问题背景:
客户反馈数据库反映缓慢,各模块均不能使用
1> 查看awr报告
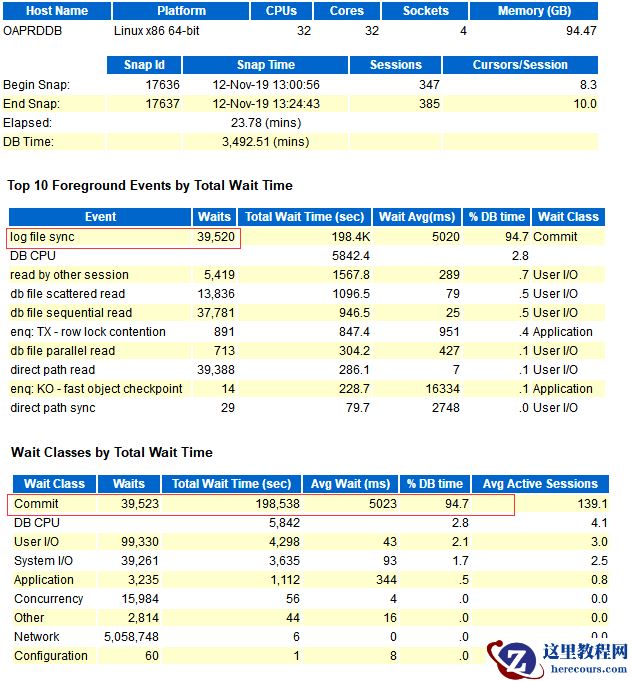
 问题分析:
1、log file sync的原凶到底是什么?
频繁commit/rollback或磁盘I/O有问题,大量物理读写争用
当一个用户提交(commits)或者回滚(rollback),session的redo信息需要写出到redo logfile中.
用户进程将通知LGWR执行写出操作,LGWR完成任务以后会通知用户进程.
这个等待事件就是指用户进程等待LGWR的写完成通知.
对于回滚操作,该事件记录从用户发出rollback命令到回滚完成的时间.
如果该等待过多,可能说明LGWR的写出效率低下,或者系统提交过于频繁.
针对该问题,可以关注:
log file parallel write等待事件
user commits,user rollback等统计信息可以用于观察提交或回滚次数
解决方案:
1.提高LGWR性能
尽量使用快速磁盘,不要把redo log file存放在raid 5的磁盘上
2.使用批量提交
3.适当使用NOLOGGING/UNRECOVERABLE等选项
4.检查redo log file足够大,确保redo log file每15到20分钟切换一次。
可以通过如下公式计算平均redo写大小:
avg.redo write size = (Redo block written/redo writes)*512 bytes
如果系统产生redo很多,而每次写的较少,一般说明LGWR被过于频繁的激活了.
可能导致过多的redo相关latch的竞争,而且Oracle可能无法有效的使用piggyback的功能.
我们从一个statspack中提取一些数据来研究一下这个问题.
我们看到,这里log file sync和db file parallel write等待同时出现了.
显然log file sync在等待db file parallel write的完成.
这里磁盘IO肯定存在了瓶颈,实际用户的redo和数据文件同时存放在Raid的磁盘上,存在性能问题.
需要调整.
由于过渡频繁的提交,LGWR过度频繁的激活,我们看到这里出现了redo writing的latch竞争.
关于redo writing竞争你可以在steve的站点找到详细的介绍:
http://www.ixora.com.au/notes/lgwr_latching.htm
在以前版本中,LGWR 执行写入操作完成后,会通知前台进程,这也就是 Post/Wait 模式;在11gR2 中,为了优化这个过程,前台进程通知LGWR写之后,可以通过定时获取的方式来查询写出进度,这被称为 Poll 的模式,在11.2.0.3中,这个特性被默认开启。这个参数的含义是:数据库可以在自适应的在 post/wait 和 polling 模式间选择和切换。
涉及的隐含参数
_use_adaptive_log_file_sync 参数的解释就是: Adaptively switch between post/wait and polling ,正是由于这个原因,带来了很多Bug,反而使得 Log File Sync 的等待异常的高,如果你在 11.2.0.3 版本中观察到这样的表征,那就极有可能与此有关。
在遇到问题是,通常将 _use_adaptive_log_file_sync 参数设置为 False,回归以前的模式,将会有助于问题的解决。
关闭:
SQL> alter system set parallel_adaptive_multi_user=false scope=both;
System altered.
SQL> show parameter adaptive;
此客户问题最终解决:
尝试增加一个redolog,512m,加了几分钟没有成功,可以判断磁盘I/O出问题,客户自行调整磁盘问题
问题分析:
1、log file sync的原凶到底是什么?
频繁commit/rollback或磁盘I/O有问题,大量物理读写争用
当一个用户提交(commits)或者回滚(rollback),session的redo信息需要写出到redo logfile中.
用户进程将通知LGWR执行写出操作,LGWR完成任务以后会通知用户进程.
这个等待事件就是指用户进程等待LGWR的写完成通知.
对于回滚操作,该事件记录从用户发出rollback命令到回滚完成的时间.
如果该等待过多,可能说明LGWR的写出效率低下,或者系统提交过于频繁.
针对该问题,可以关注:
log file parallel write等待事件
user commits,user rollback等统计信息可以用于观察提交或回滚次数
解决方案:
1.提高LGWR性能
尽量使用快速磁盘,不要把redo log file存放在raid 5的磁盘上
2.使用批量提交
3.适当使用NOLOGGING/UNRECOVERABLE等选项
4.检查redo log file足够大,确保redo log file每15到20分钟切换一次。
可以通过如下公式计算平均redo写大小:
avg.redo write size = (Redo block written/redo writes)*512 bytes
如果系统产生redo很多,而每次写的较少,一般说明LGWR被过于频繁的激活了.
可能导致过多的redo相关latch的竞争,而且Oracle可能无法有效的使用piggyback的功能.
我们从一个statspack中提取一些数据来研究一下这个问题.
我们看到,这里log file sync和db file parallel write等待同时出现了.
显然log file sync在等待db file parallel write的完成.
这里磁盘IO肯定存在了瓶颈,实际用户的redo和数据文件同时存放在Raid的磁盘上,存在性能问题.
需要调整.
由于过渡频繁的提交,LGWR过度频繁的激活,我们看到这里出现了redo writing的latch竞争.
关于redo writing竞争你可以在steve的站点找到详细的介绍:
http://www.ixora.com.au/notes/lgwr_latching.htm
在以前版本中,LGWR 执行写入操作完成后,会通知前台进程,这也就是 Post/Wait 模式;在11gR2 中,为了优化这个过程,前台进程通知LGWR写之后,可以通过定时获取的方式来查询写出进度,这被称为 Poll 的模式,在11.2.0.3中,这个特性被默认开启。这个参数的含义是:数据库可以在自适应的在 post/wait 和 polling 模式间选择和切换。
涉及的隐含参数
_use_adaptive_log_file_sync 参数的解释就是: Adaptively switch between post/wait and polling ,正是由于这个原因,带来了很多Bug,反而使得 Log File Sync 的等待异常的高,如果你在 11.2.0.3 版本中观察到这样的表征,那就极有可能与此有关。
在遇到问题是,通常将 _use_adaptive_log_file_sync 参数设置为 False,回归以前的模式,将会有助于问题的解决。
关闭:
SQL> alter system set parallel_adaptive_multi_user=false scope=both;
System altered.
SQL> show parameter adaptive;
此客户问题最终解决:
尝试增加一个redolog,512m,加了几分钟没有成功,可以判断磁盘I/O出问题,客户自行调整磁盘问题
log file sync等待事件
来源:这里教程网
时间:2026-03-03 14:32:25
作者:
编辑推荐:
- log file sync等待事件03-03
- oracle事务隔离级别transaction isolation level初识03-03
- oraInventory 文件相关命令03-03
- Oracle 客户端配置03-03
- Oracle:Linux 环境静默安装 GRID03-03
- PL/SQL 运算符03-03
- PL/SQL 条件03-03
- Oracle 官方给出声明——对于dblink产生影响03-03
下一篇:
相关推荐
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-

雷神推出 MIX PRO II 迷你主机:基于 Ultra 200H,玻璃上盖 + ARGB 灯效
2 月 9 日消息,雷神 (THUNDEROBOT) 现已宣布推出基于英
-

制造商 Musnap 推出彩色墨水屏电纸书 Ocean C:支持手写笔、第三方安卓应用
2 月 10 日消息,制造商 Musnap 现已在海外推出一款 Oce


热文推荐
- 今日头条在消息服务平台和容灾体系建设方面的实践与思考

今日头条在消息服务平台和容灾体系建设方面的实践与思考
26-03-03 - log file sync等待事件

log file sync等待事件
26-03-03 - oracle事务隔离级别transaction isolation level初识
- oraInventory 文件相关命令
oraInventory 文件相关命令
26-03-03 - Oracle 客户端配置
Oracle 客户端配置
26-03-03 - Oracle:Linux 环境静默安装 GRID
Oracle:Linux 环境静默安装 GRID
26-03-03 - Oracle 官方给出声明——对于dblink产生影响
Oracle 官方给出声明——对于dblink产生影响
26-03-03 - oracle产生事务transaction几种方式或方法

oracle产生事务transaction几种方式或方法
26-03-03 - 手机信号栏出现HD原因被确认,是不是套路呢?网友:我很迷茫啊

手机信号栏出现HD原因被确认,是不是套路呢?网友:我很迷茫啊
26-03-03 - 一条SQL在 MaxCompute 分布式系统中的旅程

一条SQL在 MaxCompute 分布式系统中的旅程
26-03-03


