背景概述
5 月10号早上11点21分,有人反应应用慢打不开,登陆orcl1数据库,存在tx锁,有大量阻塞会话。5月10日下午,反应应用连不上主机。
问题的基本诊断和处理
查询锁源头,将锁杀掉。排查数据库服务器状态。
事件支持细节
关于锁的问题
获取2017-05-10 11
:00 - 12
:00
的历史ash
信息Create table m_asm as select * from dba_hist_active_sess_history where sample_time betweenTo_timestamp(‘2017-05-10 11:00:00’,’yyyy-mm-dd hh24:mi:ss’) and To_timestamp(‘2017-05-10 12:00:00’,’yyyy-mm-dd hh24:mi:ss’) ;select instance_number,event,count(*) from m_ash group by instance_number,event order by 3;
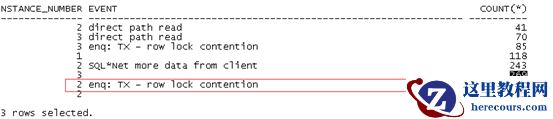 可以看出锁等待最严重的在2
节点上
可以看出锁等待最严重的在2
节点上
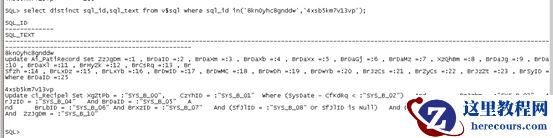 查询锁等待的会话被哪个会话堵塞
查询锁等待的会话被哪个会话堵塞
 可以看到1
节点的252
号会话堵塞了187
个会话,而且其锁定了两张表,导致前面两条sql
被后续的会话执行的时候全部等待
根据1
节点在故障时期记录的日志
可以看到1
节点的252
号会话堵塞了187
个会话,而且其锁定了两张表,导致前面两条sql
被后续的会话执行的时候全部等待
根据1
节点在故障时期记录的日志
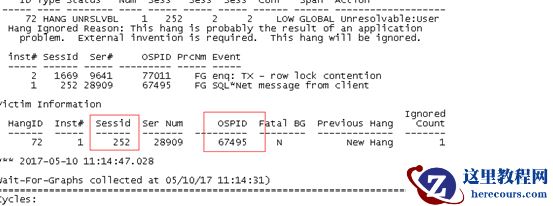
这个trace
说明了252
号会话的操作系统进程号是67595
,根据netstat
查询器对应的客户端ip
是 192.46.109.3
 继续查询可以发现该ip
对应的主机名为
继续查询可以发现该ip
对应的主机名为
 因此可以判断该客户端的会话被异常结束导致其持有的锁没有释放进而导致了大批量的锁冲突
因此可以判断该客户端的会话被异常结束导致其持有的锁没有释放进而导致了大批量的锁冲突
关于
5
月
10
日下午频繁出现应用链接不上数据库服务器问题已经找到
: 4
月13
日日志,4
月13
日存储crs
盘已经断开过,导致rac
软件集群状态不正常,crs
进程没有,重启节点后恢复正常。
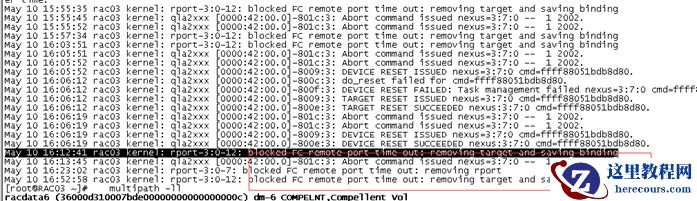
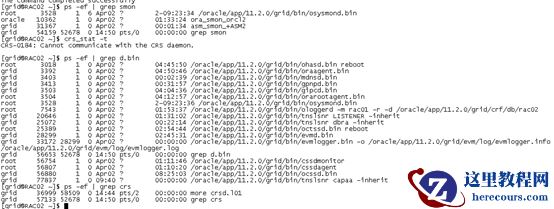 集群alert
日志
集群alert
日志
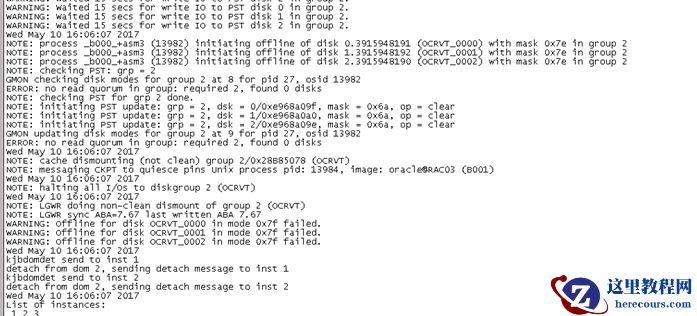
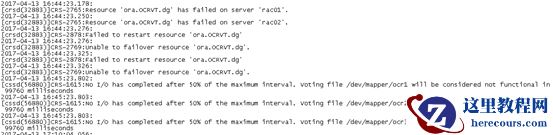 集群Asm
日志
集群Asm
日志
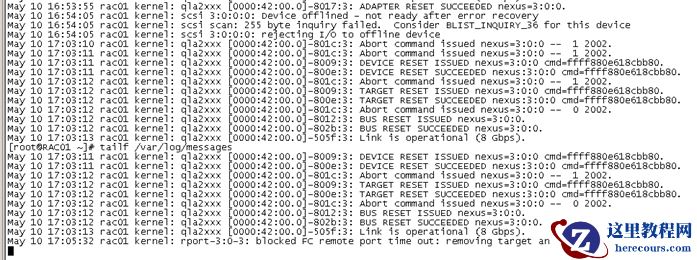
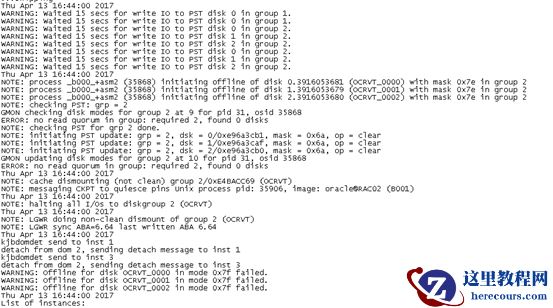 操作系统日志/var/log/messages
操作系统日志/var/log/messages
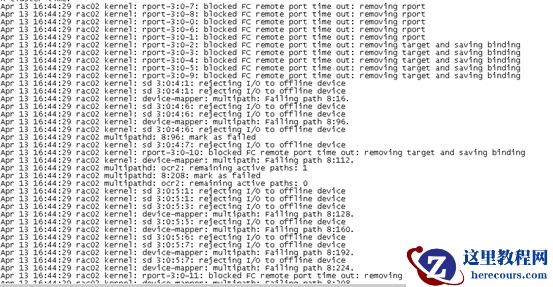 5
月10
日下午重启主机后还是出现相同状况,crs
盘掉了,导致集群服务不正常,应用无法正常连接数据库。确定是存储问题,crs
盘间歇性dismount
,将数据库切换至容灾,到时候排查存储问题。
5
月10
日下午重启主机后还是出现相同状况,crs
盘掉了,导致集群服务不正常,应用无法正常连接数据库。确定是存储问题,crs
盘间歇性dismount
,将数据库切换至容灾,到时候排查存储问题。
 ß
ß
后续建议
1、 加强对硬件的检查,定期查看硬件日志
2、 加强数据库方面的监控
3、 保证容灾的稳定性,以便发生灾难时顺利切换












