一、故障描述
某次,用户某套数据库出现了非常严重的性能问题,数据库响应变的很慢,业务这块几乎出现全局不可用的情况,情况非常紧急。业务恢复后,我们对该数据库进行自上而下的分析,发现在故障时间段的确出现了大量的等待事件,诸如: log file sync 、 log file parallel write 等,经过下钻分析,定位主机资源使用也出现了瓶颈。下文,我们将详细展开分析。
二、根因分析
查询数据库异常时间内的等待事件,发现被 5 152 进程阻塞
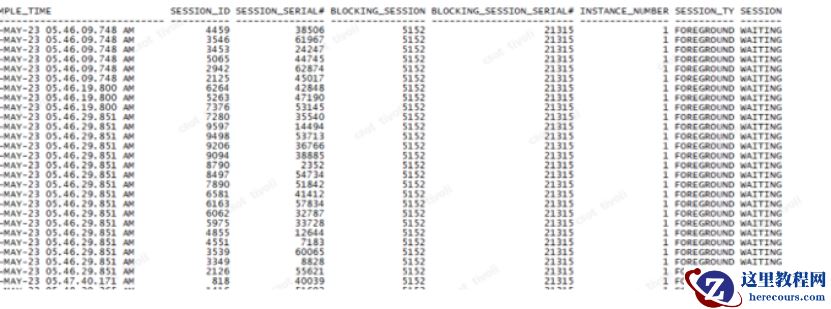
对 5 152 进程进行查询发现阻塞的事件为 log file parallel write

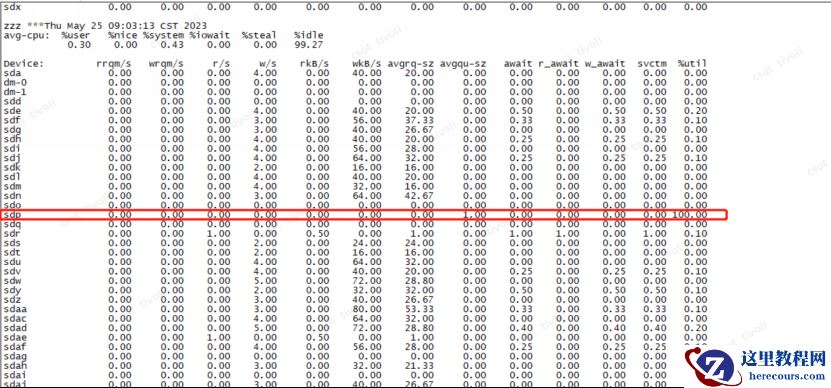
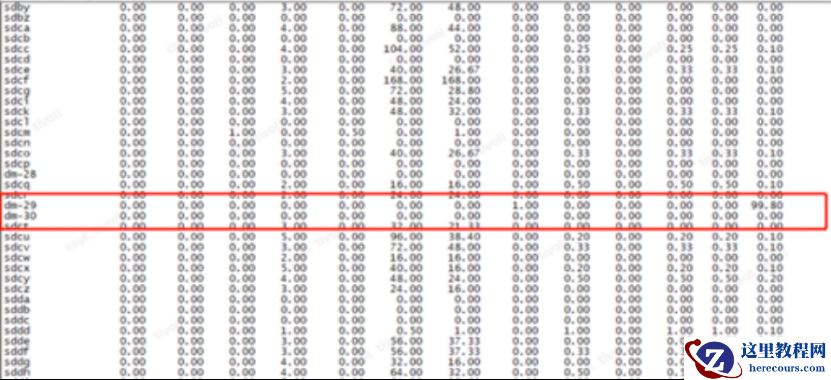
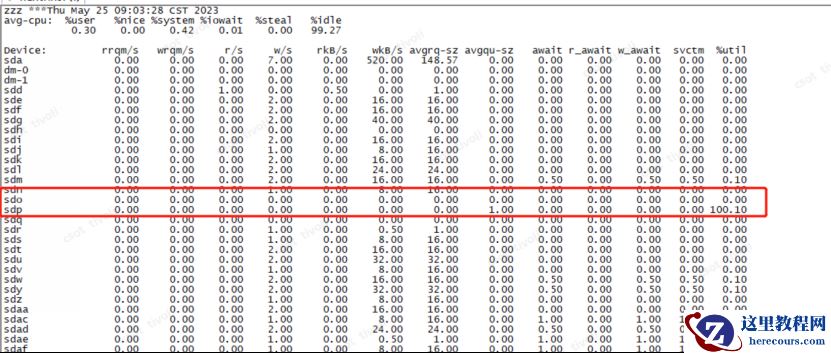
通过 osw对异常期间内磁盘io状态,发现s dp 和 dm -29 盘在性能故障期间繁忙程度为 1 00 %
当天,下午 16点53分
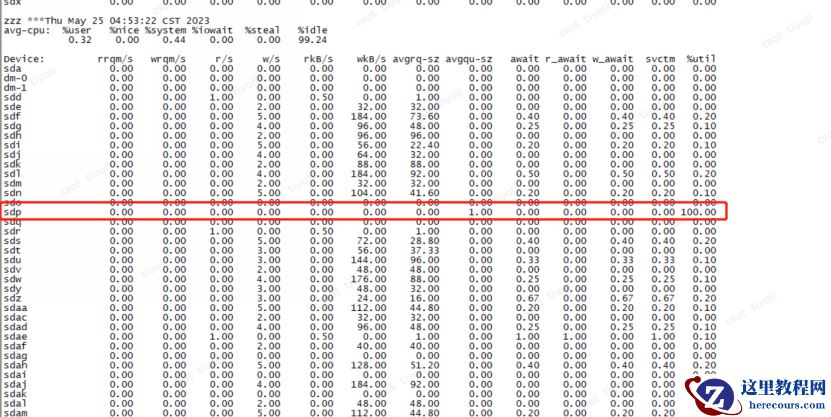
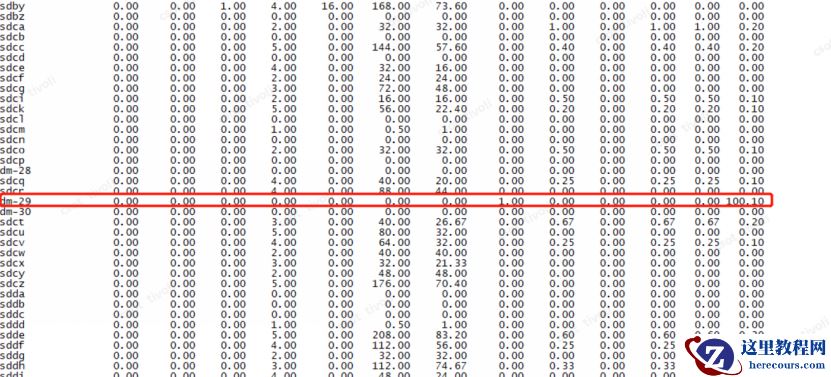
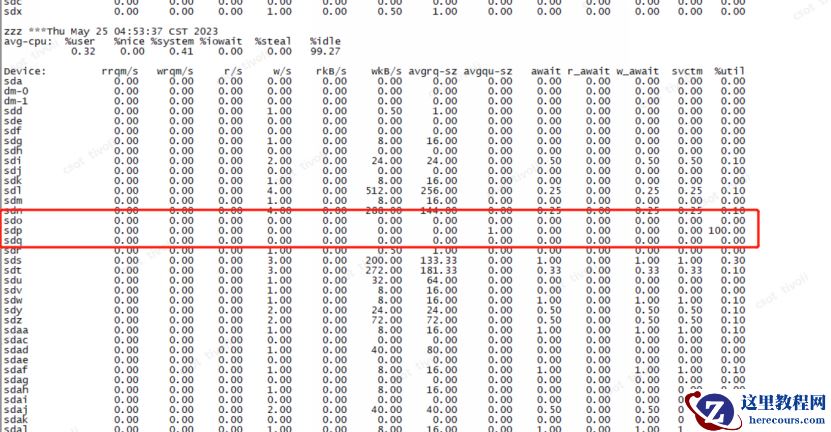
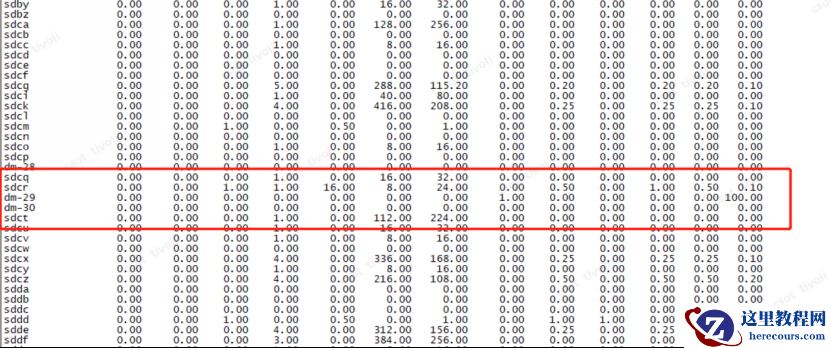 第二天,上午
9点0
3
分
第二天,上午
9点0
3
分
三、解决方案
根据业务操作超时时间追踪定位,超时期间数据库等待log file sync 异常激增,造成等待的原因为磁盘 IO hang 住导致 lgwr 日志写进程等待 ,业务紧急切换到 2 节点后恢复正常。业务正常后,我们初步怀疑可能是 1 节点到存储链路有问题,随后用户参考了我们的意见,拉通存储产商检查了存储控制器、光纤链路、光模块、 H BA 卡等,最终核实了存储问题。







")

")
