问题描述:
2024/05/30 11:38 客户反馈,业务在 2024-05-29 9:49到2024-05-29 9:52之间的一条简单的insert语句原先执行时间很短,出问题时候比原来慢了20秒左右。 SQL_ID:83n6zhg6765uw 语句如下:insert into XXX values (:s1 ,:s2 ,:s3 ,:s4 ,:s5 ,:s6 ,:s7 ,:s8 ,:s9 ,:s10 ,:s11 ,:s12 ,:s13 ,:s14 ,:s15 ); 该问题前面出现过两次,第一次是 2023年5月10日,第二次是2024年3月19日。现象类似,都是简单的insert语句出现了几笔超时。问题诊断和分析:
1. 整体数据库压力很小
问题时间段前后,数据库整理压力不大,不是整体环境因素,导致的问题。另外也并没有出现其他业务的性能降低,只有 insert的单业务中的极小一次业务出现慢。
2. 业务量未出现明显暴涨
业务反馈,整理压力比较平均,不存在问题时间点有较大的 insert量。检查数据库每个快照(15分钟一个快照)的该SQL的执行次数如下,从整体的量来说,问题快照内执行次数有85618次,相较于虽然有一定增加,但是前面08:15的快照有92686次也没并出现问题。所以单纯从总量上来看,没有突增。
3. 数据库日志
1)Alert 日志
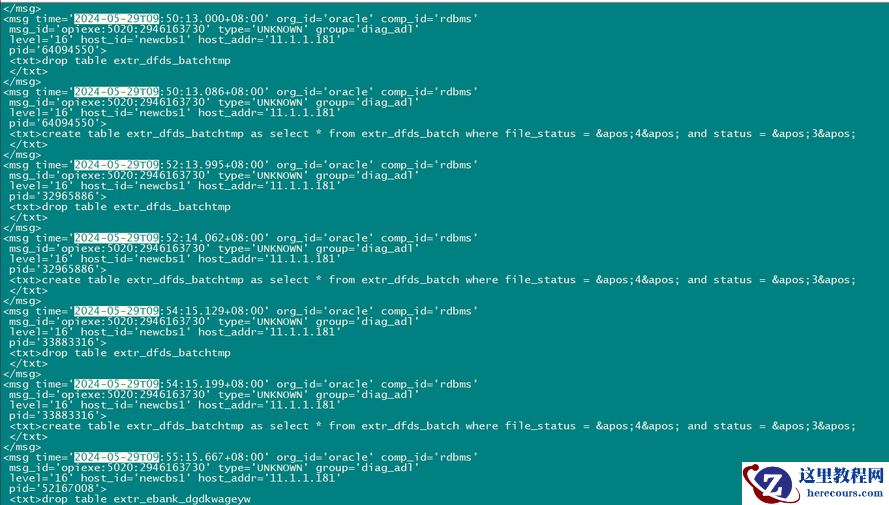
从数据库 alert日志中发现问题时间在9:50:41秒到9:52:04段刚好有一些如下信息,问题时间段前后很长一段时间段都没有这些信息,总体可以认为是热点块,ORACLE对这种信息未定位为错误,只是一种打印信息,为了不引起误解,会在后续版本取消。不能说有问题,但是也反应出这个时间点是有热点快。另外时间继续拉长,日志也会有一些类似如下的信息,但没有业务反馈有问题。
2024-05-29T09:41:09.164245+08:00
KQR: cid 8 bucket 25979 marked NORMAL
2024-05-29T09:45:20.338596+08:00
KQR: cid 8 bucket 9760 marked HOT (kqrCreateUsingSecondaryKey)
2024-05-29T09:50:41.130515+08:00
Thread 1 advanced to log sequence 86258 (LGWR switch), current SCN: 554511565598
Current log# 7 seq# 86258 mem# 0: +DATA/NEWCBS/redo07.log
2024-05-29T09:50:42.661322+08:00
ARC2 (PID:27066738): Archived Log entry 281025 added for T-1.S-86257 ID 0xffffffffff03acc4 LAD:1
2024-05-29T09:51:37.716533+08:00
KQR: cid 8 bucket 19928 marked HOT (kqrCreateUsingSecondaryKey)
2024-05-29T09:51:37.954178+08:00
KQR: cid 8 bucket 11914 marked HOT (kqrCreateUsingSecondaryKey)
2024-05-29T09:51:38.060354+08:00
KQR: cid 8 bucket 17490 marked HOT (kqrCreateUsingSecondaryKey)
2024-05-29T09:51:38.144463+08:00
......(省略)
KQR: cid 8 bucket 25016 marked HOT (kqrCreateUsingSecondaryKey)
2024-05-29T09:52:03.585169+08:00
KQR: cid 8 bucket 4328 marked HOT (kqrCreateUsingSecondaryKey)
2024-05-29T09:52:04.045723+08:00
KQR: cid 8 bucket 3039 marked HOT (kqrCreateUsingSecondaryKey)
2024-05-29T09:52:04.435243+08:00
KQR: cid 8 bucket 12018 marked HOT (kqrCreateUsingSecondaryKey)
2024-05-29T09:52:04.584624+08:00
KQR: cid 8 bucket 20464 marked HOT (kqrCreateUsingSecondaryKey)
2024-05-29T09:52:04.703736+08:00
KQR: cid 8 bucket 28610 marked HOT (kqrCreateUsingSecondaryKey)
2024-05-29T09:52:04.923833+08:00
KQR: cid 8 bucket 23992 marked HOT (kqrCreateUsingSecondaryKey)
2024-05-29T09:57:26.768859+08:00
KQR: cid 8 bucket 23865 marked HOT (kqrCreateUsingSecondaryKey)
2)Diag诊断日志
本次未发现问题期间有 DIAG日志产生
4. 异常等待
比对了 8点和9点的异常等待,主要差异是9点异常等待library cache lock 从1增加到113,其他等待区别不大,不用做重点关注。
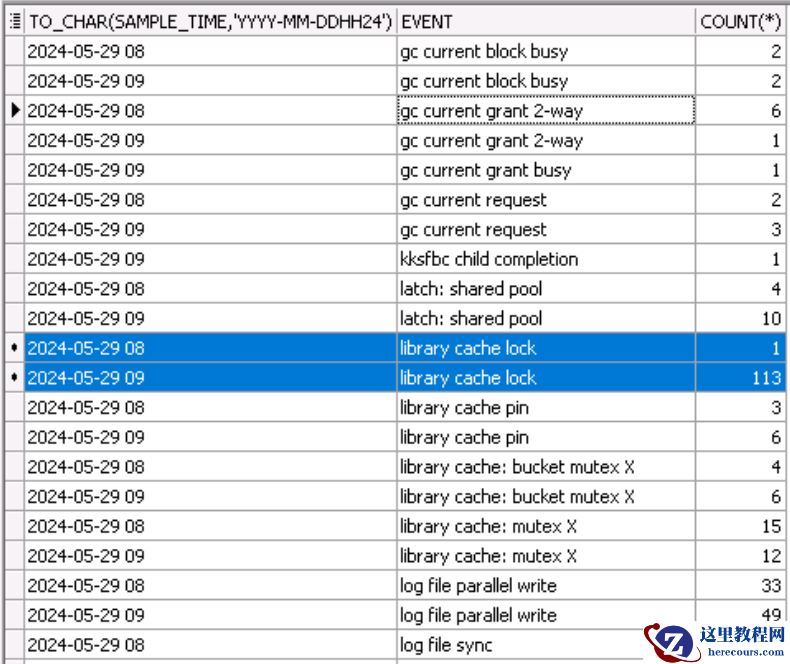
通过对客户反馈的问题时间段 9:49-9:52,将时间点细化到分钟,可以发现在9:51分开始library cache lock在9:51的时候从1个徒增到106个。时间点可以与业务反馈问题时间一致。
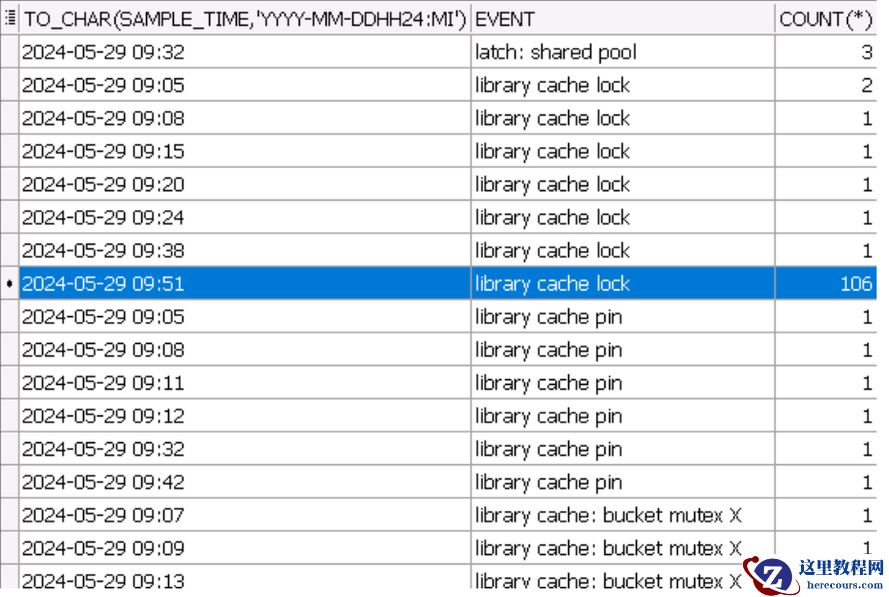
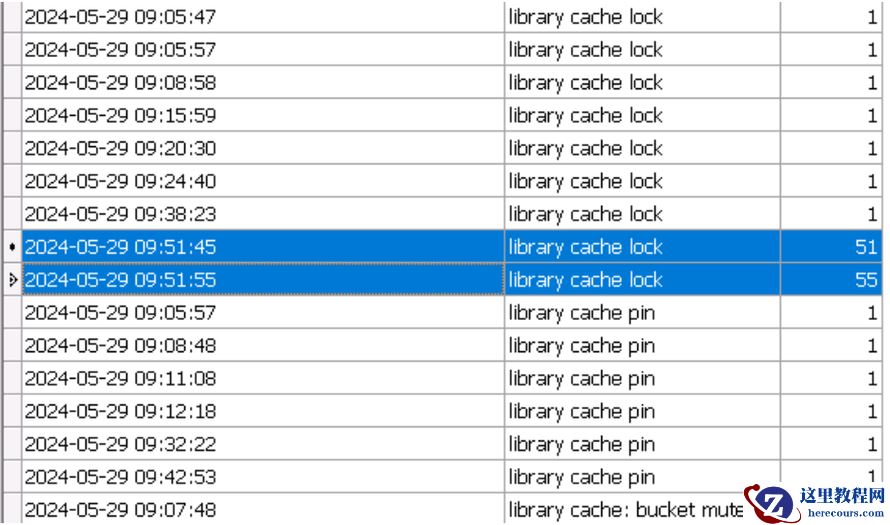
在细化到秒钟,可以发现时间主要集中在 9:51分45和55秒两个采样点之间
5. library cache lock 主要原因分析
参考了官方的 library cache lock 的分析文章,主要原因有如下8种,但是基本上都排除掉了。
1) Unshared SQL Due to Literals
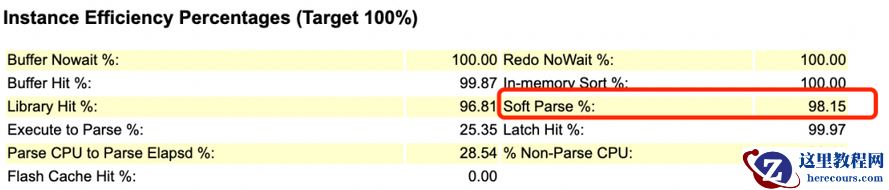
第一种情况:由于写法问题,导致 SQL无法共享游标,多指查询语句,目前是一个简单的insert values语句。且如果有过多无法共享,那么整体硬解析会很多,但是AWR显示硬解析很少。
2) Shared SQL being aged out
第二种情况:共享 SQL被刷出共享池,这种主要是指没有使用绑定变量,共享池空间不足,导致共享SQL被刷出。
目前数据库是开启了 ASMM自动管理,如果shared pool不足,会出现共享池自动扩展的操作,通过查询SGA的动态扩缩容视图,当天未发生shared pool扩容(历史有出现)。同时如果出现共享池不足,那么也不止这么一条SQL会有问题,会有较多的硬解析出现,可以看到AWR看,硬解析其实很少。
3) Library cache object Invalidations
当对象(如表或视图)通过 DDL或收集统计信息进行更改时,依赖于它们的游标将无效。这将导致游标在再次执行时被硬解析,并将影响CPU和锁存器。
首先: Library cache object对象无效,即表XX无效,主要是对象被alter之类的操作,通过DDL审计文件在问题时间段内有其他对象的DDL,但是未发现insert对象(XX表)的DDL操作
其次:统计信息导致问题,通常是晚上 SQL tuning advisor 这个作业执行后导致的,但是我们生产环境已经将该作业关闭了。另外该表是否当时出现了动态的统计信息收集,不确定,但是可以确认的是如果统计信息发生变化,那么该表涉及也有其他语句,并不会仅仅该简单的 insert出现library cache lock。
4) Objects being compiled across sessions
第四种情况:访问期间对象正在被编译。目前对象是表,没有编译一说,这种情况主要是指存储过程,函数等可以编译对象被编译导致的 latch.
5) Cause Identified: Auditing is turned on
6) Unshared SQL in a RAC environment 类似1.
7) Extensive use of row level triggers
目前确认没有这个触发器,如果有,触发器是实时都会触发的,故障频率肯定不是偶尔出现。
8) Excessive Amount of Child Cursors
即子游标的版本很多,即 SQL的VERSION_COUNT值很高,一般查询语句超过500基本上会发生问题,通过AWR查询,并未发现这条SQL有多版本问题。
6、 SQL语句
几乎所有的 library cache lock 对应的SQL都是83n6zhg6765uw:
insert into XXX values (:s1 ,:s2 ,:s3 ,:s4 ,:s5 ,:s6 ,:s7 ,:s8 ,:s9 ,:s10 ,:s11 ,:s12 ,:s13 ,:s14 ,:s15 ) 与业务反馈的一致,是很简单的 insert语句.
7. 堵塞着分析
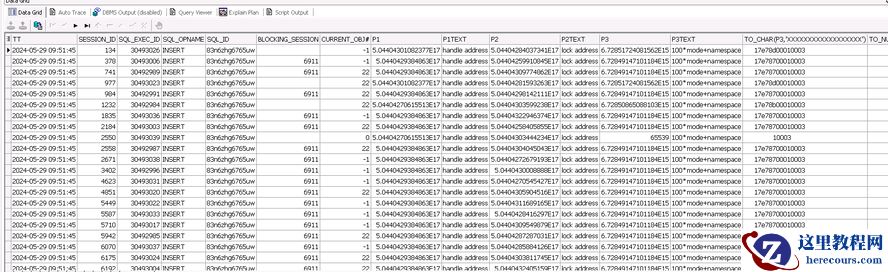
1)Library cache lock堵塞情况:堵塞者及堵塞次数
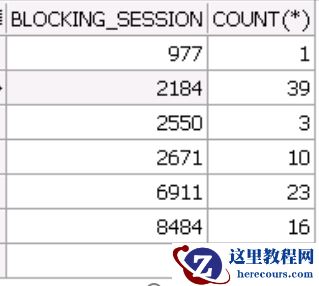
通过对 library cache lock会话的6个blocking_session进行分析,发现基本上blocking session的语句也都是同样的insert 语句。

blocking_session会被其他session堵塞,但是一层一层查下去,发现最终都指向8484。
8484这个会话等待事件也是Library cache lock,语句也是相同的INSERT语句。
2)Library cache lock的句柄分析
所有 Library cache lock等待事件对应的P3: '100*mode+namespace' 值转换成16进制后类似17e78d00010003,后面0001,和0003分别代表namspace 和申请的lock mode,其中namespace=1 代表是TABLE/PROCEDURE,mode=3 表示exclusive的。命名空间是TABLE说明是table类型的handle上等待latch.按照上次与原厂沟通确认这类insert对应的library cache lock主要发生原因为在表涉及段空间不足,无法满足insert需求的时候,需要进行段自动扩展(分配区extent),在扩展的过程,需要获取了排他锁。在第一条insert之后的所有其他相同insert就无法获取排他锁就产生library cache lock等待。
7. 回收站清理:
曾经也处理过很多类似 latch案例,但是我们这次情况,基本上从library cache lock 主要原因里面排除掉了,但是有一个例外场景有点类似,但是不是完全匹配,他们的场景是insert ...select 且select时候加了并发,也是出现了较多library cache lock.他的原因是在发现有清理回收站的内部语句(非人为),不过我们本次并未发现。
我们知道对象被删除,会被放入回收站里,对象标记为删除,但是实际并未清理,物理仍然保持在对应的表空间内,供恢复。当空间不足的时候,可以去复用这部分空间,这时候就会触发回收站清理。
不排除是由于空间不足,需要段扩展,但是也内部触发了回收站的对象清理。由于清理回收站并不会对当前对象影响。建议对回收站进行清理,排除这个因素。 总结:
结合根据本次情况分析 问题时间段内多条insert语句产生了较多library cache lock等待,等待都发生在TABLE上进行段扩展(无足够空间供插入需求),获取排他锁失败, 一直等待 library cache lock,直到第一个持有排他锁的会话(8484)释放排他锁,其他insert语句恢复正常。目前最大可能性还是空间不足导致的表extent 进行空间扩展导致的。另外为了降低问题概率,也可以手工清理下回收站。
解决方案
方案 1:官方建议手工对表的extent 进行空间扩展参考如下
alter table t1 allocate extent (size 32M instance 2),但是insert 是应用程序发起,手工和频繁的进行扩容显然不合理也不现实,由于这个AB表每天晚上要进行truncate,所以建议在truncate后,对表进行一次手工扩容,扩容的大小建议超过每天实际生产大小,方案建议先进行测试环境测试。
方案 2:手工清理回收站所有对象,避免受该因素影响,命令如下,请参考。 purge dba_recyclebin; ==》建议清理回收站所有对象。 purge user_recyclebin; ==》清理当前用户回收站对象 purge table xx.xx; ==》具体对象回收站清理 alter system set recyclebin=off scope=both sid='*' ==》关闭回收站
方案 3:由于也是很偶尔才发生,所以在业务层面能否控制insert的并发度。







")


