前言: 本文介绍了饿了么交付中心由python语言栈转换到java语言栈大致过程,一来是对前段时间的工作做下总结,另外也是想通过此次总结为其他应用服务转型提供些借鉴。写的不好,欢迎板砖。
背景饿了么并入阿里集团,为了能高效与集团内部系统协同对接,同时方便利用集团优势技术资源,更好的融入阿里集团技术生态圈,饿了么交易中台在上半年启动了交易领域的四大应用语言栈转型项目,为阿里集团本地生活服务平台打好技术平台基础做准备。另外,随着业务量的激增,饿了么平台支持的品类不仅仅是最初的外卖单品,整个交易中台也需要一次相对大的重构来快速应对复杂多变的业务需求。而本文中的交付中心即是饿了么交易领域四大应用之一。
准备在开展相关工作之前,首先必须得清楚我们是要将一个系统从什么样变成什么样,新的系统相较老的系统在哪些方面做的更好,同时必须保证新老系统的无缝切换,做到业务无感不影响交易系统的稳定性。
系统价值外卖订单的业务特点是重交易,c端用户从下单选餐到骑手完成餐品交付过程,目前大部分都能在半小时左右完成,对即时配送实时性要求较高。整个订单交易过程大致划分为:1.添加购物车确认订单,2.订单生成及订单支付,3.接单及订单交付,4.可能的售后退单。而要更好的服务用户,对四个系统稳定的协同能力提出很高的要求。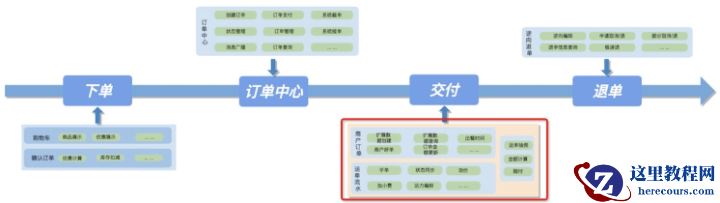 如前文所述,我们知道履约环节对交易订单的价值是什么,即是将外卖订单对应的餐品交付到用户手中,技术层面上来讲,交付对交易订单屏蔽了一切其他履约细节,使订单更专注订单领域业务。
如前文所述,我们知道履约环节对交易订单的价值是什么,即是将外卖订单对应的餐品交付到用户手中,技术层面上来讲,交付对交易订单屏蔽了一切其他履约细节,使订单更专注订单领域业务。
内核分析接下来,我们再进一步详细的剖析下转型前交付系统所承载的功能。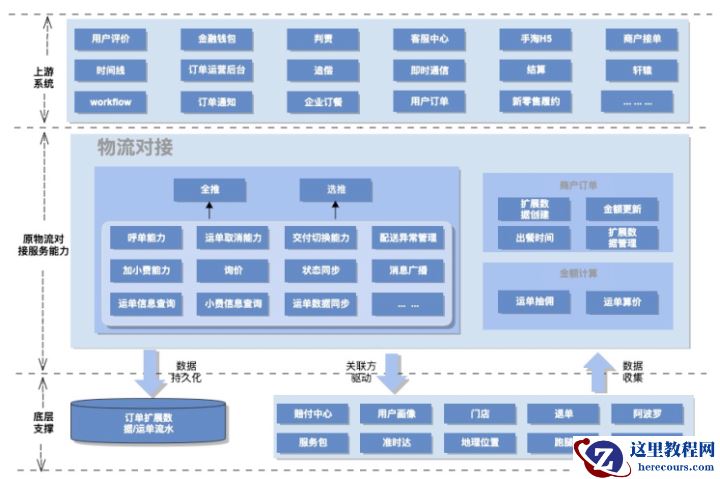 如上图所示,原交付履约领域中包含了三个较大板块:
如上图所示,原交付履约领域中包含了三个较大板块: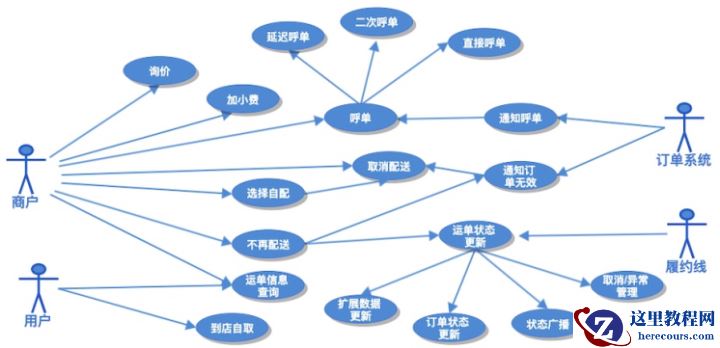 更详细的系统用例梳理或系统上下游交互时序这里不再一一列举,需要说明一点,当大流量系统转型遇到重构,要想走的够远够稳,前期的仔细调研工作及功能对齐过程非常重要。特别是生产环境已经跑了好几年核心功能系统,实际业务情况错综复杂。例如要转型重构系统接口能力,接口含义,场景必须都要详细掌握。
更详细的系统用例梳理或系统上下游交互时序这里不再一一列举,需要说明一点,当大流量系统转型遇到重构,要想走的够远够稳,前期的仔细调研工作及功能对齐过程非常重要。特别是生产环境已经跑了好几年核心功能系统,实际业务情况错综复杂。例如要转型重构系统接口能力,接口含义,场景必须都要详细掌握。
设计至此,我们的目标已经很明确:1.语言栈转型,2.过程中要将不属于交付的东西从原系统中分离出去,使得交付领域更干净。结合交付未来可能的发展方向,其中交付能力可复用的,履约运力线可扩展的。这对整个交付可快速迭代对接提出了更高要求。另外,我们也在领域建模设计思想指导下做了些实践尝试,于是有了以下框架结构。
系统设计转型是把python方言转换到java方言,交付系统核心能力不会有变化。能力的复用是通过接口维度的抽象聚合产生,履约运力线能力可扩展通过利用业务框架扩展点特性满足。拆分后的业务框架应如下图所示: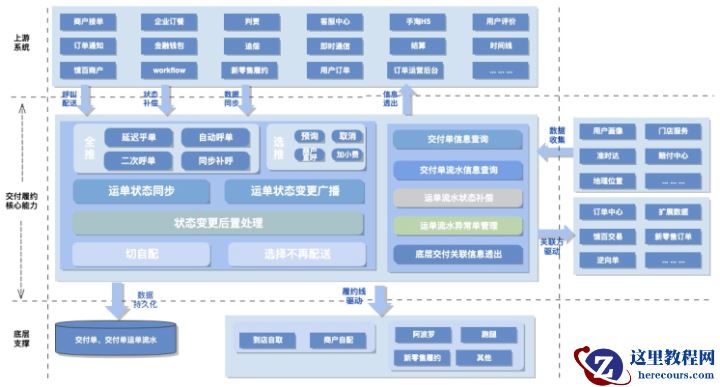
系统架构业务框架结合当前饿场基础组件支持我们不难给出以下系统内部模块划分: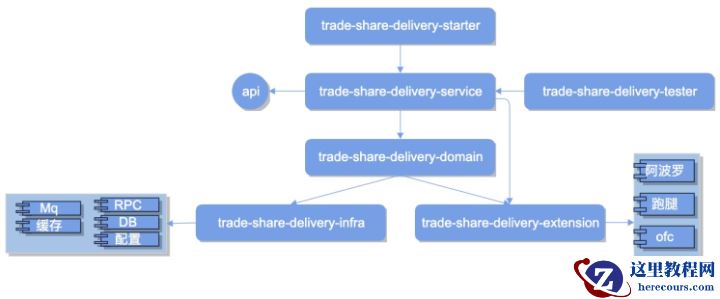 简单对各组成模块做简要说明:
简单对各组成模块做简要说明:
平稳过渡代码撸完测完才做好转型工作的第一步,将流量稳步平滑过渡到新的服务中,做到上下游无感是转型过程中面临的另一大挑战。 说到这里,要达到系统的语言转型前后的平稳过渡其实是在说转型前后对我们系统的用户SLA(Service Level Agreement)提供一致性的保证。这里先简单聊聊系统服务的SLA。服务可用性级别服务正常运行时间百分比年宕机时间日宕机时间190%36.5day2.4 hour299%3.65day14 min399.9%8.76day86sec499.99%52.6min8.6sec599.999%5.25min0.86sec699.9999%31.5sec8.6msec上表格是业界服务高可用的几个级别的衡量标准,例如:服务可用性是3个9时,全年宕机时长约为8.76天的统计概率。另外,我们需要明确的是不同的系统,不同的场景以及不同的用户规模对系统可用性要求是不一样的。如:某些业务的支付链路场景可能tps不是很高,但是作为交易的核型链路必须得保证高级别的可用性。 怎么保证或者提升系统服务的SLA呢?在明确我们目标后,接下来就是拆解目标量化目标。you cant measure it,you cant fix it and improve it.一般来说,影响系统服务可用性有两个重要因子: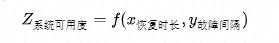 可能无法给到一个精确的数学描述,但是可以做定性的分析:恢复时长因子与系统可用度成正相关,故障间隔因子与系统可用度成逆相关。也即: _问题出现时恢复时长要尽可能的短,尽可能降低故障频率以增大故障间隔。基于以上理论,我们在做系统平稳过渡无缝切换时,无论资源使用,业务内部逻辑实现及灰度方案,我们都需要着眼于这两个方面。接下来我们将从这两个点出发分析转型过程存在的挑战及我们的应对方式。
可能无法给到一个精确的数学描述,但是可以做定性的分析:恢复时长因子与系统可用度成正相关,故障间隔因子与系统可用度成逆相关。也即: _问题出现时恢复时长要尽可能的短,尽可能降低故障频率以增大故障间隔。基于以上理论,我们在做系统平稳过渡无缝切换时,无论资源使用,业务内部逻辑实现及灰度方案,我们都需要着眼于这两个方面。接下来我们将从这两个点出发分析转型过程存在的挑战及我们的应对方式。
快速响应,降低恢复时长要做到恢复时长尽可能的短,首先我们需要保证在前期出现问题时流量切换过程中流量规模尽可能的小,即需要一个相对的合理的灰度梯度方案。其次当问题出现后我门需要能立即回切到原系统,不至于反应过慢导致大量增量问题产生,即需要一个响应高效的开关回滚方案。由于转型过程中涉及的接口和消息消费入口较多,另外我们还需要考虑到后期问题排障和快速定位的可能耗时。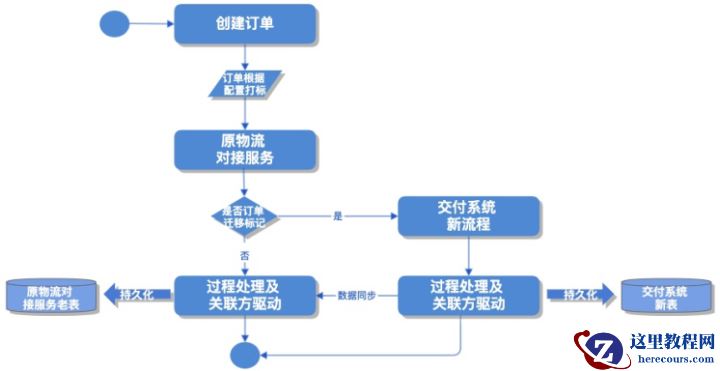 如上图所示,订单系统创建订单时根据既定的灰度计划读取配置给订单打标,灰度计划分为前期分标品,门店维度验证,后期按城市订单分布维度配置。若新系统服务出现问题可一键切掉灰度流量,止血增量问题。接着,原交付老服务识别标记做代理转发,订单不存在迁移标记则原流程操作处理,否则转发到新交付中心新服务操作处理,相应的消息监听处理同样也是参照订单标记,这样保证了同一个订单的交付过程能在一个应用中完成,有利于后期处理流量上来后的快速问题定位。 另外,我们的接口灰度过程是写与查分离的,整个迁移过程大致分为三个阶段,如下图所示:
如上图所示,订单系统创建订单时根据既定的灰度计划读取配置给订单打标,灰度计划分为前期分标品,门店维度验证,后期按城市订单分布维度配置。若新系统服务出现问题可一键切掉灰度流量,止血增量问题。接着,原交付老服务识别标记做代理转发,订单不存在迁移标记则原流程操作处理,否则转发到新交付中心新服务操作处理,相应的消息监听处理同样也是参照订单标记,这样保证了同一个订单的交付过程能在一个应用中完成,有利于后期处理流量上来后的快速问题定位。 另外,我们的接口灰度过程是写与查分离的,整个迁移过程大致分为三个阶段,如下图所示: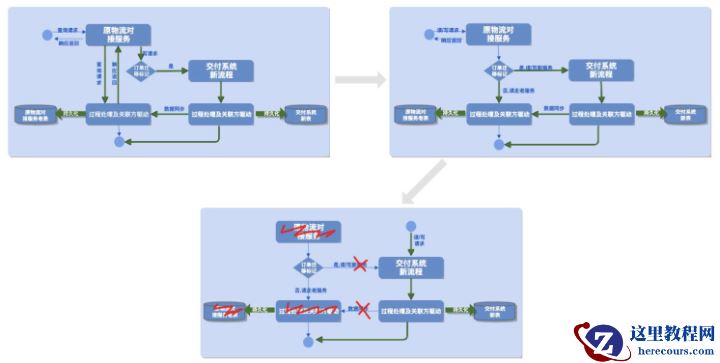
最大努力降低故障风险平均故障间隔是一个后验时长数据,要做到间隔时长尽可能的长,日常里就需做好发布控制,风险巡检及持续监控等工作。
1.发布控制转型期间新系统服务必须遵循发布sop,饿场发布sop已经形成共识,我们只需严格遵守,这里不再赘述。
2.风险巡检
3.多层次持续监控
一致性问题转型过程中我们实际上同时做了数据模型优化迁移,对外为了保证新老系统行为属性的一致性,我们还面临以下几个挑战: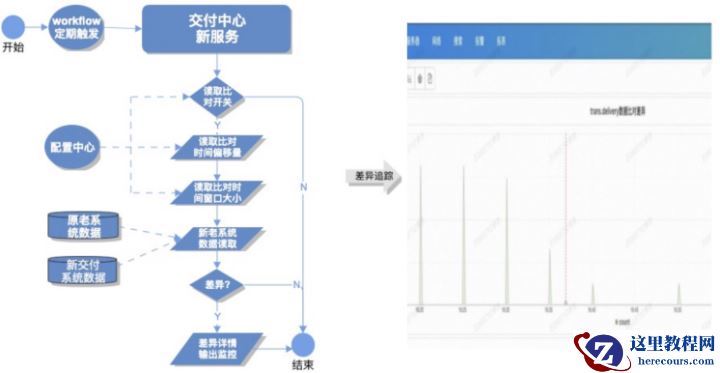
饿了么交付中心语言栈转型总结
来源:这里教程网
时间:2026-03-03 14:35:09
作者: