持久内存-RDMA让远程数据不再远
第一届「中国云计算基础架构开发者大会」(以下简称 CID )将在 2020 年 10 月 25 日举办 。会中看到有新硬件PM 结合 RDMA 的议题,这是数据库方面前沿技术,对下一代数据库发展有重要影响。听后进行总结。
正文
 包括以下几个议题:PRMEM
是什么、技术细节、性能、使用场景及开发的库。
包括以下几个议题:PRMEM
是什么、技术细节、性能、使用场景及开发的库。
1、什么是PMEM
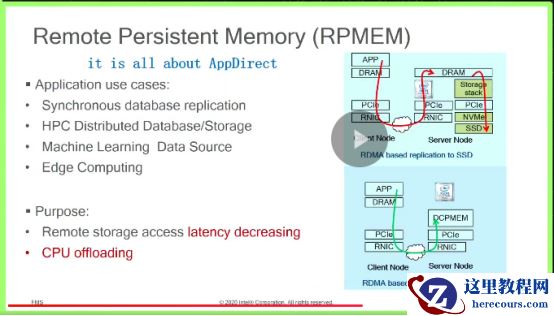 SSD
已经结合了
RDMA
技术,需要客户端将数据从
DRAM
通过
PCIe
拷贝到网卡,传输到服务端网卡再拷贝到
DRAM
,最后通过
PCIe
持久化到
SSD
。具有额外的数据
copy
。结合
PM
新硬件,可以消除这部分的影响。
数据从客户端到网卡后,通过RDMA
网络直接到对端的网卡,然后直接到
PM
。消除了经过
DRAM
的拷贝流程以及
CPU
的参与,解放出来服务端的
CPU
,进行其他操作。
SSD
已经结合了
RDMA
技术,需要客户端将数据从
DRAM
通过
PCIe
拷贝到网卡,传输到服务端网卡再拷贝到
DRAM
,最后通过
PCIe
持久化到
SSD
。具有额外的数据
copy
。结合
PM
新硬件,可以消除这部分的影响。
数据从客户端到网卡后,通过RDMA
网络直接到对端的网卡,然后直接到
PM
。消除了经过
DRAM
的拷贝流程以及
CPU
的参与,解放出来服务端的
CPU
,进行其他操作。
2、技术细节
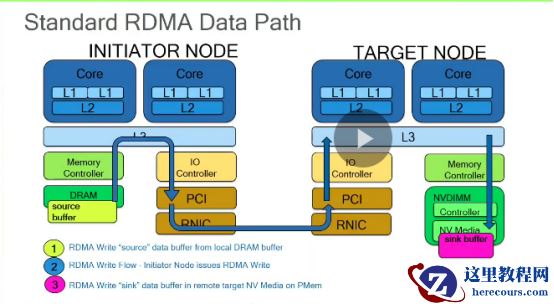 标准的RDMA
数据流路径为:数据经过
L3 cache->RNIC
在通过
RDMA
网络
->
远端的
RNIC->L3 cache->
持久设备。
问题:数据的可视化和持久化
标准的RDMA
数据流路径为:数据经过
L3 cache->RNIC
在通过
RDMA
网络
->
远端的
RNIC->L3 cache->
持久设备。
问题:数据的可视化和持久化
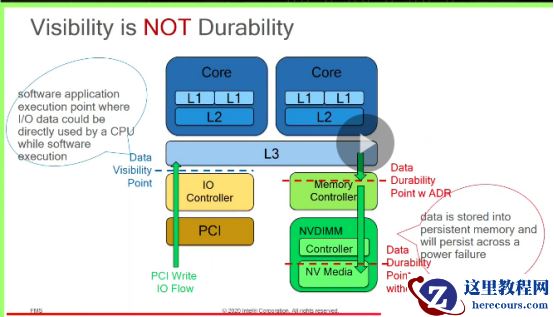 数据对CPU
可视,不是对人。数据到达
L3 cache
及以上才能对
CPU
可视,但是并不是持久化到远端,宕机会丢失数据。
ADR
是
Intel
的异步自刷新技术,使用这个技术的话,当数据达到
memory controller
这个点后就已经持久化到
PM
,否则需要到达
NVM
的
controller
刷写到
PM
点才算持久化。
数据对CPU
可视,不是对人。数据到达
L3 cache
及以上才能对
CPU
可视,但是并不是持久化到远端,宕机会丢失数据。
ADR
是
Intel
的异步自刷新技术,使用这个技术的话,当数据达到
memory controller
这个点后就已经持久化到
PM
,否则需要到达
NVM
的
controller
刷写到
PM
点才算持久化。
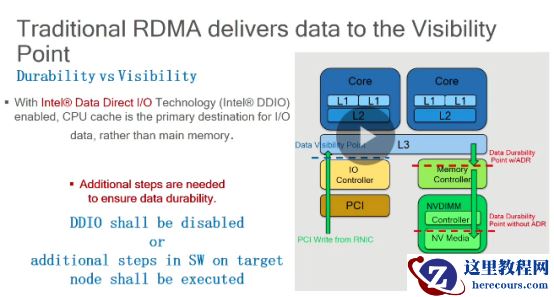 数据到远端的RDMA
网卡后,并不能确定数据是在
RNIC
网卡
buffer
还是
PCIEbuffer
还是已经到持久化设备里面。需要额外的步骤来保证数据持久化。
Intel
的
DDIO
技术,提高整体吞吐率,降低延迟,减小能源消耗,让服务器更快处理网络接口数据,只能保证数据对
CPU
可见。
DDIO
下数据放到
L3 cache
里,避免经过内存的拷贝,减小延迟。有两个方案保证持久性。
数据到远端的RDMA
网卡后,并不能确定数据是在
RNIC
网卡
buffer
还是
PCIEbuffer
还是已经到持久化设备里面。需要额外的步骤来保证数据持久化。
Intel
的
DDIO
技术,提高整体吞吐率,降低延迟,减小能源消耗,让服务器更快处理网络接口数据,只能保证数据对
CPU
可见。
DDIO
下数据放到
L3 cache
里,避免经过内存的拷贝,减小延迟。有两个方案保证持久性。
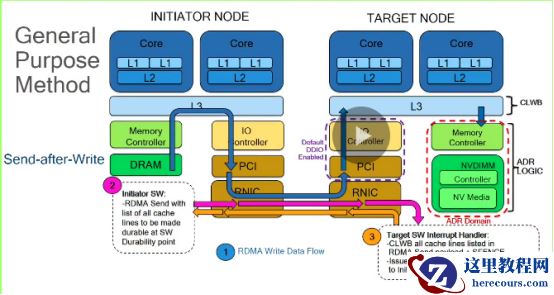 DDIO
打开:主要是远端执行
CLWB
指令刷完
cache lines
后调用
sfence
指令,确保数据全部到持久化内存。
DDIO
打开:主要是远端执行
CLWB
指令刷完
cache lines
后调用
sfence
指令,确保数据全部到持久化内存。
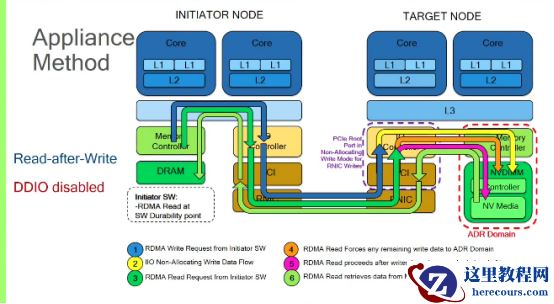 DDIO
关闭时:数据不经过远端的
L3 cache
,需要加个
read
指令,来确保数据都到持久内存。
DDIO
关闭时:数据不经过远端的
L3 cache
,需要加个
read
指令,来确保数据都到持久内存。
3、性能
 RDMA
已经比
TCP/IP
快了近
30%
,
rpmem
以
6.8
微秒,延迟大大降低
RDMA
已经比
TCP/IP
快了近
30%
,
rpmem
以
6.8
微秒,延迟大大降低
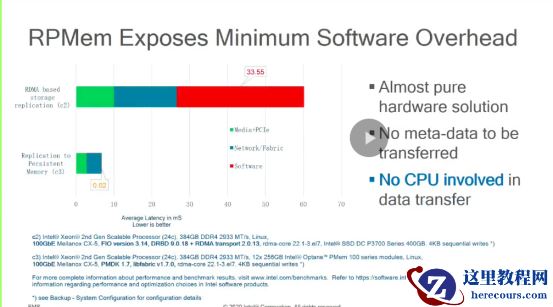 红色表示CPU
参与,该技术没有
CPU
参与。网络和硬盘的延迟都大大降低。
红色表示CPU
参与,该技术没有
CPU
参与。网络和硬盘的延迟都大大降低。
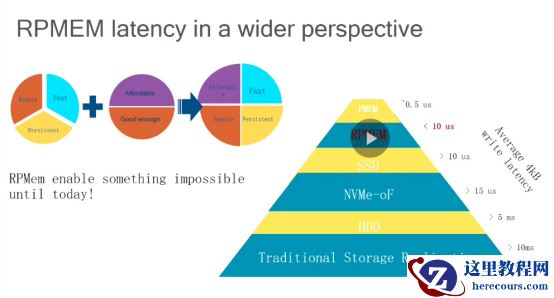 Rpmem
的延迟在平均
4kb
的写进行复制场景下,延迟小于
10us
。
Rpmem
的延迟在平均
4kb
的写进行复制场景下,延迟小于
10us
。
4、案例
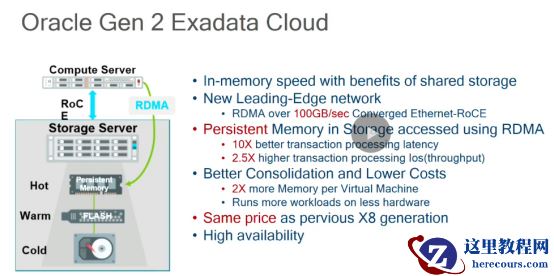 计算节点和存储节点分离,与之前的X8
代相比,该一体机使用
RDMA
访问
PM
能够获得快
10
倍的事务处理延迟及
2.5
倍的事务
IOS
。
计算节点和存储节点分离,与之前的X8
代相比,该一体机使用
RDMA
访问
PM
能够获得快
10
倍的事务处理延迟及
2.5
倍的事务
IOS
。
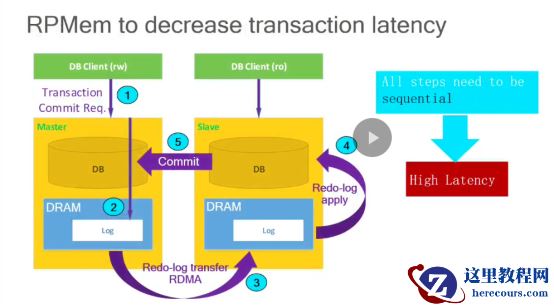 OLTP
数据库复制场景下的高延迟问题。
OLTP
数据库复制场景下的高延迟问题。
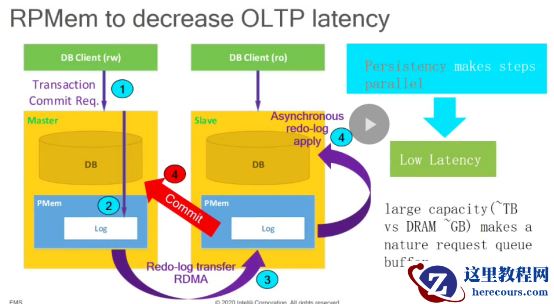 因为PM
是持久的,所以相比
DRAM
来说可以直接反馈
master
可以提交,然后
slave
异步进行回放。
因为PM
是持久的,所以相比
DRAM
来说可以直接反馈
master
可以提交,然后
slave
异步进行回放。
 AI
方面。
AI
方面。
6、额外步骤保证数据到持久内存
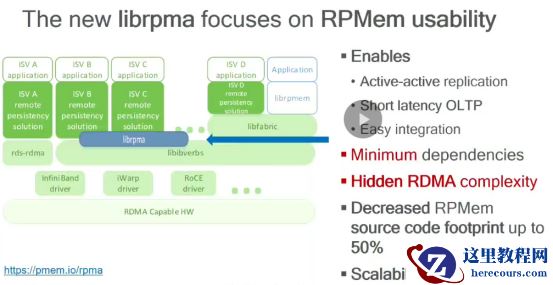 Intel
开发的
librma
可方便进行编程。相比
librpmem
,软件层次更少,简化软件系统复杂度,更注重
API
的应用程度,方便工程师使用更少代码实现相同功能。
Intel
开发的
librma
可方便进行编程。相比
librpmem
,软件层次更少,简化软件系统复杂度,更注重
API
的应用程度,方便工程师使用更少代码实现相同功能。
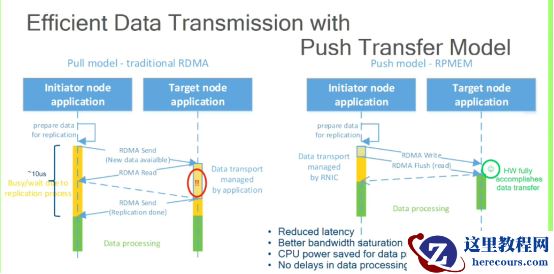 Librma
使用
push transfer
模型,大大减小
RDMA
复制的操作,
RDMA flush
后,由硬件完成数据持久化到
PM
。同时不需要
CPU
参与,降低了延迟。
Librma
从
github
上下载。持久化内存编程的书籍《
programming persistent memory
》年底完成中文版翻译,期待完成后开源。
Librma
使用
push transfer
模型,大大减小
RDMA
复制的操作,
RDMA flush
后,由硬件完成数据持久化到
PM
。同时不需要
CPU
参与,降低了延迟。
Librma
从
github
上下载。持久化内存编程的书籍《
programming persistent memory
》年底完成中文版翻译,期待完成后开源。












