核心结论
Oracle 12.1.0.2 及以上版本中,若 ASM 磁盘组为 Normal 冗余模式,移除磁盘时需确保操作后仍有至少 3 块磁盘存活,否则可能触发报错并导致异常。
背景与操作过程
本次操作环境为 Oracle 19.12 版本 RAC 数据库, +DATA 磁盘组采用 Normal 冗余模式。初始状态下,该磁盘组包含 2 块原有磁盘( `data1` 、 `data2` ),计划通过新增 2 块磁盘( `newdata1` 、 `newdata2` )完成替换。
1. 新增磁盘操作
首先顺利完成新磁盘添加,执行命令如下:
sql
alter diskgroup data add disk '/dev/mapper/newdata1';
alter diskgroup data add disk '/dev/mapper/newdata2';
磁盘添加后, ASM 自动触发 rebalance (重平衡),过程无异常。
2. 移除原有磁盘操作
- 第一步移除 `data2` 时,磁盘组总磁盘数为 4 块,移除后剩余 3 块,符合 “Normal 模式下至少 3 块存活 ” 的要求,操作成功。
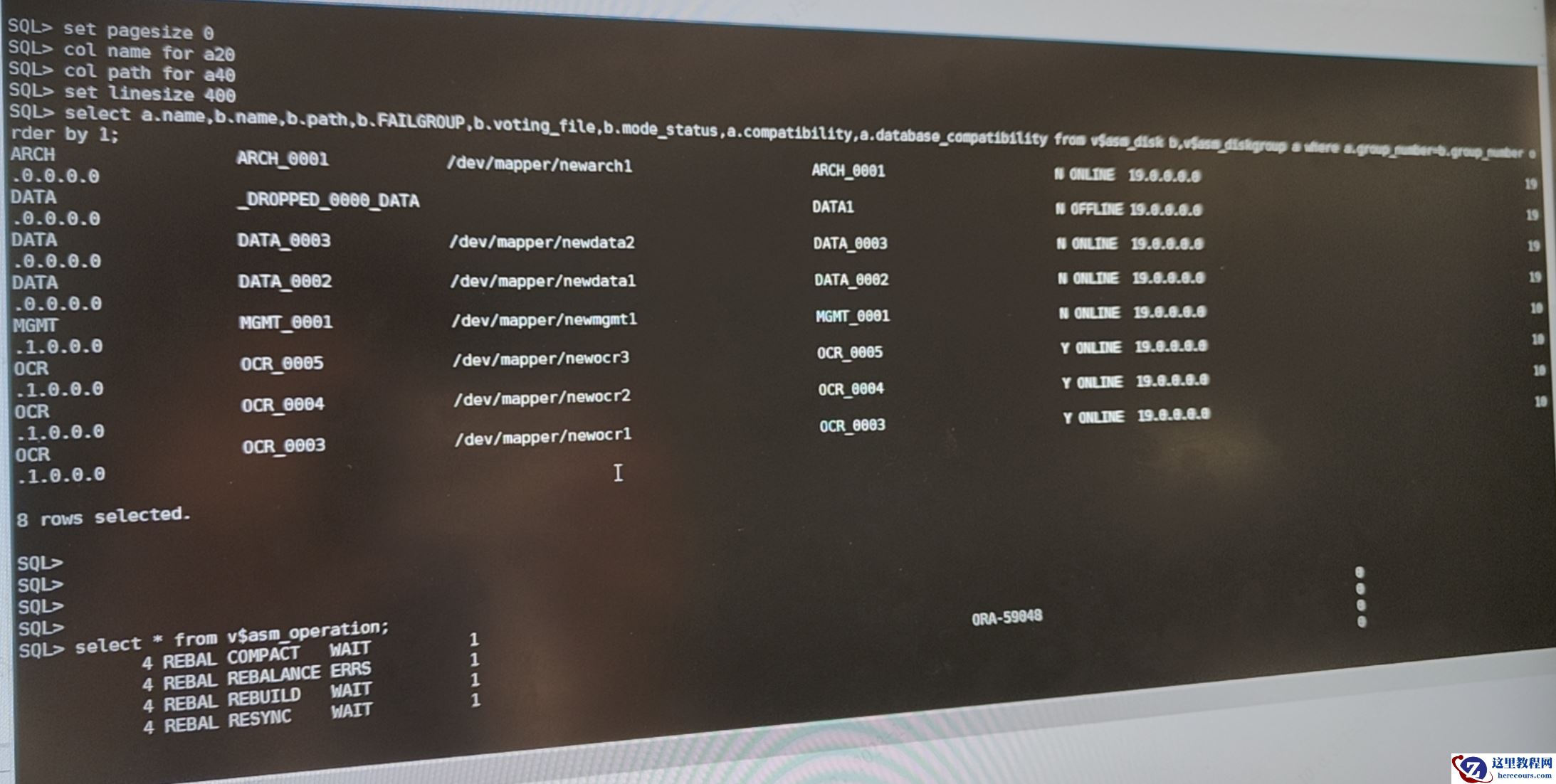
- 第二步移除 `data1` 时,因剩余磁盘数将降至 2 块(不足 3 块),执行失败并触发报错 `ORA-59048` 。
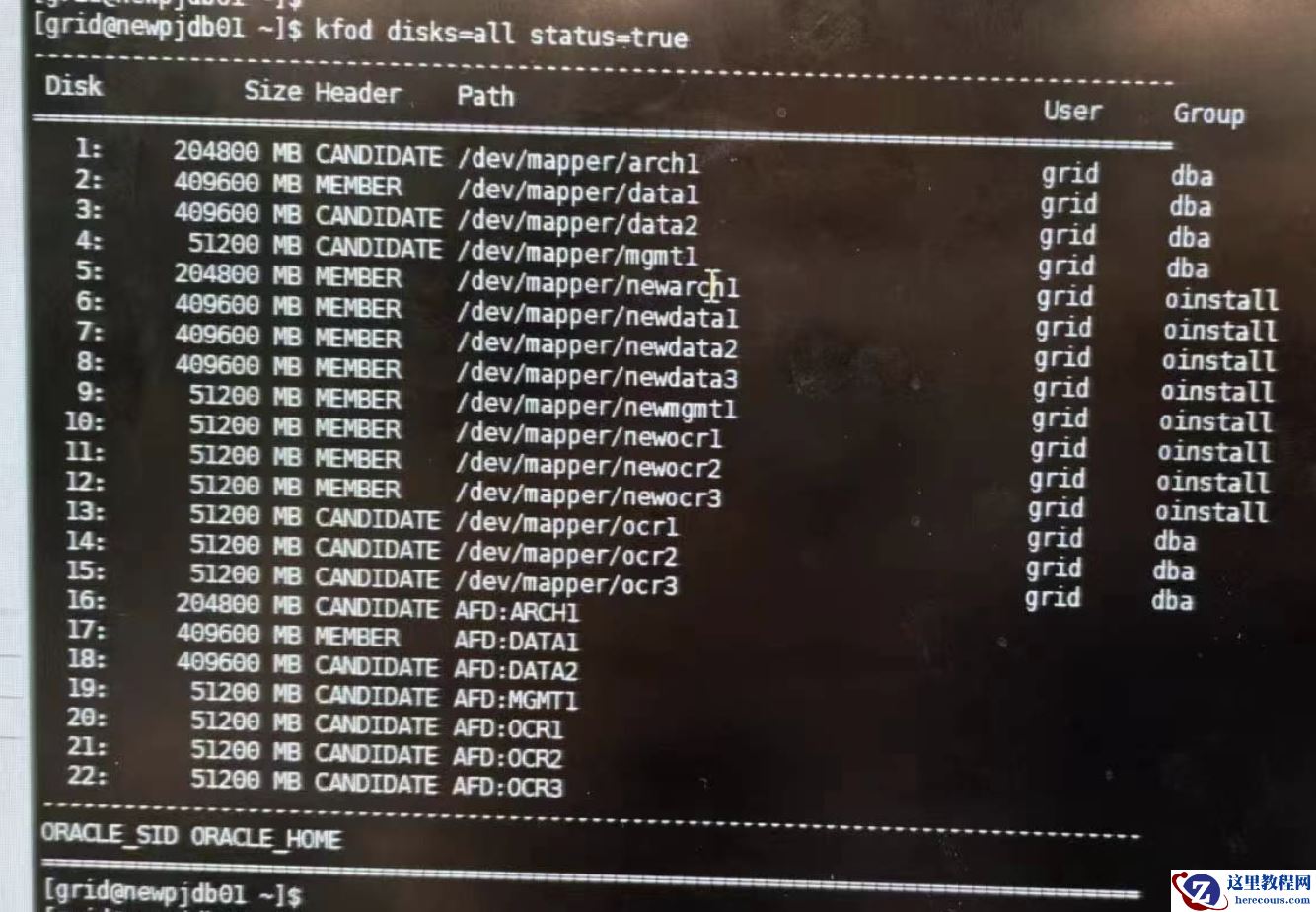
此时检查发现: `data1` 仍在磁盘组中,但状态变为 `offline` ,且磁盘路径丢失; `v$asm_disk` 视图中其挂载状态显示为 `MISSING` ,文件头状态为 `UNKNOWN` ;通过 `kfod` 命令检查,磁盘头标记仍为 `member` (成员),同时 `data1` 的 `total_mb` 与 `free_mb` 数值不匹配,状态异常。
![]()
2. 临时恢复操作
为满足磁盘数量要求,向客户申请新增 1 块 400G 磁盘( `newdata3` )并加入磁盘组:
sql
alter diskgroup data add disk '/dev/mapper/newdata3';
新增后 ASM 重平衡正常完成, `v$asm_operation` 中报错消失,磁盘组核心功能恢复,但 `kfod` 检查显示 `data1` 的磁盘头仍为 `member` 状态,需进一步处理。
彻底解决与验证
考虑到生产环境业务连续性,先将业务切换至容灾库,再执行以下修复操作:
1. 尝试常规修复(未成功)
- 执行磁盘组校验: `alter diskgroup data check all;`
- 卸载磁盘组后修复磁盘头: `alter diskgroup DATA dismount;` 并通过 `kfed repair /dev/mapper/data1` 操作
- 重启集群: `crsctl stop cluster -n all;` 与 `crsctl start cluster -n all;`
以上操作均未修正 `data1` 的磁盘头状态。
2. 最终解决方案
卸载 +DATA 磁盘组后,将 `/dev/mapper/data1` 的权限修改为 `root` 独占(确保 ASM 无法访问),随后重启集群。操作后:
- +DATA 磁盘组正常挂载, `v$asm_disk` 等视图无异常提示
- `data1` 因权限限制无法被 ASM 识别,彻底排除对磁盘组的影响
3. 根因分析
`kfod` 工具依赖磁盘头信息判断状态,本次故障中 `data1` 因移除失败未自动更新磁盘头标记(仍为 `member` ),而修改权限可从物理层面阻断其与 ASM 的交互,避免状态干扰。
经验总结
1. 操作前提: Normal 模式磁盘组移除磁盘前,需先确认 “ 剩余磁盘数 ≥3” ,可通过新增磁盘补足数量后再执行移除。
2. 异常处理:若出现磁盘头信息异常,常规修复无效时,可通过限制磁盘访问权限(如修改属主、权限)彻底隔离无效磁盘。
3. 风险规避:生产环境操作前需备份关键信息,复杂操作建议切换至容灾库后执行,降低业务影响。












