转自同事周乙的研究总结,记录一下!
关于 ckpt 的机制
何时发生 check point?
1. 每次 redo file switch 。
2. 当达到参数 LOG_CHECKPOINT_TIMEOUT 设置值。
3. 当有( LOG_CHECKPOINT_INTERVAL* IO OS 块大小)的字节大小写入当前重做日志文件时。
4. 当执行 alter system switch logfile 时。
5. 当执行 alter system checkpoint 时。
发生 check point 时, ckpt 进程会将检查点信息刷入控制文件,更新数据文件 header ,如下图所示:
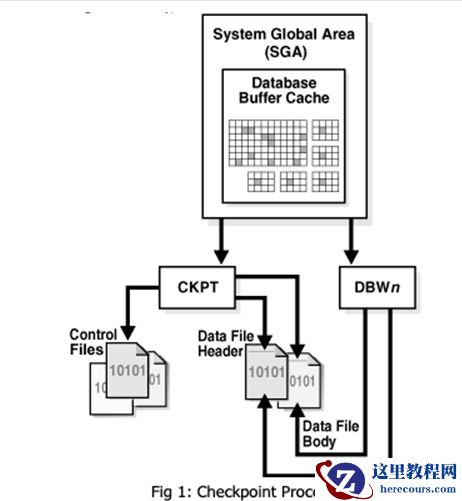
检查点又分为增量检查点以及全量检查点。
全量检查点: 所有 dirty blocks 刷回磁盘后,再进行更新控制文件以及数据文件 header 更新。
增量检查点:目的是避免在联机重做日志切换时写入大量块。 DBWn 至少每三秒检查一次以确定它是否有工作要做。 当 DBWn 写入脏缓冲区时, CKPT 会将检查点位置写入控制文件,而不是写入数据文件 header 。
以上内容来自: Primary Note: Overview of Database Checkpoints (Doc ID 1490838.1)
在 Oracle 8i 后,全量检查点只会发生在 shutdown database 与手工发起 alter system checkpoint 的时候。
增量检查点的工作涉及到 ckpt , lgwr , dbwr 三者的联动,在这里我们假设 os 层 IO 没有瓶颈。
Oracle 内置了一条 Checkpoint Queue ,主要用于两个方面:
1. 记录哪一些 dirty block 需要 dbwr 刷回磁盘。
2. 用于定位当 instance crash 后需要从 redo log 开始恢复的位置。
Checkpoint Queue 是一个脏缓冲区列表,按它们第一次脏的时间顺序排列。这条 Queue 也是 dbwr 进程用于识别哪些块需要被刷回磁盘。同时这条 Queue 也用于与 redo file 进行匹配,在这条 Queue 上的脏快在进行 crash recovery 的时候是需要被恢复的。
ckpt 进程会将 Checkpoint Queue 中第一个记录的 RBA 记录到 control file 中,以标记 checkpoint position 。 ckpt 进程每三秒就会刷一次 Checkpoint Queue 信息至 control file ,这个动作就是 incremental checkpoint 。
ckpt 进程也会在 redo 切换后刷新 checkpoint position 到数据文件 header ,但由于不是 full checkpoint ,所以不会刷新所有数据文件 header ,而是基于 Checkpoint Queue 计算判断刷新哪一个数据文件 header 。
dbwr 进程会基于 Checkpoint Queue 刷新 dirty blocks ,一旦 dbwr 刷新完成,它会将这些将这些刷新完的 blocks 信息从 Checkpoint Queue 移除并将刷新过的块的信息刷入 redo( 用于加速 crash recover) ,这时候 ckpt 进程又会刷新 Checkpoint Queue 信息到 control file ,如此往复。
有如下 3 个参数可以显式的控制 checkpoint queue 的长度
LOG_CHECKPOINT_TIMEOUT :指定(以秒为单位)自上次写入 redo 的 incremental checkpoint 以来经过的时间量。 此参数还表示 dirty blocks (在 buffer 中)超过整数秒。
LOG_CHECKPOINT_INTERVAL :根据 incremental checkpoint 和写入 redo 的最后一个块之间可以存在的 redo log file blocks 的数量来指定 checkpoint 的频率。 这个数字是指物理操作系统块,而不是数据库块。同时这个参数在非 0 时才有意义。
FAST_START_MTTR_TARGET :基于需要恢复的 redo 数量进行恢复,从而控制 checkpoint Queue 的长度,使用时需要移除 LOG_CHECKPOINT_INTERVAL, 和 LOG_CHECKPOINT_TIMEOUT 的设置,因为会被上述两个参数覆盖。
另外还有一个计算 checkpoint position 的内置考量点, 90% 最小 redo 。如下图所示:
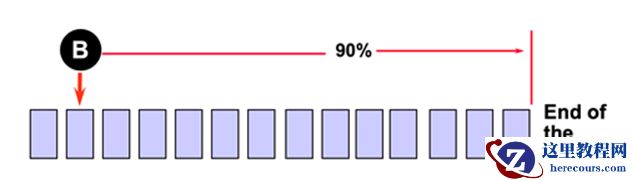
这个区间则是 90% 最小 redo
这 3 个参数与 90% 最小 redo 的计算依据都是在 incremental checkpoint 到 end of the redo 之间,而 checkpoint queue 则是就是 incremental checkpoint 到 end of the redo 之间的长度。由于除非数据库关闭,否则 the end of redo 是一直在变化的,所以 incremental checkpoint 的更新速度就会在上述三个参数的控制下加速 / 减缓,从而控制 checkpoint queue 的长度。到这里应该注意到,调整这三个参数的本质,就是控制 dbwr 进程刷 dirty blocks 的速度。
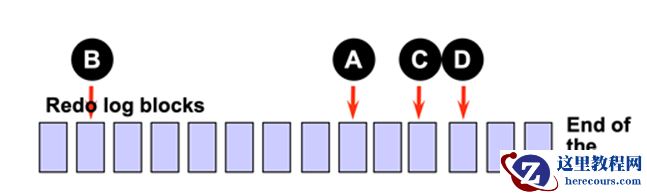
假设 FAST_START_MTTR_TARGET 为 A , 90% 最小 redo 为 B , LOG_CHECKPOINT_TIMEOUT 为 C , LOG_CHECKPOINT_INTERVAL 为 D
4 者控制 checkpoint queue 长度如下图所示:
有了上述这些基础机制,我们开始讨论我们的 case 。
Ckpt 进程只会告知 dbwr 进程需要开始工作,但是不会强制 dbwr 进程去刷块,最终一次刷新多少,是由 dbwr 进程决定,而 dbwr 进程刷多少,则是由上述 4 个控制因素以及 end of the redo 来决定的。 Ckpt 进程只会强制自己将 checkpoint 与 redo 的 RBA 写入 control file 。如果此时 checkpoint queue 中记录的 dirty blocks 大于上述 4 个控制因素决定的 queue 长度, dbwr 才会全力去刷新 dirty blocks ,否则它将会按照自己的节奏慢慢的去刷 dirty blocks ( lazy write )。
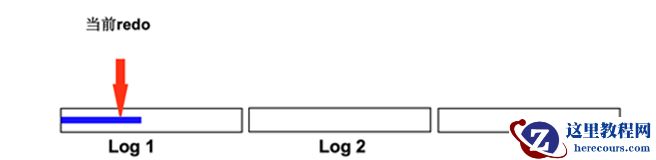
Redo file 的 active 与 inactive (红色进度条为需要刷回磁盘的 dirty blocks ,蓝色为还未刷回磁盘的 dirty blocks 也就是 check point queue 的长度):
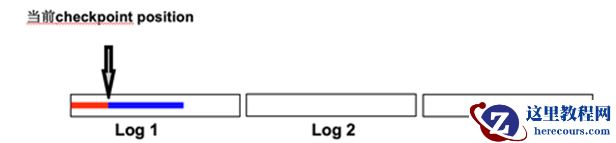
1. 此时 current redo 为 log 1 :
2. 当前 checkpoint :
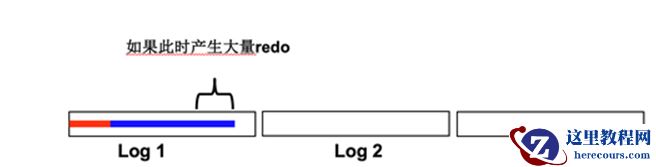
3. 大量 redo 产生:
4. Checkpoint queue 的变化:
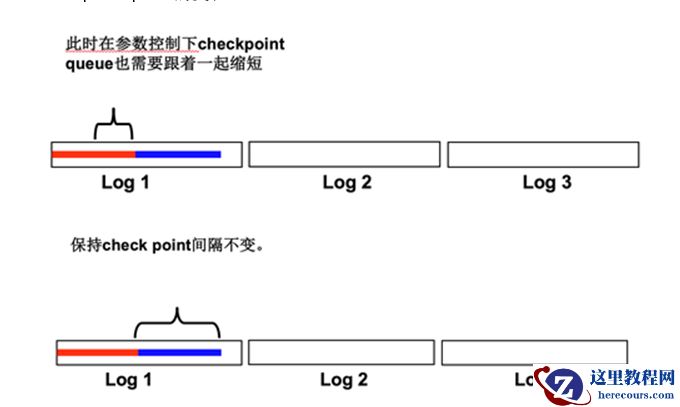
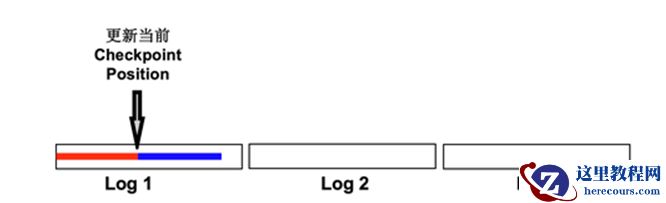
1-4 描述了在单一 redo 中 checkpoint queue 以及 checkpoint queue 的变化
5. 当 checkpoint 横跨两份 redo 时:
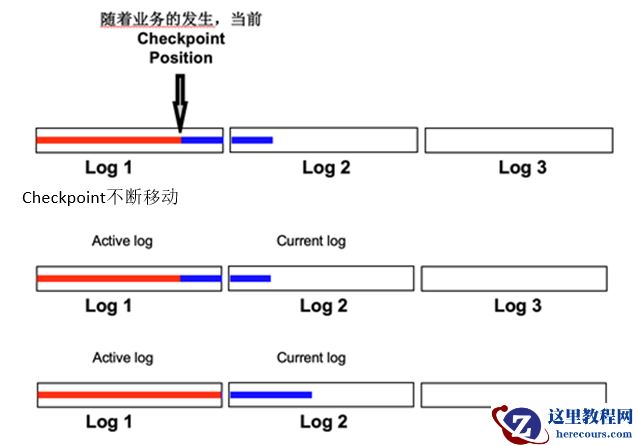
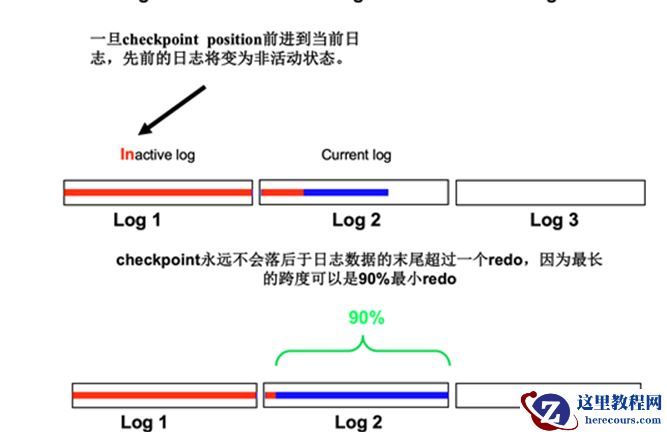
Checkpoint 不断移动
所以 inactive 的 redo 少于 2 组,是因为 checkpoint queue 的长度决定的。而如果增长 / 缩短 checkpoint queue 则是由 FAST_START_MTTR_TARGET , 90% 最小 redo , LOG_CHECKPOINT_TIMEOUT , LOG_CHECKPOINT_INTERVAL 来共同决定的,在 oracle 10G 以后,更多情况下,是由参数 FAST_START_MTTR_TARGET 来进行控制的,如非必要,不会单独去调整 LOG_CHECKPOINT_TIMEOUT , LOG_CHECKPOINT_INTERVAL ( 90% 最小 redo 是硬性条件,无法调整。)。
所以在 os 没有 io 瓶颈, ckpt , lgwr , dbwr 都工作正常的情况下, inactive redo log 少于 2 组,也是正常现象。
至此 active/inactive redo 问题解释完成。 既然 inactive redolog 是正常行为, 那么如何跟不正常行为区分开呢? 正常的 inactive redo 数量是 db 的正常工作的机制保证的,而不正常的 inactive redo 数量是因为 db 异常 /io 异常等等因素造成的。 如果我们能够知道全天最大每秒日志量, redo 大小,日志组数,通过这三者可以大概计算出如何设置 mrrt 可以保证至少有多少个 inactive redo ,如果低于这个值的 inactive redo 数量,则可视为不正常。 我们为另外一些客户做过类似的控制,大致的计算公式为: 我们取全天日志产生量最大的时间段(大概 10 分钟)的日志平均每秒的产生量为 N ; 日志组数为 Y ;需要 inactive redo 数为 X ;每组日志大小为 Z , FAST_START_MTTR_TARGET 设置值为 M ( LOG_CHECKPOINT_TIMEOUT 与 LOG_CHECKPOINT_INTERVAL 不能设置) M=(Y-X)*Z/N 这样就可以从机制上来控制 inactive redo 数量。 换句话说,只要比较 v$instance_recovery 中的 actual_redo_blks 是否小于当前 sum(active redolog blocks) 就可以! 如果小于,代表 DBWR 在不断推进 incremental checkpoint ,这种情况下没有问题;反之如果 actual_redo_blks 在不断增加,而且和 sum(active redolog blocks) 相当,代表数据库出现问题。如果 inactive redolog < 2 组,则数据库会 hang 。






")


