墨墨导读:XGBoost是一个高效、可扩展的机器学习算法,用于回归和分类(regression and classification),使得XGBoost Gradient Boosting开源包可用。

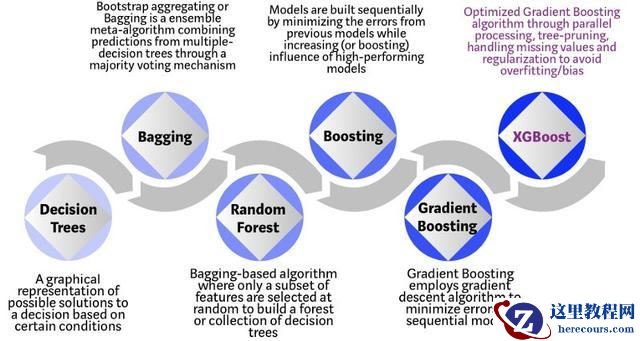
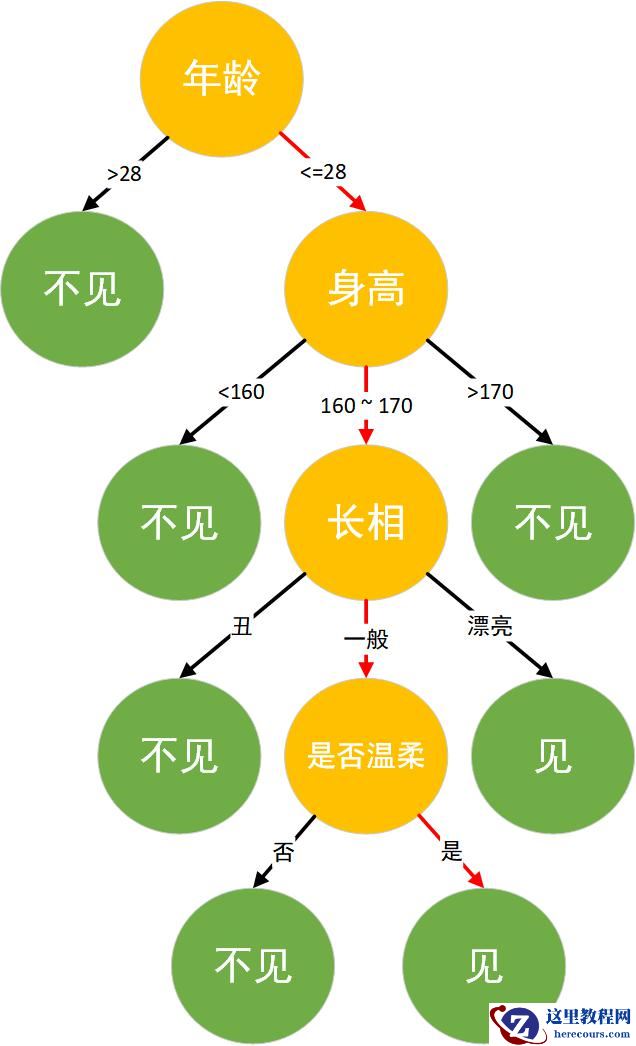
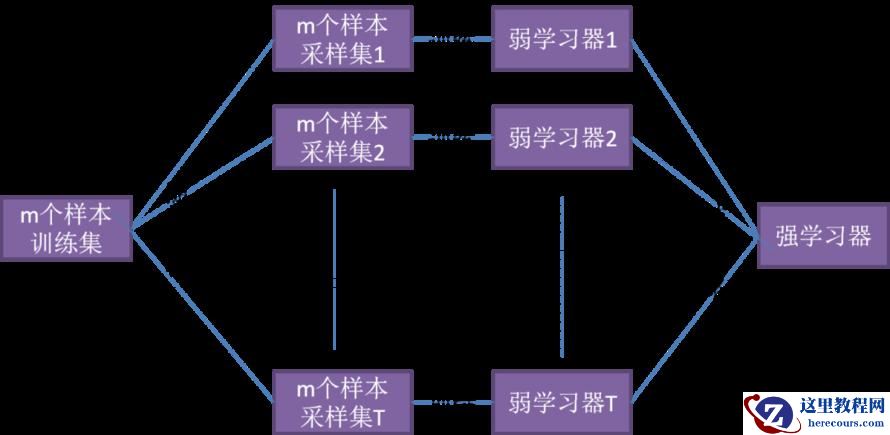
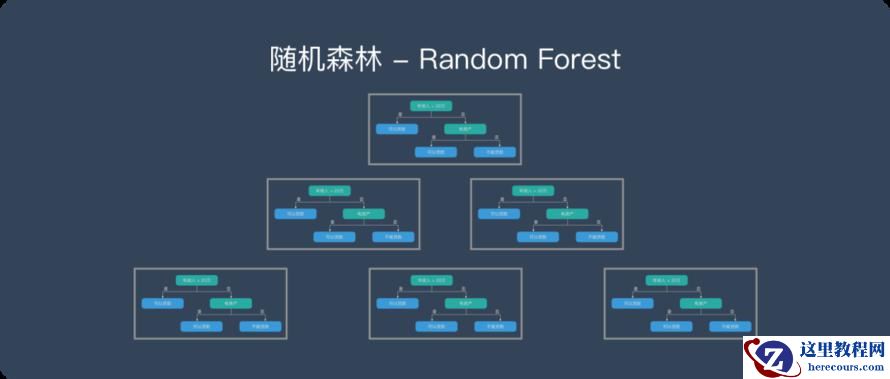
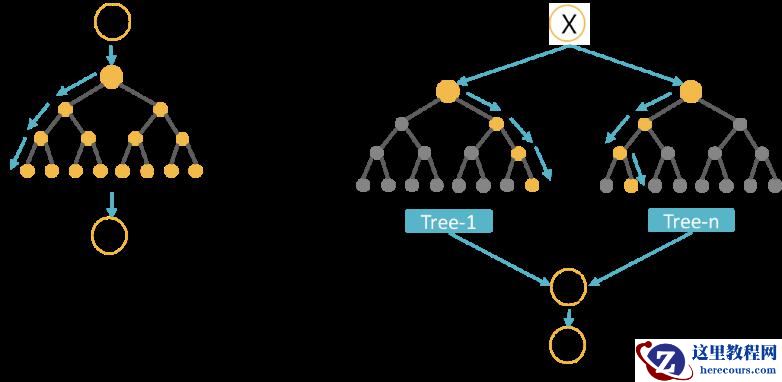
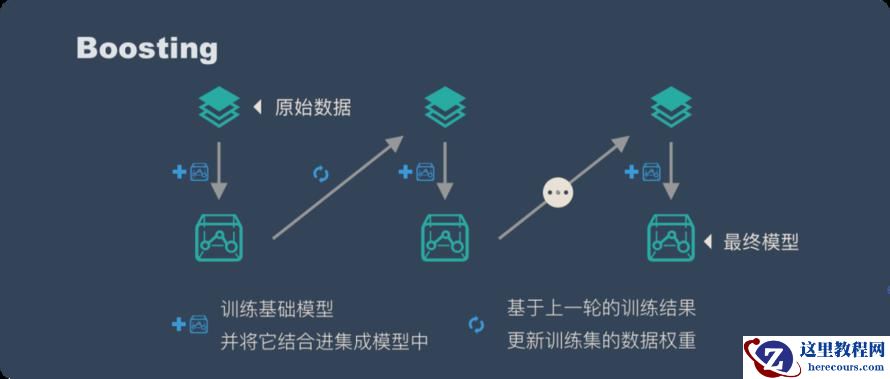
XGBoost 是基于决策树的集成机器学习算法,它以梯度提升(Gradient Boost)为框架。在非结构数据(图像、文本等)的预测问题中,人工神经网络的表现要优于其他算法或框架。但在处理中小型结构数据或表格数据时,现在普遍认为基于决策树的算法是最好的。下图列出了近年来基于树的算法的演变过程:

-- Create the setting table xgc_sh_settings.
CREATE TABLE xgc_sh_settings(setting_name VARCHAR2(30),
setting_value VARCHAR2(128));
-- Populate the settings table.
BEGIN
INSERT INTO xgc_sh_settings (setting_name, setting_value) VALUES
(dbms_data_mining.algo_name, dbms_data_mining.algo_xgboost);
-- For 0/1 target, choose binary:logistic as the objective.
INSERT INTO xgc_sh_settings (setting_name, setting_value) VALUES
(dbms_data_mining.xgboost_objective, 'binary:logistic');
INSERT INTO xgc_sh_settings (setting_name, setting_value) VALUES
(dbms_data_mining.xgboost_max_depth, '3');
INSERT INTO xgc_sh_settings (setting_name, setting_value) VALUES
(dbms_data_mining.xgboost_eta, '1');
-- Choose error and auc as eval_metric to evaluate the training dataset.
INSERT INTO xgc_sh_settings (setting_name, setting_value) VALUES
(dbms_data_mining.xgboost_eval_metric, 'error,auc');
INSERT INTO xgc_sh_settings (setting_name, setting_value) VALUES
(dbms_data_mining.xgboost_num_round, '10');
END;
/
-- Create a model. BEGIN DBMS_DATA_MINING.CREATE_MODEL( model_name => 'XGC_SH_MODEL', mining_function => dbms_data_mining.classification, data_table_name => 'mining_data_build_v', case_id_column_name => 'cust_id', target_column_name => 'affinity_card', settings_table_name => 'xgc_sh_settings'); END; / -- Display the model settings. SELECT setting_name, setting_value FROM user_mining_model_settings WHERE model_name = 'XGC_SH_MODEL' ORDER BY setting_name; -- The query produces the following output. SETTING_NAME SETTING_VALUE ------------------------------ ------------------------------ ALGO_NAME ALGO_XGBOOST CLAS_WEIGHTS_BALANCED OFF ODMS_DETAILS ODMS_ENABLE ODMS_MISSING_VALUE_TREATMENT ODMS_MISSING_VALUE_AUTO ODMS_SAMPLING ODMS_SAMPLING_DISABLE PREP_AUTO ON booster gbtree eta 1 eval_metric error,auc max_depth 3 ntree_limit 0 num_round 10 objective binary:logistic 13 rows selected.
-- Show the atribute importance of the top 10 important features. SELECT * FROM(SELECT attribute_name, attribute_value, gain, cover, frequency FROM DM$VIXGC_SH_MODEL ORDER BY gain desc) WHERE rownum <= 10; The query produces the following output. ATTRIBUTE_NAME ATTRIBUTE_VALUE GAIN COVER FREQUENCY ------------------------- --------------- ------ ------ --------- YRS_RESIDENCE .259 .143 .117 HOUSEHOLD_SIZE 2 .110 .044 .033 AGE .093 .156 .250 HOUSEHOLD_SIZE 9+ .085 .031 .033 CUST_MARITAL_STATUS NeverM .073 .067 .033 BOOKKEEPING_APPLICATION .055 .035 .033 EDUCATION Bach. .053 .047 .033 OCCUPATION Prof. .048 .032 .033 EDUCATION Masters .045 .052 .050 OCCUPATION Other .029 .055 .033 10 rows selected.
-- Create the setting table xgr_sh_settings. CREATE TABLE xgr_sh_settings(setting_name VARCHAR2(30), setting_value VARCHAR2(128)); -- Populate the settings table. BEGIN INSERT INTO xgr_sh_settings (setting_name, setting_value) VALUES (dbms_data_mining.algo_name, dbms_data_mining.algo_xgboost); -- For 0/1 target, choose binary:logistic as the objective. INSERT INTO xgr_sh_settings (setting_name, setting_value) VALUES (dbms_data_mining.xgboost_booster, 'gblinear'); INSERT INTO xgr_sh_settings (setting_name, setting_value) VALUES (dbms_data_mining.xgboost_alpha, '0.0001'); INSERT INTO xgr_sh_settings (setting_name, setting_value) VALUES (dbms_data_mining.xgboost_lambda, '1'); INSERT INTO xgr_sh_settings (setting_name, setting_value) VALUES (dbms_data_mining.xgboost_num_round, '100'); END; /
-- Create a model. BEGIN DBMS_DATA_MINING.CREATE_MODEL( model_name => 'XGR_SH_MODEL', mining_function => dbms_data_mining.regression, data_table_name => 'mining_data_build_v', case_id_column_name => 'cust_id', target_column_name => 'age', settings_table_name => 'xgr_sh_settings'); END; / -- Display the model settings. SELECT setting_name, setting_value FROM user_mining_model_settings WHERE model_name = 'XGR_SH_MODEL' ORDER BY setting_name; The query produces the following output. SETTING_NAME SETTING_VALUE ------------------------------ ------------------------------ ALGO_NAME ALGO_XGBOOST ODMS_DETAILS ODMS_ENABLE ODMS_MISSING_VALUE_TREATMENT ODMS_MISSING_VALUE_AUTO ODMS_SAMPLING ODMS_SAMPLING_DISABLE PREP_AUTO ON alpha 0.0001 booster gblinear lambda 1 ntree_limit 0 num_round 100 10 rows selected.
-- Show the atribute importance of the top 5 important features. SSELECT * FROM(SELECT attribute_name, attribute_value, weight FROM DM$VIXGR_SH_MODEL ORDER BY abs(weight) desc) WHERE rownum <= 5; The query produces the following output. ATTRIBUTE_NAME ATTRIBUTE_VALUE WEIGHT ---------------------- --------------- ------ YRS_RESIDENCE 3.109 HOME_THEATER_PACKAGE 2.332 Y_BOX_GAMES -1.804 CUST_MARITAL_STATUS NeverM -1.131 HOUSEHOLD_SIZE 1 -.696 5 rows selected.









