一
创建测试表t1,id列创建索引in_t1_id
select
default_tablespace
from
dba_users
where
username
=
'CHEN'
;

create table t1 as select level as id from dual connect by level<=300000; create index in_t1_id on t1(id); analyze table t1 compute statistics; select count(*) from t1;
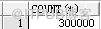 二
查看表T1段4M,占用473个数据块,39个空块;索引IN_T1_ID段6M;
select
sum
(
bytes
)/
1024
/
1024
from
dba_segments
where
segment_name
=
'T1'
;
二
查看表T1段4M,占用473个数据块,39个空块;索引IN_T1_ID段6M;
select
sum
(
bytes
)/
1024
/
1024
from
dba_segments
where
segment_name
=
'T1'
;
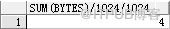 select
sum
(
bytes
)/
1024
/
1024
from
dba_segments
where
segment_name
=
'IN_T1_ID'
;
select
sum
(
bytes
)/
1024
/
1024
from
dba_segments
where
segment_name
=
'IN_T1_ID'
;
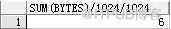 SELECT
blocks
,
empty_blocks
,
num_rows
FROM
user_tables
WHERE
table_name
=
'T1'
;
SELECT
blocks
,
empty_blocks
,
num_rows
FROM
user_tables
WHERE
table_name
=
'T1'
;
 三
查看没有数据的块占用的空间
DBMS_STATS包无法获取EMPTY_BLOCKS统计信息,所以需要用analyze命令再收集一次统计信息
估算表在高水位线下还有多少空间可用
,这个值应当越低越好,表使用率越接近高水位线,全表扫描所做的无用功也就越少!
三
查看没有数据的块占用的空间
DBMS_STATS包无法获取EMPTY_BLOCKS统计信息,所以需要用analyze命令再收集一次统计信息
估算表在高水位线下还有多少空间可用
,这个值应当越低越好,表使用率越接近高水位线,全表扫描所做的无用功也就越少!
SELECT TABLE_NAME, (BLOCKS * 8192 / 1024 / 1024) - (NUM_ROWS * AVG_ROW_LEN / 1024 / 1024) "Data lower than HWM in MB" FROM USER_TABLES WHERE table_name = 'T1';
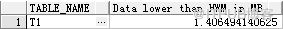 四
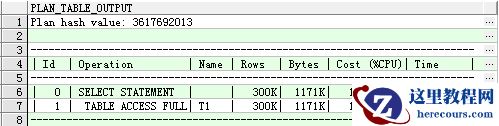
查看全表扫描占用CPU为133
四
查看全表扫描占用CPU为133
explain plan for select * from t1; select * from table(dbms_xplan.display);
 五
删除大部分数据,并收集统计信息,查看T1占用数据块和空块都没有减少
delete
from
t1
where
id
>
10
;
五
删除大部分数据,并收集统计信息,查看T1占用数据块和空块都没有减少
delete
from
t1
where
id
>
10
;

analyze table t1 compute statistics; SELECT blocks, empty_blocks, num_rows FROM user_tables WHERE table_name ='T1';
 六
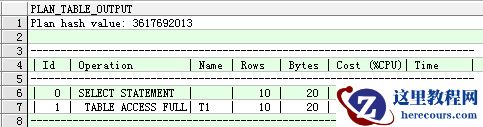
查看全表扫描占用CPU为130,CPU使用几乎没有下降
六
查看全表扫描占用CPU为130,CPU使用几乎没有下降
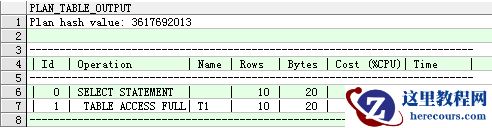
explain plan for select * from t1; select * from table(dbms_xplan.display);
 七
查看没有数据的块占用的空间
七
查看没有数据的块占用的空间
SELECT TABLE_NAME, (BLOCKS * 8192 / 1024 / 1024) - (NUM_ROWS * AVG_ROW_LEN / 1024 / 1024) "Data lower than HWM in MB" FROM USER_TABLES WHERE table_name = 'T1';
 八
整理表碎片
八
整理表碎片
alter table t1 enable row movement; alter table t1 shrink space cascade; alter table t1 disable row movement; select sum(bytes)/1024/1024 from dba_segments where segment_name='T1';
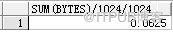 select
sum
(
bytes
)/
1024
/
1024
from
dba_segments
where
segment_name
=
'IN_T1_ID'
;
select
sum
(
bytes
)/
1024
/
1024
from
dba_segments
where
segment_name
=
'IN_T1_ID'
;

SELECT TABLE_NAME, (BLOCKS * 8192 / 1024 / 1024) - (NUM_ROWS * AVG_ROW_LEN / 1024 / 1024) "Data lower than HWM in MB" FROM USER_TABLES WHERE table_name = 'T1';
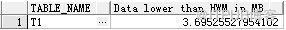 九
收集统计信息
analyze
table
t1
compute
statistics
;
十
占用数据块及空闲数据块下降,并且CPU使用也下降了
九
收集统计信息
analyze
table
t1
compute
statistics
;
十
占用数据块及空闲数据块下降,并且CPU使用也下降了
SELECT TABLE_NAME, (BLOCKS * 8192 / 1024 / 1024) - (NUM_ROWS * AVG_ROW_LEN / 1024 / 1024) "Data lower than HWM in MB" FROM USER_TABLES WHERE table_name = 'T1';
 select
blocks
,
empty_blocks
,
num_rows
from
user_tables
where
table_name
=
'T1'
;
select
blocks
,
empty_blocks
,
num_rows
from
user_tables
where
table_name
=
'T1'
;

explain plan for select * from t1; select * from table(dbms_xplan.display);
 其他
1.再用alter table table_name move时,表相关的索引会失效,
所以之后还要执行 alter index index_name rebuild online;
最后重新编译数据库所有失效的对象.
2. 在用alter table table_name shrink space cascade时,
他相当于alter table table_name move和alter index index_name rebuild online. 所以只要编译数据库失效的对象就可以
;
1. Move会移动高水位,但不会释放申请的空间,是在高水位以下(below HWM)的操作。
2. shrink space 同样会移动高水位,但也会释放申请的空间,是在高水位上下(below and above HWM)都有的操作。
原理不一样,move是以block为单位重组数据,行的rowid都会跟着变化,
而shrink是以
”
行
“
为单位重组数据,他是根据复杂的算法从逻辑+物理重组数据
move 速度快于 shrink.
Move 相当于 从segment 底部 move到 头。
Shrink 相当于先delete,然后再insert这样产生很多undo,redo
通常首 选 MOVE
语法:
alter
table
<table_name>
shrink
space
[
<null>
|
compact
|
cascade
];
alter
table
<table_name>
shrink
space
compcat;
segment shrink分为两个阶段:
1、数据重组(compact):通过一系列insert、delete操作,将数据尽量排列在段的前面。
在这个过程中需要在表上加RX锁,即只在需要移动的行上加锁。由于涉及到rowid的改变,
需要enable row movement.同时要disable基于rowid的trigger.这一过程对业务影响比较小。
2、HWM调整:第二阶段是调整HWM位置,释放空闲数据块。此过程需要在表上加X锁,会造成表上的所有DML语句阻塞。
在业务特别繁忙的系统上可能造成比较大的影响。
Shrink Space
语句两个阶段都执行。Shrink Space compact只执行第一个阶段。
如果系统业务比较繁忙,可以先执行Shrink Space compact重组数据,然后在业务不忙的时候再执行Shrink Space降低HWM释放空闲数据块。
shrink必须开启行迁移功能。
其他
1.再用alter table table_name move时,表相关的索引会失效,
所以之后还要执行 alter index index_name rebuild online;
最后重新编译数据库所有失效的对象.
2. 在用alter table table_name shrink space cascade时,
他相当于alter table table_name move和alter index index_name rebuild online. 所以只要编译数据库失效的对象就可以
;
1. Move会移动高水位,但不会释放申请的空间,是在高水位以下(below HWM)的操作。
2. shrink space 同样会移动高水位,但也会释放申请的空间,是在高水位上下(below and above HWM)都有的操作。
原理不一样,move是以block为单位重组数据,行的rowid都会跟着变化,
而shrink是以
”
行
“
为单位重组数据,他是根据复杂的算法从逻辑+物理重组数据
move 速度快于 shrink.
Move 相当于 从segment 底部 move到 头。
Shrink 相当于先delete,然后再insert这样产生很多undo,redo
通常首 选 MOVE
语法:
alter
table
<table_name>
shrink
space
[
<null>
|
compact
|
cascade
];
alter
table
<table_name>
shrink
space
compcat;
segment shrink分为两个阶段:
1、数据重组(compact):通过一系列insert、delete操作,将数据尽量排列在段的前面。
在这个过程中需要在表上加RX锁,即只在需要移动的行上加锁。由于涉及到rowid的改变,
需要enable row movement.同时要disable基于rowid的trigger.这一过程对业务影响比较小。
2、HWM调整:第二阶段是调整HWM位置,释放空闲数据块。此过程需要在表上加X锁,会造成表上的所有DML语句阻塞。
在业务特别繁忙的系统上可能造成比较大的影响。
Shrink Space
语句两个阶段都执行。Shrink Space compact只执行第一个阶段。
如果系统业务比较繁忙,可以先执行Shrink Space compact重组数据,然后在业务不忙的时候再执行Shrink Space降低HWM释放空闲数据块。
shrink必须开启行迁移功能。
###chenjuchao 2016-03-10###












