributedLock.lock(orderId);
try {
grabOrderWithoutLock(orderId, userId);
} finally {
orderDistributedLock.unlock(orderId, lockId);
}
}
// 不带锁的抢取订单函数
private void grabOrderWithoutLock(Long orderId, Long userId) {
// 获取订单信息
OrderDO order = orderDAO.get(orderId);
if (Objects.isNull(order)) {
throw new BizRuntimeException(String.format("订单(%s)不存在", orderId));
}
// 检查订单状态
if (!Objects.equals(order.getStatus, OrderStatus.WAITING_TO_GRAB.getValue())) {
throw new BizRuntimeException(String.format("订单(%s)已被抢", orderId));
}
// 设置订单被抢
orderDAO.setGrabed(orderId, userId);
}
优化后的代码,在调用函数grabOrderWithoutLock(不带锁的抢取订单)前后,利用分布式锁orderDistributedLock(订单分布式锁)进行加锁和释放锁,跟单机版的synchronized关键字加锁效果基本一样。
1.3.分布式系统的优缺点
分布式系统(Distributed System)是支持分布式处理的软件系统,是由通信网络互联的多处理机体系结构上执行任务的系统,包括分布式操作系统、分布式程序设计语言及其编译系统、分布式文件系统分布式数据库系统等。
分布式系统的优点:
-
可靠性、高容错性:
一台服务器的崩溃,不会影响其它服务器,其它服务器仍能提供服务。
-
可扩展性:
如果系统服务能力不足,可以水平扩展更多服务器。
-
灵活性:
可以很容易的安装、实施、扩容和升级系统。
-
性能高:
拥有多台服务器的计算能力,比单台服务器处理速度更快。
-
性价比高:
分布式系统对服务器硬件要求很低,可以选用廉价服务器搭建分布式集群,从而得到更好的性价比。
分布式系统的缺点:
-
排查难度高:
由于系统分布在多台服务器上,故障排查和问题诊断难度较高。
-
软件支持少:
分布式系统解决方案的软件支持较少。
-
建设成本高:
需要多台服务器搭建分布式系统。
曾经有不少的朋友咨询我:"找外包做移动应用,需要注意哪些事项?"
首先,确定是否需要用分布式系统。软件预算有多少?预计用户量有多少?预计访问量有多少?是否只是业务前期试水版?单台服务器能否解决?是否接收短时间宕机?……如果综合考虑,单机版系统就可以解决的,那就不要采用分布式系统了。因为单机版系统和分布式系统的差别很大,相应的软件研发成本的差别也很大。
其次,确定是否真正的分布式系统。分布式系统最大的特点,就是当系统服务能力不足时,能够通过
水平扩展的方式,通过增加服务器来增加服务能力。然而,单机版系统是不支持水平扩展的,强行扩展就会引起一系列数据问题。由于单机版系统和分布式系统的研发成本差别较大,市面上的外包团队大多用单机版系统代替分布式系统交付。那么,如何确定你的系统是真正意义上的分布式系统呢?从软件上来说,是否采用了
分布式软件解决方案;从硬件上来说,是否采用了
分布式硬件部署方案。
1.4.分布式软件解决方案
作为一个合格的分布式系统,需要根据实际需求采用相应的分布式软件解决方案。
1.4.1.分布式锁
分布式锁是单机锁的一种扩展,主要是为了锁住分布式系统中的物理块或逻辑块,用以此保证不同服务之间的逻辑和数据的一致性。
目前,主流的分布式锁实现方式有3种:
-
基于数据库实现的分布式锁;
-
基于Redis实现的分布式锁;
-
基于Zookeeper实现的分布式锁。
1.4.2.分布式消息
分布式消息中间件是支持在分布式系统中发送和接受消息的软件基础设施。常见的分布式消息中间件有ActiveMQ、RabbitMQ、Kafka、MetaQ等。
MetaQ(全称Metamorphosis)是一个高性能、高可用、可扩展的分布式消息中间件,思路起源于LinkedIn的Kafka,但并不是Kafka的一个拷贝。MetaQ具有消息存储顺序写、吞吐量大和支持本地和XA事务等特性,适用于大吞吐量、顺序消息、广播和日志数据传输等场景。
1.4.3.数据库分片分组
针对大数据量的数据库,一般会采用"分片分组"策略:
分片(shard):主要解决扩展性问题,属于水平拆分。引入分片,就引入了数据路由和分区键的概念。其中,
分表解决的是数据量过大的问题,
分库解决的是数据库性能瓶颈的问题。
分组(group):主要解决可用性问题,通过
主从复制的方式实现,并提供
读写分离策略用以提高数据库性能。
1.4.4.分布式计算
分布式计算( Distributed computing )是一种"把需要进行大量计算的工程数据分割成小块,由多台计算机分别计算;在上传运算结果后,将结果统一合并得出数据结论"的科学。
当前的高性能服务器在处理海量数据时,其计算能力、内存容量等指标都远远无法达到要求。在大数据时代,工程师采用廉价的服务器组成分布式服务集群,以集群协作的方式完成海量数据的处理,从而解决单台服务器在计算与存储上的瓶颈。Hadoop、Storm以及Spark是常用的分布式计算中间件,Hadoop是对非实时数据做批量处理的中间件,Storm和Spark是对实时数据做流式处理的中间件。
除此之外,还有更多的分布式软件解决方案,这里就不再一一介绍了。
1.5.分布式硬件部署方案
介绍完服务端的分布式软件解决方案,就不得不介绍一下服务端的分布式硬件部署方案。这里,只画出了服务端常见的接口服务器、MySQL数据库、Redis缓存,而忽略了其它的云存储服务、消息队列服务、日志系统服务……
1.5.1.一般单机版部署方案
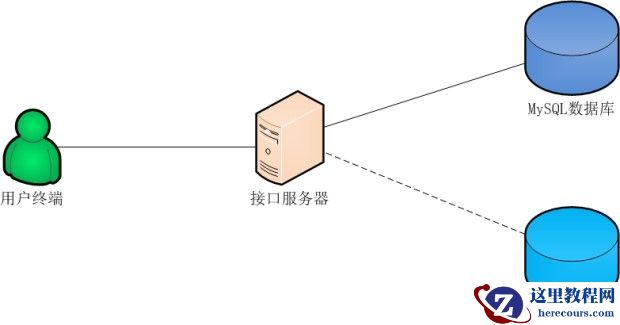 架构说明:
只有1台接口服务器、1个MySQL数据库、1个可选Redis缓存,可能都部署在同一台服务器上。
适用范围:
适用于演示环境、测试环境以及不怕宕机且日PV在5万以内的小型商业应用。
架构说明:
只有1台接口服务器、1个MySQL数据库、1个可选Redis缓存,可能都部署在同一台服务器上。
适用范围:
适用于演示环境、测试环境以及不怕宕机且日PV在5万以内的小型商业应用。
1.5.2.中小型分布式硬件部署方案
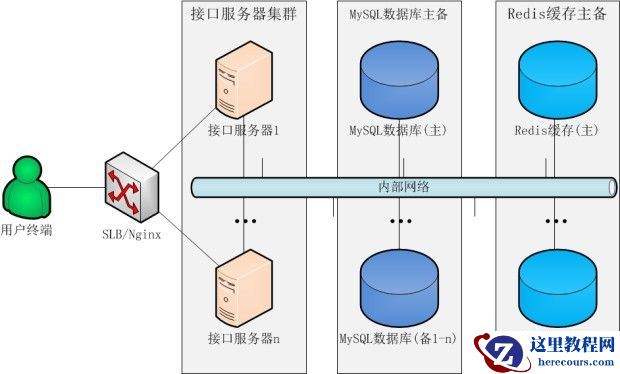 架构说明:
通过SLB/Nginx组成一个负载均衡的接口服务器集群,MySQL数据库和Redis缓存采用了一主一备(或多备)的部署方式。
适用范围:
适用于日PV在500万以内的中小型商业应用。
架构说明:
通过SLB/Nginx组成一个负载均衡的接口服务器集群,MySQL数据库和Redis缓存采用了一主一备(或多备)的部署方式。
适用范围:
适用于日PV在500万以内的中小型商业应用。
1.5.3.大型分布式硬件部署方案
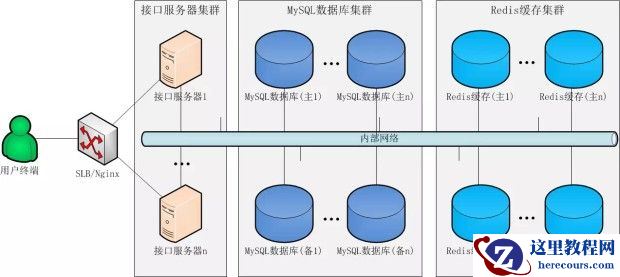 架构说明:
通过SLB/Nginx组成一个负载均衡的接口服务器集群,利用分片分组策略组成一个MySQL数据库集群和Redis缓存集群。
适用范围:
适用于日PV在500万以上的大型商业应用。
架构说明:
通过SLB/Nginx组成一个负载均衡的接口服务器集群,利用分片分组策略组成一个MySQL数据库集群和Redis缓存集群。
适用范围:
适用于日PV在500万以上的大型商业应用。
2.多线程使用不正确
多线程最主要目的就是"最大限度地利用CPU资源",可以把串行过程变成并行过程,从而提高了程序的执行效率。
2.1.一个慢接口案例
假设在用户登录时,如果是新用户,需要创建用户信息,并发放新用户优惠券。例子代码如下:
// 登录函数(示意写法)
public UserVO login(String phoneNumber, String verifyCode) {
// 检查验证码
if (!checkVerifyCode(phoneNumber, verifyCode)) {
throw new ExampleException("验证码错误");
}
// 检查用户存在
UserDO user = userDAO.getByPhoneNumber(phoneNumber);
if (Objects.nonNull(user)) {
return transUser(user);
}
// 创建新用户
return createNewUser(user);
}
// 创建新用户函数
private UserVO createNewUser(String phoneNumber) {
// 创建新用户
UserDO user = new UserDO();
...
userDAO.insert(user);
// 绑定优惠券
couponService.bindCoupon(user.getId(), CouponType.NEW_USER);
// 返回新用户
return transUser(user);
}
其中,绑定优惠券(bindCoupon)是给用户绑定新用户优惠券,然后再给用户发送推送通知。如果随着优惠券数量越来越多,该函数也会变得越来越慢,执行时间甚至超过1秒,并且没有什么优化空间。现在,登录(login)函数就成了名副其实的慢接口,需要进行接口优化。
2.2.采用多线程优化
通过分析发现,绑定优惠券(bindCoupon)函数可以异步执行。首先想到的是采用多线程解决该问题,代码如下:
// 创建新用户函数
private UserVO createNewUser(String phoneNumber) {
// 创建新用户
UserDO user = new UserDO();
...
userDAO.insert(user);
// 绑定优惠券
executorService.execute(()->couponService.bindCoupon(user.getId(), CouponType.NEW_USER));
// 返回新用户
return transUser(user);
}
现在,在新线程中执行绑定优惠券(bindCoupon)函数,使用户登录(login)函数性能得到很大的提升。但是,如果在新线程执行绑定优惠券函数过程中,系统发生重启或崩溃导致线程执行失败,用户将永远获取不到新用户优惠券。除非提供用户手动领取优惠券页面,否则就需要程序员后台手工绑定优惠券。所以,用采用多线程优化慢接口,并不是一个完善的解决方案。
2.3.采用消息队列优化
如果要保证绑定优惠券函数执行失败后能够重启执行,可以采用数据库表、Redis队列、消息队列的等多种解决方案。由于篇幅优先,这里只介绍采用MetaQ消息队列解决方案,并省略了MetaQ相关配置仅给出了核心代码。
消息生产者代码:
// 创建新用户函数
private UserVO createNewUser(String phoneNumber) {
// 创建新用户
UserDO user = new UserDO();
...
userDAO.insert(user);
// 发送优惠券消息
Long userId = user.getId();
CouponMessageDataVO data = new CouponMessageDataVO();
data.setUserId(userId);
data.setCouponType(CouponType.NEW_USER);
Message message = new Message(TOPIC, TAG, userId, JSON.toJSONBytes(data));
SendResult result = metaqTemplate.sendMessage(message);
if (!Objects.equals(result, SendStatus.SEND_OK)) {
log.error("发送用户({})绑定优惠券消息失败:{}", userId, JSON.toJSONString(result));
}
// 返回新用户
return transUser(user);
}
注意:可能出现发生消息不成功,但是这种概率相对较低。
消息消费者代码:
// 优惠券服务类
@Slf4j
@Service
public class CouponService extends DefaultMessageListener<String> {
// 消息处理函数
@Override
@Transactional(rollbackFor = Exception.class)
public void onReceiveMessages(MetaqMessage<String> message) {
// 获取消息体
String body = message.getBody();
if (StringUtils.isBlank(body)) {
log.warn("获取消息({})体为空", message.getId());
return;
}
// 解析消息数据
CouponMessageDataVO data = JSON.parseObject(body, CouponMessageDataVO.class);
if (Objects.isNull(data)) {
log.warn("解析消息({})体为空", message.getId());
return;
}
// 绑定优惠券
bindCoupon(data.getUserId(), data.getCouponType());
}
}
解决方案优点:
采集MetaQ消息队列优化慢接口解决方案的优点:
-
如果系统发生重启或崩溃,导致消息处理函数执行失败,不会确认消息已消费;由于MetaQ支持多服务订阅同一队列,该消息可以转到别的服务进行消费,亦或等到本服务恢复正常后再进行消费。
-
消费者可多服务、多线程进行消费消息,即便消息处理时间较长,也不容易引起消息积压;即便引起消息积压,也可以通过扩充服务实例的方式解决。
-
如果需要重新消费该消息,只需要在MetaQ管理平台上点击"消息验证"即可。
3.流程定义不合理
3.1.原有的采购流程
这是一个简易的采购流程,由库管系统发起采购,采购员开始采购,采购员完成采购,同时回流采集订单到库管系统。
 其中,完成采购动作的核心代码如下:
其中,完成采购动作的核心代码如下:
/** 完成采购动作函数(此处省去获取采购单/验证状态/锁定采购单等逻辑) */
public void finishPurchase(PurchaseOrder order) {
// 完成相关处理
......
// 回流采购单(调用HTTP接口)
backflowPurchaseOrder(order);
// 设置完成状态
purchaseOrderDAO.setStatus(order.getId(), PurchaseOrderStatus.FINISHED.getValue());
}
由于函数backflowPurchaseOrder(回流采购单)调用了HTTP接口,可能引起以下问题:
-
该函数可能耗费时间较长,导致完成采购接口成为慢接口;
-
该函数可能失败抛出异常,导致客户调用完成采购接口失败。
3.2.优化的采购流程
通过需求分析,把"采购员完成采购并回流采集订单"动作拆分为"采购员完成采购"和"回流采集订单"两个独立的动作,把"采购完成"拆分为"采购完成"和"回流完成"两个独立的状态,更方便采购流程的管理和实现。
明代著名的心学集大成者王阳明先生在《传习录》中有云:
道无精粗,人之所见有精粗。如这一间房,人初进来,只见一个大规模如此。处久,便柱壁之类,一一看得明白。再久,如柱上有些文藻,细细都看出来。然只是一间房。是的,知识理论哪有什么精粗之分,只是人的认识程度不同而已。笔者在初创公司摸爬滚打数年,接触了各式各样的Java服务端架构,见得多了自然也就认识深了,就能分辨出各种方案的优劣了。这里,笔者总结了一些初创公司存在的Java服务端问题,并尝试性地给出了一些不成熟的解决方案。
1.系统不是分布式随着互联网的发展,计算机系统早就从单机独立工作过渡到多机器协同工作。计算机以集群的方式存在,按照分布式理论构建出庞大复杂的应用服务,早已深入人心并得到广泛地应用。但是,仍然有不少创业公司的软件系统停留在"单机版"。
1.1.单机版系统抢单案例这里,用并发性比较高的抢单功能为例说明:// 抢取订单函数 public synchronized void grabOrder(Long orderId, Long userId) { // 获取订单信息 OrderDO order = orderDAO.get(orderId); if (Objects.isNull(order)) { throw new BizRuntimeException(String.format("订单(%s)不存在", orderId)); } // 检查订单状态 if (!Objects.equals(order.getStatus, OrderStatus.WAITING_TO_GRAB.getValue())) { throw new BizRuntimeException(String.format("订单(%s)已被抢", orderId)); } // 设置订单被抢 orderDAO.setGrabed(orderId, userId); }以上代码,在一台服务器上运行没有任何问题。进入函数grabOrder(抢取订单)时,利用synchronized关键字把整个函数锁定,要么进入函数前订单未被人抢取从而抢取订单成功,要么进入函数前订单已被抢取导致抢取订单失败,绝对不会出现进入函数前订单未被抢取而进入函数后订单又被抢取的情况。但是,如果上面的代码在两台服务器上同时运行,由于Java的synchronized关键字只在一个虚拟机内生效,所以就会导致两个人能够同时抢取一个订单,但会以最后一个写入数据库的数据为准。所以,大多数的单机版系统,是无法作为分布式系统运行的。
1.2.分布式系统抢单案例添加分布式锁,进行代码优化:// 抢取订单函数 public void grabOrder(Long orderId, Long userId) { Long lockId = orderDistributedLock.lock(orderId); try { grabOrderWithoutLock(orderId, userId); } finally { orderDistributedLock.unlock(orderId, lockId); } } // 不带锁的抢取订单函数 private void grabOrderWithoutLock(Long orderId, Long userId) { // 获取订单信息 OrderDO order = orderDAO.get(orderId); if (Objects.isNull(order)) { throw new BizRuntimeException(String.format("订单(%s)不存在", orderId)); } // 检查订单状态 if (!Objects.equals(order.getStatus, OrderStatus.WAITING_TO_GRAB.getValue())) { throw new BizRuntimeException(String.format("订单(%s)已被抢", orderId)); } // 设置订单被抢 orderDAO.setGrabed(orderId, userId); }优化后的代码,在调用函数grabOrderWithoutLock(不带锁的抢取订单)前后,利用分布式锁orderDistributedLock(订单分布式锁)进行加锁和释放锁,跟单机版的synchronized关键字加锁效果基本一样。
1.3.分布式系统的优缺点分布式系统(Distributed System)是支持分布式处理的软件系统,是由通信网络互联的多处理机体系结构上执行任务的系统,包括分布式操作系统、分布式程序设计语言及其编译系统、分布式文件系统分布式数据库系统等。分布式系统的优点:
1.4.分布式软件解决方案作为一个合格的分布式系统,需要根据实际需求采用相应的分布式软件解决方案。
1.4.1.分布式锁分布式锁是单机锁的一种扩展,主要是为了锁住分布式系统中的物理块或逻辑块,用以此保证不同服务之间的逻辑和数据的一致性。目前,主流的分布式锁实现方式有3种:
1.4.2.分布式消息分布式消息中间件是支持在分布式系统中发送和接受消息的软件基础设施。常见的分布式消息中间件有ActiveMQ、RabbitMQ、Kafka、MetaQ等。MetaQ(全称Metamorphosis)是一个高性能、高可用、可扩展的分布式消息中间件,思路起源于LinkedIn的Kafka,但并不是Kafka的一个拷贝。MetaQ具有消息存储顺序写、吞吐量大和支持本地和XA事务等特性,适用于大吞吐量、顺序消息、广播和日志数据传输等场景。
1.4.3.数据库分片分组针对大数据量的数据库,一般会采用"分片分组"策略:分片(shard):主要解决扩展性问题,属于水平拆分。引入分片,就引入了数据路由和分区键的概念。其中, 分表解决的是数据量过大的问题, 分库解决的是数据库性能瓶颈的问题。分组(group):主要解决可用性问题,通过 主从复制的方式实现,并提供 读写分离策略用以提高数据库性能。
1.4.4.分布式计算分布式计算( Distributed computing )是一种"把需要进行大量计算的工程数据分割成小块,由多台计算机分别计算;在上传运算结果后,将结果统一合并得出数据结论"的科学。当前的高性能服务器在处理海量数据时,其计算能力、内存容量等指标都远远无法达到要求。在大数据时代,工程师采用廉价的服务器组成分布式服务集群,以集群协作的方式完成海量数据的处理,从而解决单台服务器在计算与存储上的瓶颈。Hadoop、Storm以及Spark是常用的分布式计算中间件,Hadoop是对非实时数据做批量处理的中间件,Storm和Spark是对实时数据做流式处理的中间件。除此之外,还有更多的分布式软件解决方案,这里就不再一一介绍了。
1.5.分布式硬件部署方案介绍完服务端的分布式软件解决方案,就不得不介绍一下服务端的分布式硬件部署方案。这里,只画出了服务端常见的接口服务器、MySQL数据库、Redis缓存,而忽略了其它的云存储服务、消息队列服务、日志系统服务……
1.5.1.一般单机版部署方案架构说明:只有1台接口服务器、1个MySQL数据库、1个可选Redis缓存,可能都部署在同一台服务器上。适用范围:适用于演示环境、测试环境以及不怕宕机且日PV在5万以内的小型商业应用。
1.5.2.中小型分布式硬件部署方案架构说明:通过SLB/Nginx组成一个负载均衡的接口服务器集群,MySQL数据库和Redis缓存采用了一主一备(或多备)的部署方式。适用范围:适用于日PV在500万以内的中小型商业应用。
1.5.3.大型分布式硬件部署方案架构说明:通过SLB/Nginx组成一个负载均衡的接口服务器集群,利用分片分组策略组成一个MySQL数据库集群和Redis缓存集群。适用范围:适用于日PV在500万以上的大型商业应用。
2.多线程使用不正确多线程最主要目的就是"最大限度地利用CPU资源",可以把串行过程变成并行过程,从而提高了程序的执行效率。
2.1.一个慢接口案例假设在用户登录时,如果是新用户,需要创建用户信息,并发放新用户优惠券。例子代码如下:// 登录函数(示意写法) public UserVO login(String phoneNumber, String verifyCode) { // 检查验证码 if (!checkVerifyCode(phoneNumber, verifyCode)) { throw new ExampleException("验证码错误"); } // 检查用户存在 UserDO user = userDAO.getByPhoneNumber(phoneNumber); if (Objects.nonNull(user)) { return transUser(user); } // 创建新用户 return createNewUser(user); } // 创建新用户函数 private UserVO createNewUser(String phoneNumber) { // 创建新用户 UserDO user = new UserDO(); ... userDAO.insert(user); // 绑定优惠券 couponService.bindCoupon(user.getId(), CouponType.NEW_USER); // 返回新用户 return transUser(user); }其中,绑定优惠券(bindCoupon)是给用户绑定新用户优惠券,然后再给用户发送推送通知。如果随着优惠券数量越来越多,该函数也会变得越来越慢,执行时间甚至超过1秒,并且没有什么优化空间。现在,登录(login)函数就成了名副其实的慢接口,需要进行接口优化。
2.2.采用多线程优化通过分析发现,绑定优惠券(bindCoupon)函数可以异步执行。首先想到的是采用多线程解决该问题,代码如下:// 创建新用户函数 private UserVO createNewUser(String phoneNumber) { // 创建新用户 UserDO user = new UserDO(); ... userDAO.insert(user); // 绑定优惠券 executorService.execute(()->couponService.bindCoupon(user.getId(), CouponType.NEW_USER)); // 返回新用户 return transUser(user); }现在,在新线程中执行绑定优惠券(bindCoupon)函数,使用户登录(login)函数性能得到很大的提升。但是,如果在新线程执行绑定优惠券函数过程中,系统发生重启或崩溃导致线程执行失败,用户将永远获取不到新用户优惠券。除非提供用户手动领取优惠券页面,否则就需要程序员后台手工绑定优惠券。所以,用采用多线程优化慢接口,并不是一个完善的解决方案。
2.3.采用消息队列优化如果要保证绑定优惠券函数执行失败后能够重启执行,可以采用数据库表、Redis队列、消息队列的等多种解决方案。由于篇幅优先,这里只介绍采用MetaQ消息队列解决方案,并省略了MetaQ相关配置仅给出了核心代码。消息生产者代码:// 创建新用户函数 private UserVO createNewUser(String phoneNumber) { // 创建新用户 UserDO user = new UserDO(); ... userDAO.insert(user); // 发送优惠券消息 Long userId = user.getId(); CouponMessageDataVO data = new CouponMessageDataVO(); data.setUserId(userId); data.setCouponType(CouponType.NEW_USER); Message message = new Message(TOPIC, TAG, userId, JSON.toJSONBytes(data)); SendResult result = metaqTemplate.sendMessage(message); if (!Objects.equals(result, SendStatus.SEND_OK)) { log.error("发送用户({})绑定优惠券消息失败:{}", userId, JSON.toJSONString(result)); } // 返回新用户 return transUser(user); }注意:可能出现发生消息不成功,但是这种概率相对较低。消息消费者代码:// 优惠券服务类 @Slf4j @Service public class CouponService extends DefaultMessageListener<String> { // 消息处理函数 @Override @Transactional(rollbackFor = Exception.class) public void onReceiveMessages(MetaqMessage<String> message) { // 获取消息体 String body = message.getBody(); if (StringUtils.isBlank(body)) { log.warn("获取消息({})体为空", message.getId()); return; } // 解析消息数据 CouponMessageDataVO data = JSON.parseObject(body, CouponMessageDataVO.class); if (Objects.isNull(data)) { log.warn("解析消息({})体为空", message.getId()); return; } // 绑定优惠券 bindCoupon(data.getUserId(), data.getCouponType()); } }解决方案优点:采集MetaQ消息队列优化慢接口解决方案的优点:
3.流程定义不合理
3.1.原有的采购流程这是一个简易的采购流程,由库管系统发起采购,采购员开始采购,采购员完成采购,同时回流采集订单到库管系统。其中,完成采购动作的核心代码如下:/** 完成采购动作函数(此处省去获取采购单/验证状态/锁定采购单等逻辑) */ public void finishPurchase(PurchaseOrder order) { // 完成相关处理 ...... // 回流采购单(调用HTTP接口) backflowPurchaseOrder(order); // 设置完成状态 purchaseOrderDAO.setStatus(order.getId(), PurchaseOrderStatus.FINISHED.getValue()); }由于函数backflowPurchaseOrder(回流采购单)调用了HTTP接口,可能引起以下问题:
3.2.优化的采购流程通过需求分析,把"采购员完成采购并回流采集订单"动作拆分为"采购员完成采购"和"回流采集订单"两个独立的动作,把"采购完成"拆分为"采购完成"和"回流完成"两个独立的状态,更方便采购流程的管理和实现。