current:当前正在使用的日志组状态active: 刚刚用完还没有重新完成初始化以备下次使用的日志组状态inactive:已经完成初始化可供再次使用的日志组状态members:表示每个日志组中有几个日志文件
查看日志信息
SQL> select group#,sequence#,status,members,bytes/1024/1024 from v$log;
GROUP# SEQUENCE# STATUS
MEMBERS BYTES/1024/1024
---------- ---
---
---------- ---------------- ---------- ---------------
1
19 CURRENT
1
50
2
17 INACTIVE 1
50
3
18 INACTIVE
1
50
2.查看当前数据库中redo日志的存放位置
SQL> select member from v$logfile;
MEMBER
------------------------------------------------------------
/u01/app/oracle/oradata/orcl/redo03.log
/u01/app/oracle/oradata/orcl/redo02.log
/u01/app/oracle/oradata/orcl/redo01.log
在oracle数据库中,一旦数据发生修改操作,就会产生redo。如果redo组数太少,或者redo文件太小,导致redo日志组切换太频繁,就可能会影响数据库的正常运行。因此,我们需要确定当前redo日志设置是否合理。
redo日志组设置是否合理的一个重要指标就是redo日志组的切换时间间隔。推荐时间间隔为10-15分钟。查看日志组切换时间间隔,视图v$log-history
SQL> select to_char(first_time,'yyyy-mm-dd hh24:mi:ss')from v$log_history;
TO_CHAR(FIRST_TIME,
-------------------
2019-11-18 05:32:41
2019-11-18 05:32:47
2019-11-18 05:33:00
2019-11-18 05:33:10
2019-11-19 05:00:04
2019-11-19 22:00:15
2019-11-19 22:05:33
2019-11-20 22:00:19
2019-11-21 22:00:12
2019-12-05 04:24:57
2019-12-05 04:59:34
2019-12-05 08:00:38
2020-01-09 06:27:10
2020-01-09 20:00:37
2020-01-14 03:36:35
2020-01-14 22:00:10
2020-01-15 14:00:36
2020-01-16 04:01:00
18 rows selected.
因为我用的测试环境,因此数据库是相当空闲的。我们尝试进行几次redo日志组的手工切换:
SQL> alter system switch logfile;
System altered.
SQL> /
System altered.
SQL> /
System altered.
然后再查看v$log_history
SQL> select to_char(first_time,'yyyy-mm-dd hh24:mi:ss')from v$log_history;
TO_CHAR(FIRST_TIME,
-------------------
2019-11-18 05:32:41
2019-11-18 05:32:47
2019-11-18 05:33:00
2019-11-18 05:33:10
2019-11-19 05:00:04
2019-11-19 22:00:15
2019-11-19 22:05:33
2019-11-20 22:00:19
2019-11-21 22:00:12
2019-12-05 04:24:57
2019-12-05 04:59:34
2019-12-05 08:00:38
2020-01-09 06:27:10
2020-01-09 20:00:37
2020-01-14 03:36:35
2020-01-14 22:00:10
2020-01-15 14:00:36
2020-01-16 04:01:00
2020-01-16 22:00:29
2020-01-17 02:23:39
2020-01-17 02:23:40
因为是手工切换的,这里redo日志组的切换时间间隔很短。如果日志组切换时间间隔太短,会在数据库的告警日志中记录。
cd /u01/app/oracle/diag/rdbms/orcl/orcl/trace[oracle@ymm trace]$ tail -f alert_orcl.log
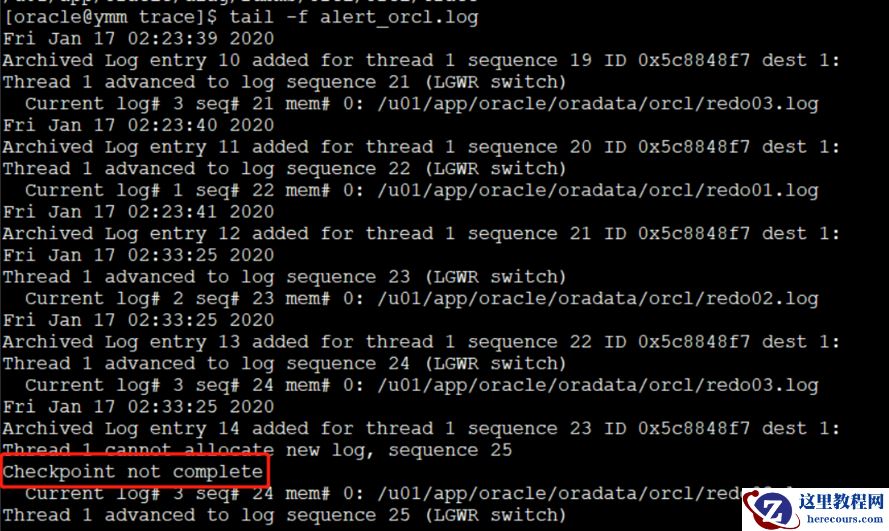 日志切换太快,会在警告日志中记录Checkpoint(检查点) not complete信息,oracle每次切换日志时,都会执行一次检查点操作来完成redo当中记录的数据修改信息和数据文件中的信息的同步。切换太快,会导致这个同步操作无法及时完成。出现这问题,往往意味着redo日志组的设置不合理。
接下调整日志组要求:添加3个日志组,每个日志组两个日志文件,每个日志文件的大小为500M;
日志切换太快,会在警告日志中记录Checkpoint(检查点) not complete信息,oracle每次切换日志时,都会执行一次检查点操作来完成redo当中记录的数据修改信息和数据文件中的信息的同步。切换太快,会导致这个同步操作无法及时完成。出现这问题,往往意味着redo日志组的设置不合理。
接下调整日志组要求:添加3个日志组,每个日志组两个日志文件,每个日志文件的大小为500M;
添加新的redo日志组
SQL> alter database add logfile group 4 ('/u01/app/oracle/oradata/orcl/redo04.log','/u01/app/oracle/oradata/orcl/redo05.log') size 500m;
Database altered.
SQL> alter database add logfile group 5 ('/u01/app/oracle/oradata/orcl/redo05_1.log','/u01/app/oracle/oradata/orcl/redo05_2.log')size 500m;
Database altered.
SQL> alter database add logfile group 6('/u01/app/oracle/oradata/orcl/redo06_1.log','/u01/app/oracle/oradata/orcl/redo06_2.log')size 500m;
Database altered. 2.查看当前redo日志组设置
SQL> select group#,sequence#,status,members,bytes/1024/1024 from v$log;
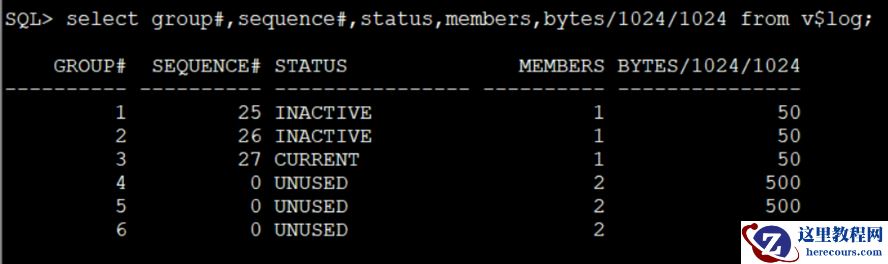 新添加的3组状态均为unused
3.删除旧的redo日志组
current状态的不能删除,可以删除inactive状态
SQL> alter database drop logfile group 1;
Database altered.
SQL> alter database drop logfile group 2;
Database altered.
SQL> alter database drop logfile group 3;
Database altered.
SQL> select group#,sequence#,status,members,bytes/1024/1024 from v$log;
新添加的3组状态均为unused
3.删除旧的redo日志组
current状态的不能删除,可以删除inactive状态
SQL> alter database drop logfile group 1;
Database altered.
SQL> alter database drop logfile group 2;
Database altered.
SQL> alter database drop logfile group 3;
Database altered.
SQL> select group#,sequence#,status,members,bytes/1024/1024 from v$log;
 需要注意,我们只是在数据库中删除了3组日志,在操作系统上对应的日志文件并没有删除,我们需要手工删除操作系统上对应的日志文件[oracle@ymm trace]$ cd /u01/app/oracle/oradata/orcl/
[oracle@ymm orcl]$ lscontrol01.ctl redo01.log redo03.log redo05_1.log redo05.log redo06_2.log system01.dbf undotbs01.dbfcontrol02.ctl redo02.log redo04.log redo05_2.log redo06_1.log sysaux01.dbf temp01.dbf users01.dbf
[oracle@ymm orcl]$ ls -lrt|grep redo-rw-r----- 1 oracle oinstall 52429312 Jan 17 02:33 redo01.log-rw-r----- 1 oracle oinstall 52429312 Jan 17 02:33 redo02.log-rw-r----- 1 oracle oinstall 52429312 Jan 17 02:59 redo03.log-rw-r----- 1 oracle oinstall 524288512 Jan 17 02:59 redo05.log-rw-r----- 1 oracle oinstall 524288512 Jan 17 02:59 redo04.log-rw-r----- 1 oracle oinstall 524288512 Jan 17 03:01 redo05_2.log-rw-r----- 1 oracle oinstall 524288512 Jan 17 03:01 redo05_1.log-rw-r----- 1 oracle oinstall 524288512 Jan 17 03:06 redo06_1.log-rw-r----- 1 oracle oinstall 524288512 Jan 17 03:06 redo06_2.log
删除日志文件
[oracle@ymm orcl]$ rm redo0[1-3]*
4.对redo日志文件重命名
需要注意,修改日志文件名,需要数据库在mount状态下进行修改。
1)关闭数据库并启动到mount状态
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount;
ORACLE instance started.
Total System Global Area 730714112 bytes
Fixed Size
2231952 bytes
Variable Size
239075696 bytes
Database Buffers
482344960 bytes
Redo Buffers
7061504 bytes
Database mounted.
2)修改redo日志文件名
SQL> alter database rename file '/u01/app/oracle/oradata/orcl/redo04.log' to '/u01/app/oracle/oradata/orcl/redo04_1.log';
需要注意,我们只是在数据库中删除了3组日志,在操作系统上对应的日志文件并没有删除,我们需要手工删除操作系统上对应的日志文件[oracle@ymm trace]$ cd /u01/app/oracle/oradata/orcl/
[oracle@ymm orcl]$ lscontrol01.ctl redo01.log redo03.log redo05_1.log redo05.log redo06_2.log system01.dbf undotbs01.dbfcontrol02.ctl redo02.log redo04.log redo05_2.log redo06_1.log sysaux01.dbf temp01.dbf users01.dbf
[oracle@ymm orcl]$ ls -lrt|grep redo-rw-r----- 1 oracle oinstall 52429312 Jan 17 02:33 redo01.log-rw-r----- 1 oracle oinstall 52429312 Jan 17 02:33 redo02.log-rw-r----- 1 oracle oinstall 52429312 Jan 17 02:59 redo03.log-rw-r----- 1 oracle oinstall 524288512 Jan 17 02:59 redo05.log-rw-r----- 1 oracle oinstall 524288512 Jan 17 02:59 redo04.log-rw-r----- 1 oracle oinstall 524288512 Jan 17 03:01 redo05_2.log-rw-r----- 1 oracle oinstall 524288512 Jan 17 03:01 redo05_1.log-rw-r----- 1 oracle oinstall 524288512 Jan 17 03:06 redo06_1.log-rw-r----- 1 oracle oinstall 524288512 Jan 17 03:06 redo06_2.log
删除日志文件
[oracle@ymm orcl]$ rm redo0[1-3]*
4.对redo日志文件重命名
需要注意,修改日志文件名,需要数据库在mount状态下进行修改。
1)关闭数据库并启动到mount状态
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount;
ORACLE instance started.
Total System Global Area 730714112 bytes
Fixed Size
2231952 bytes
Variable Size
239075696 bytes
Database Buffers
482344960 bytes
Redo Buffers
7061504 bytes
Database mounted.
2)修改redo日志文件名
SQL> alter database rename file '/u01/app/oracle/oradata/orcl/redo04.log' to '/u01/app/oracle/oradata/orcl/redo04_1.log';
 这里报错了,说redo04_1.log文件不存在,这里我们需要先在操作系统上将redo04.log改为redo04_1.log[oracle@ymm orcl]$ mv redo04.log redo04_1.log[oracle@ymm orcl]$ mv redo05.log redo04_2.log
SQL> alter database rename file '/u01/app/oracle/oradata/orcl/redo04.log' to '/u01/app/oracle/oradata/orcl/redo04_1.log';
Database altered.
SQL> alter database rename file '/u01/app/oracle/oradata/orcl/redo05.log' to '/u01/app/oracle/oradata/orcl/redo04_2.log';
Database altered.
3)启动数据库
SQL> alter database open;
Database altered.
SQL> select member from v$logfile;
MEMBER
------------------------------------------------------------
/u01/app/oracle/oradata/orcl/redo04_1.log
/u01/app/oracle/oradata/orcl/redo04_2.log
/u01/app/oracle/oradata/orcl/redo05_1.log
/u01/app/oracle/oradata/orcl/redo05_2.log
/u01/app/oracle/oradata/orcl/redo06_1.log
/u01/app/oracle/oradata/orcl/redo06_2.log
补充:
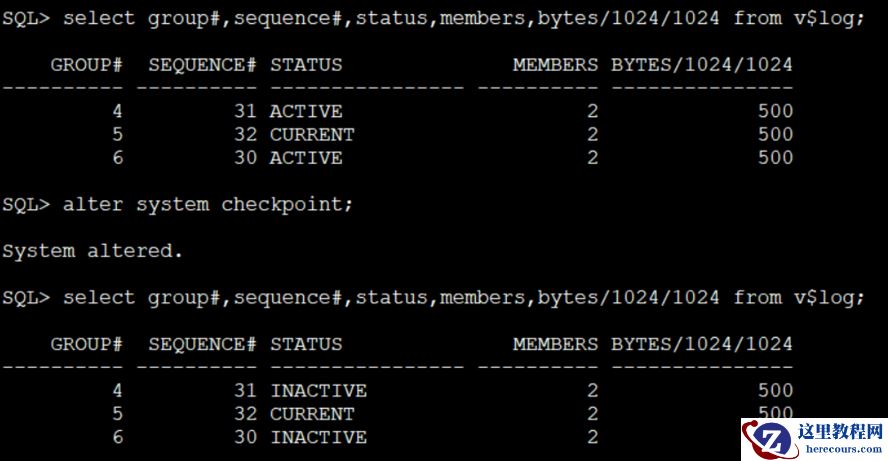
将active状态的日志转换为inactive的
SQL> alter system checkpoint;
System altered.
这里报错了,说redo04_1.log文件不存在,这里我们需要先在操作系统上将redo04.log改为redo04_1.log[oracle@ymm orcl]$ mv redo04.log redo04_1.log[oracle@ymm orcl]$ mv redo05.log redo04_2.log
SQL> alter database rename file '/u01/app/oracle/oradata/orcl/redo04.log' to '/u01/app/oracle/oradata/orcl/redo04_1.log';
Database altered.
SQL> alter database rename file '/u01/app/oracle/oradata/orcl/redo05.log' to '/u01/app/oracle/oradata/orcl/redo04_2.log';
Database altered.
3)启动数据库
SQL> alter database open;
Database altered.
SQL> select member from v$logfile;
MEMBER
------------------------------------------------------------
/u01/app/oracle/oradata/orcl/redo04_1.log
/u01/app/oracle/oradata/orcl/redo04_2.log
/u01/app/oracle/oradata/orcl/redo05_1.log
/u01/app/oracle/oradata/orcl/redo05_2.log
/u01/app/oracle/oradata/orcl/redo06_1.log
/u01/app/oracle/oradata/orcl/redo06_2.log
补充:
将active状态的日志转换为inactive的
SQL> alter system checkpoint;
System altered.










")
")