背景概述
该故障数据库是某银行的一套运行在一套3节点RAC环境上的Oracle数据库,故障现象为在凌晨的时间段, 数据库一节点频繁地因为LMS进程超时而被实例级别KILL,当时获取了最近一次重启的日志分析,并结合 当前数据库的一些现有问题进行分析,给出具体的故障结论和处理建议。
故障一节点alert日志:

从以上信息看,数据库在正常运行过程中,突然因LMS0进程长时间无法得到响应被LMHB进程监控到后,LMHB进程对实例进行了KILL。
故障一节点的LMS0进程日志
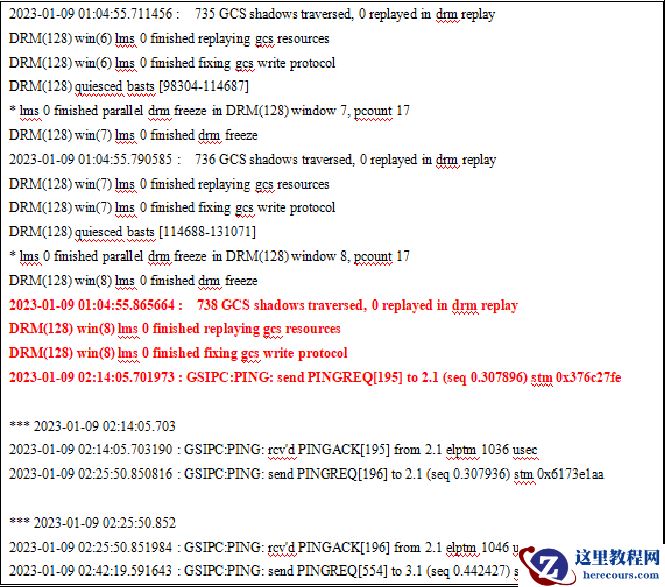
故障前,LMS进程日志显示有发生部分的的DRM数据freeze,虽然整体操作都成功了,但还是会一定程度上加剧gc的繁忙,并且一定程度上影响到LMS进程的响应。
故障节点前的AWR报告分析
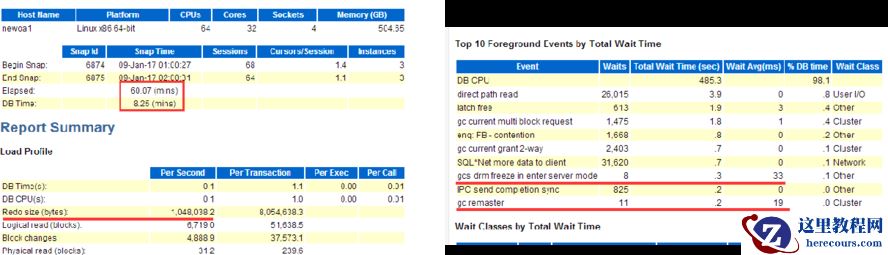
从故障前的时间点看,整体的CPU使用率较低,不过和之前想的一样,数据库存在一定的DRM数据freeze,整体的操作是成功的,相对来说存在一定的延迟。DRM在一定程度上加剧了GC的繁忙,以及在一定程度上影响了LMS进程的响应,导致了实例的kill。
故障节点OSWatch中CPU资源分析
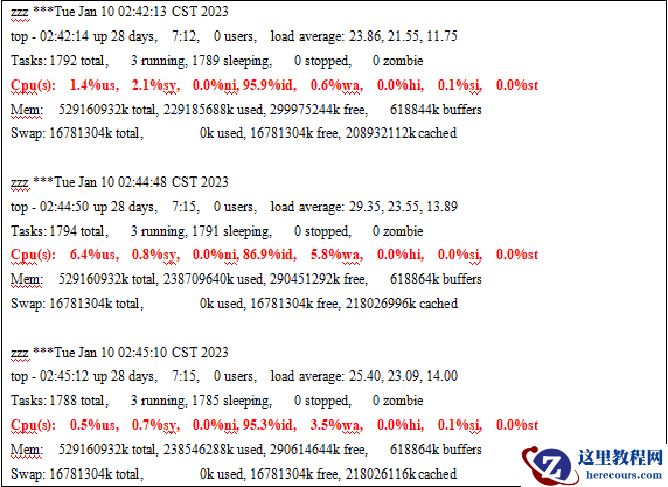
由于故障时间点的OSWatch日志已经被覆盖,考虑到银行业务逻辑相对简单,不存在复杂多变的可能,故障时间节点后一天凌晨2点左右的日志应该同样具有参考性,可以收集OSWatch日志并进行分析。从OSWatch上看,故障时间点的CPU并没有压力,所以可以排除CPU部分的可能。
故障节点OSWatch中内存资源分析

同样的,在故障节点的osw内存收集的日志中,内存还是较为空闲的。
故障节点OSWatch中IO资源分析
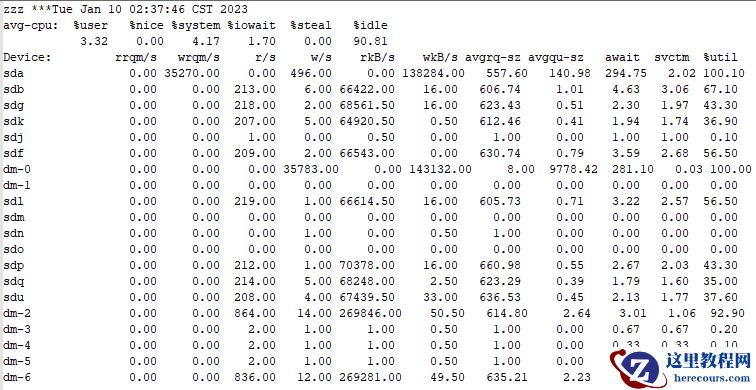
可以看到,在故障节点,本地盘的写IO非常厉害(每秒140M写入),而存储盘的读IO非常严重(每秒450M的读)而结合之前内存部分的分析,数据库并没有严重的交换产生,所以我们可以排除本地磁盘的写IO是交换引起的,考虑读写同时发生,结合crontab中的备份检查,可以确定,故障时间点应该是在做备份,从存储读出,写入到本地文件夹的备份。
故障节点OSWatch中网络资源分析
由于LMS涉及集群网络层的心跳服务,同样需要排查节点间心跳网络是否正常。心跳网络的失败率较少,一般该指标超过1000并且存在严重的抖动,才能说明心跳网络存在不稳定性,对比故障恢复后的心跳网络发现没有存在抖动的情况,说明心跳网络正常。 结合当前的日志分析结论,初步判定在故障期间,主机四大资源中,IO资源在故障时间点,基本耗尽,虽然当前的OSWatch 并不是故障时间点的日志,但是依旧存在很大的参考性。怀疑在故障时间,LMS0进程因长时间得不到IO层的响应而导致进程 超时,进一步导致实例层面的KILL。 根据以上故障结论,当时给出如下的建议: 1. 结合跑批运行时间,结合3套数据库的备份时间点,错开运行备份 2. 不要将备份放在本地磁盘上,或者错开时间将备份放在不同的实例主机上,更或者直接备份到远端。 3. 如果有条件实现第二点,在优化备份的基础上,为了降低存储的读,可以在备份的时候进行适当的备份限速。 4. 从故障看,DRM也在一定程度造成了GC的繁忙,并且从目前的情况看DRM BUG较多,有条件的话可以考虑关闭该特性。 事后客户按照如上建议做了整改,没有再出现过二节点实例被kill的情况了。






")
")




