1.OGG高可用是DBA的生命线?
OGG进程宕机=数据断流。单节点部署的OGG,一旦遭遇存储故障、主机崩溃或网络闪断,同步延迟将呈指数级飙升,业务停摆只是时间问题.
即使已有RAC(实例级冗余)和DG(数据库级冗余),OGG的同步链路仍是单点。当主库RAC节点宕机,OGG进程若未自动切换,容灾架构瞬间崩塌.
2.OGG HA架构
Oracle集群+ACFS+XAG
ACFS共享存储:一刀斩断单点故障 将OGG配置文件、检查点、日志文件存入ACFS卷,任意节点宕机秒级接管,彻底告别存储单点故障引发的全链路中断!
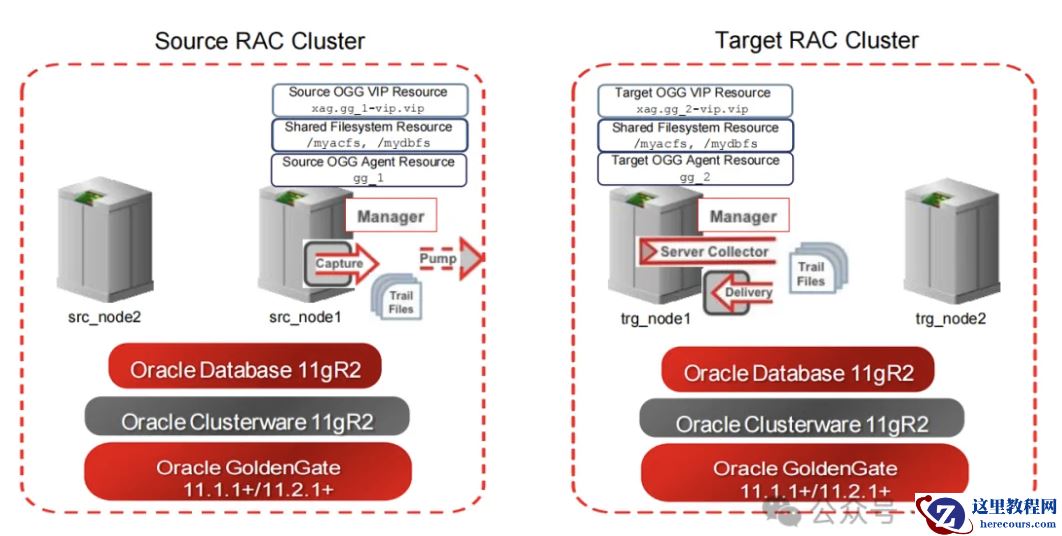
Oracle集群+NFS+HA切换脚本
存储层:NFS共享OGG配置文件、检查点(dirchk)及日志(dirdat),确保故障切换时新节点可无缝读取数据。
集群管理:HA脚本集成Oracle Clusterware,监控OGG进程状态,异常时自动触发切换。
节点宕机后,集群将VIP及OGG进程迁移至健康节点,并重启进程(依赖NFS共享文件保证数据连续性)。
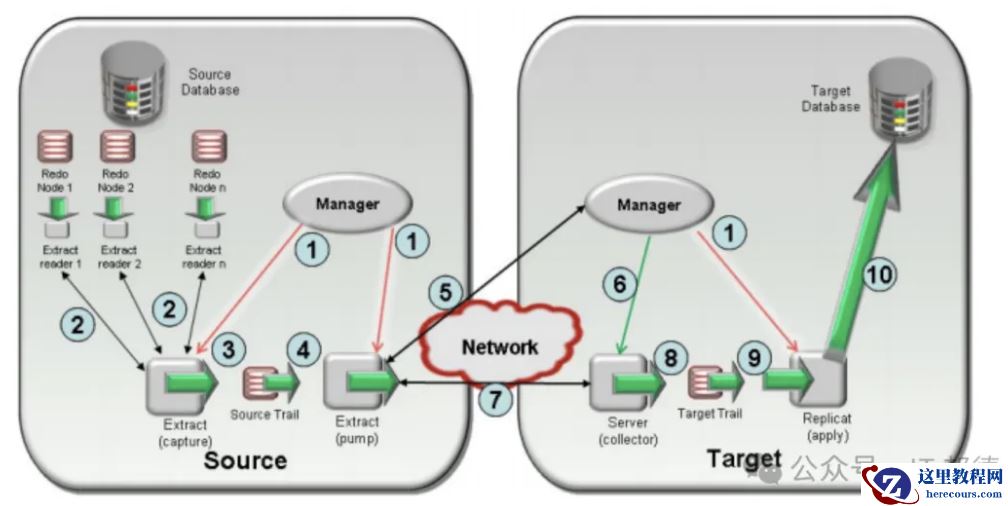
3.ACFS+XAG高可用切换
3.1 计划内切换
此步骤的主要目的是计划内(如某台节点做维护情况下),将该OGG进程从某个节点切换到另外一个节点。
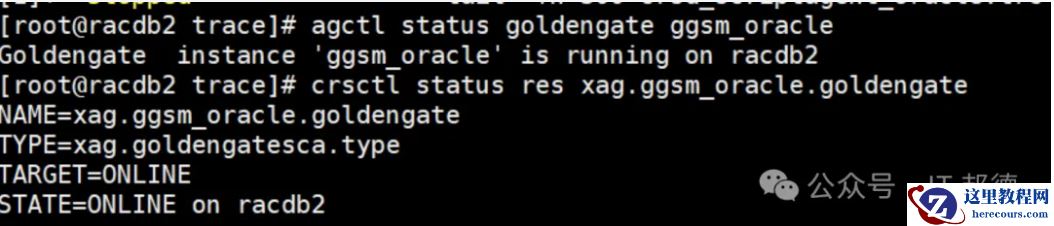
1.检查 gg_oracle 当前运行节点 crsctl status res xag.ggsm_oracle.goldengate NAME=xag.ggsm_oracle.goldengate TYPE=xag.goldengatesca.type TARGET=ONLINE STATE=ONLINE on racdb ip addr|grep 6.20 inet 192.168.6.20/24 brd 192.168.6.255 scope global secondary ens33:2 通过命令执行切换,通过crsctl或者agctl命令都可以 --启动ggsm_oracle到节点2 agctl relocate goldengate ggsm_oracle --node racdb2
3.2 进程异常切换
由于OGG资源ggsm_oracle依赖于OGG软件和VIP地址,基于OGG和进程的运行,尽量模拟OGG进程或者VIP地址异 常情况下,Clusterware会怎么来管理OGG资源。
1.Kill OGG进程 此种情况下由于机器还存在而且VIP还是在该节点上, 所以CRS检查到进程异常后, 会去重启OGG管理进程及ER进程。 -进行kill所有OGG SM进程 kill -9 13422 2.查看ogg进程 - 被重启 启动之后查看日志 cd /u01/app/grid/diag/crs/racdb2/crs/trace tail -fn 300 crsd_scriptagent_oracle.trc 观察CRS中 gg_oracle 资源状态 crsctl status res -t
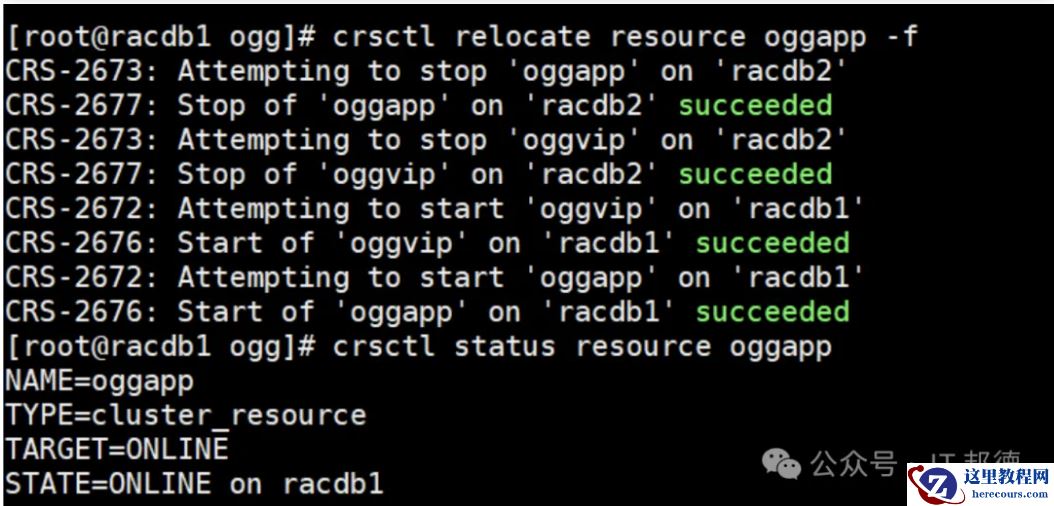
4.NFS+HA脚本高可用切换
在另外一个节点尝试重新切换
[root@racdb1 ogg]# crsctl relocate resource oggapp -f
总结
“高可用不是技术,而是生存法则”。当OGG同步链路具备RAC的弹性、DG的冗余、ACFS的坚挺,DBA才真正从“救火队员”蜕变为“架构指挥官”








")