向量化执行使表达式性能提升10倍成为可能
查询执行引擎对数据库系统性能非常重要。 TIDB 是一个开源兼容 MySQL 的 HTAP 数据库,部署广泛使用的火山模型来执行查询。不幸的是, 当查询一个大库时,向量化模型会造成较高的解释开销以及较低的 CPU CACHE 命中率 。 受 MonetDB/X100: Hyper-Pipelining Query Execution 论文启发,在 TIDB 中部署向量化执行引擎以提高查询性能。(建议学习 Andy Pavlo 的 Query Execution 课程,其中详细介绍了有关执行模型和表达式计算的原理)。 2017 年年末,我们对 TIDB 的 SQL 执行引擎完成了 3 项优化:
1) 在执行引擎中完成列式存储。类似 Apache 的 Arrow 。参考 pull request (PR) #4856 : https://github.com/pingcap/tidb/pull/4856 。
2) 将一次一个 tuple 的迭代模式(火山模型)改成一次一批( 1024 个 tuple ),参考: https://github.com/pingcap/tidb/pull/5178
3) 基于向量化执行原则,优化各种查询操作符: https://github.com/pingcap/tidb/pull/5184 得益于这些优化,与 TIDB1.0 相比, TIDB2.0 显著提升了查询分析的性能。可以查看 TPC-H 性能: https://github.com/pingcap/docs/blob/release-2.1/benchmark/v2.1-performance-benchmarking-with-tpch.md 最近我们 release 了 TiDB2.1 和 3.0 ,向量化执行引擎更加稳定。现在正在开发 TiDB4.0 ,包括向量化表达式。 本文,深入分析了为什么使用向量化引擎,如何实现它以及如何与社区贡献者合作完成多于 360 个函数的向量化,还有对未来的看法。
为什么使用向量化
之前 TiDB 实现了火山模型的执行引擎。这个迭代模型使用标准数据访问接口。在各个算子之间执行 open()-next()-close() ,一行一行处理数据。火山模型简单且可扩展。 但是, 当执行大型查询时,火山模型会带来较高的解析代价。另外,也不能重复你利用现代 CPU 硬件的特性,如 CPU CACHE 、分支预测、指令流水线 。 向量化执行使用单指令在内存中执行一组连续的相似的数据项。与火山模型相比, 向量化模型大大降低了解释开销 。因此我们选择了向量化执行引擎。 本节中,使用表达式 colA*0.8 + colB 来展示基于行的执行和基于向量化执行之间的开销差距。 TIDB 根据算术运算符和运算符优先级,将此表达式解析为表达式求值树。在这个树中,每个非叶子节点代表一个算术运算符,叶节点代表数据源。每个非叶节点要么是一个常量如 0.8 ,要么是表中的一个字段如 colA 。节点之间的父子关系表示计算上的依赖关系:子节点的结算结果是父节点的输入数据。
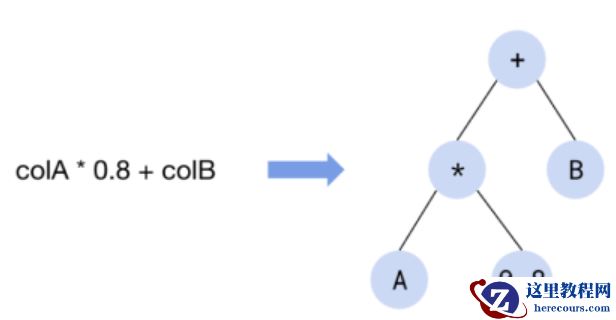
表达式求值树 每个节点的计算逻辑可以抽象成下面接口: type Node interface { evalReal(row Row) (val float64, isNull bool) } 以 * , 0.8 , col 节点为例, 3 个节点都实现了上面的接口,伪代码如下: func (node *multiplyRealNode) evalReal(row Row) (float64, bool) { v1, null1 := node.leftChild.evalReal(row) v2, null2 := node.rightChild.evalReal(row) return v1 * v2, null1 || null2 } func (node *constantNode) evalReal(row Row) (float64, bool) { return node.someConstantValue, node.isNull // 0.8 in this case } func (node *columnNode) evalReal(row Row) (float64, bool) { return row.GetReal(node.colIdx) }
基于行执行的解释开销
和火山模型类似,上面讨论的表达式实现是对行进行迭代。
逐行迭代的解释开销是多少?下面我们来看一个函数在
TiDB
中的实现。
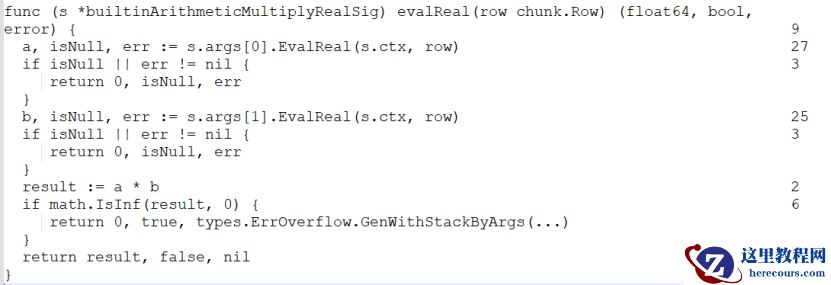
builtinArithmeticMultiplyRealSig
函数实现
2
个浮点数相乘。下面的代码块描述了这个函数的实现。右边的数组表示对应行的汇编指令数,是代码汇编后得到的。要注意,此块仅包含在正常条件下迭代的行,并忽略错误处理的逻辑:
 下面列出了
builtinArithmeticMultiplyRealSig
每个功能任务及执行它的汇编指令数量。
下面列出了
builtinArithmeticMultiplyRealSig
每个功能任务及执行它的汇编指令数量。
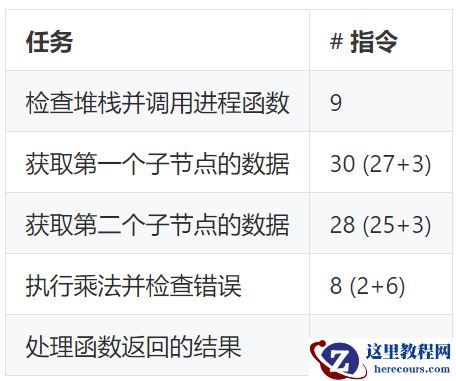 每次这个函数执行乘法时,
82
条指令中仅有
8
条在执行“真正的”乘法,这仅占总指令的
10%
左右,其他
90%
被视为解释开销。一旦将这个函数向量化,它的性能提高了仅
9
倍。参见:
https://github.com/pingcap/tidb/pull/12543
每次这个函数执行乘法时,
82
条指令中仅有
8
条在执行“真正的”乘法,这仅占总指令的
10%
左右,其他
90%
被视为解释开销。一旦将这个函数向量化,它的性能提高了仅
9
倍。参见:
https://github.com/pingcap/tidb/pull/12543
向量化减少解释开销
和 SQL 算子的向量化优化一样,我们可以一次处理并返回一批数据。这减少了表达式计算过程中的解释开销。 假设一批数据有 1024 行,优化后每次调用一个函数处理这 1024 行数据,然后返回。函数调用的解释开销变成原来的 1/1024. 因此,我们可以添加以下接口来向量化表达式计算: type Node interface { batchEvalReal(rows []Row) (vals []float64, isNull []bool) }
我们的向量化处理接口长什么样?为什么?
真正的源代码和上面显示的模型并不完全一样。它看起来像这样: type VecNode interface { vecEvalReal(input *Chunk, result *Column) } 想知道为什么? 为了说明原因,先介绍下 TiDB 的 chunk 结构。也就是查询执行阶段数据在内存中的表示。 2017 年底,在进行向量化优化,引入了 chunk 概念。一个 chunk 由多列组成。列由两种类型:
1) 固定长度的列,数据时固定长度,不能改变
2) 变长列,数据长度可变
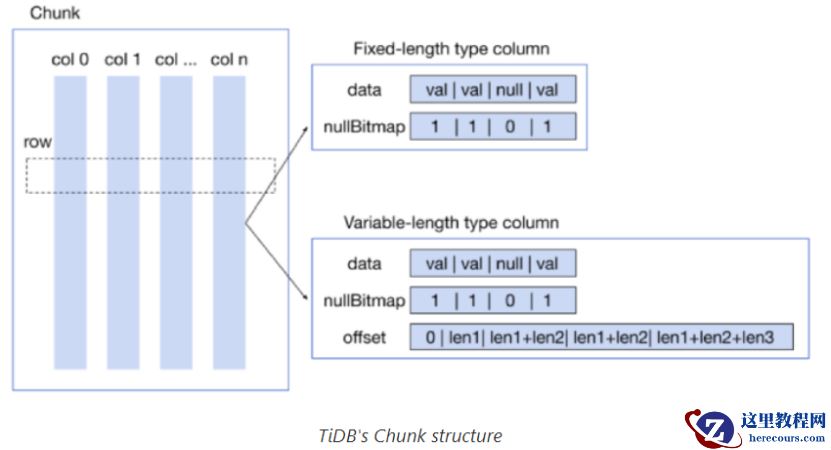 不管数据长度是固定的还是变长的,列中数据在
Column.data
字段(即数组)中是连续存储在内存中的。如果数据长度变化,
column.offset
记录数据偏移量。如果数据是固定长度,则不需要记录偏移量。
下图说明了我们最近为
chunk
引入的新向量访问接口:
不管数据长度是固定的还是变长的,列中数据在
Column.data
字段(即数组)中是连续存储在内存中的。如果数据长度变化,
column.offset
记录数据偏移量。如果数据是固定长度,则不需要记录偏移量。
下图说明了我们最近为
chunk
引入的新向量访问接口:
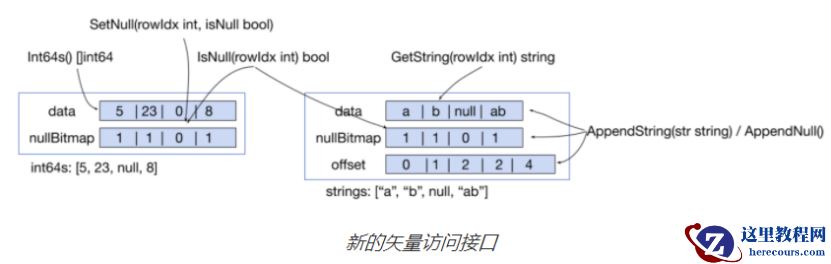
1) 对于定长数据,如 int64 , Golang 的 unsafe 包直接转换 column.data 为 []int64 ( []int64 中的 Int64s() ),返回结果。读取或更改 column.data 的用户可以直接操作这个数组。这是访问固定长度数据的最有效方式。
2) 对于变长数据,例如字符串,可以使用 GetString(rowIdx int) string 来获取对应行的数据,仅能以追加的方式更新。随机更改变长数据列中一个元素,需要移动后续所有数据。这会带来巨大开销。为了提升性能,此操作未在 column 中。 再返回来看下接口设计。 基于 chunk 的实现以及 Golang 的特性,我们优化了表达式计算以下几个方面:
1) 直接通过 *chunk 而不是 []Row ,避免创建大量 Row 对象。降低了 Golang 垃圾回收的压力并提高了性能
2) column.data 通过 column 而不是 Row ,减少函数调用次数。帮助减少解释开销和加速访问数据。
3) 将用于存储数据的列放到参数中并传递,而不是直接返回 []float64 和 []bool 数组。提高了内存利用率,减少了 Golang GC 开销。 基于这些优化,我们的向量化表达式计算接口变成了今天这个样子。
怎么实现向量化执行引擎?
本节介绍如何实现向量化。
以
multiplyRealNode
为例:
 对于这个功能:
对于这个功能:
1) 前 2 行: cache pool 中的 ColumnBuffer 用于缓冲右孩子(第二个参数)的数据。左孩子的数据存储再 result 指针指向的内存中。
2) Columns.MergeNulls(cols...) 合并多列的 NULL 标签。这个方法类似 result.nulls[i] = result.nulls[i] || buf.nulls[i] 。 Column 内部使用一个 bitmap 来维护 NULL 标签。当调用这个函数时,一个列来做一个按位操作来核并 NULLs 。
3) 一个循环直接将左右字节的的数据相乘。
4) 再乘法过程中中,该函数调用左右子接口来获取他们的数据。 这种实现方式通过向量化减少了解释开销,对现代 CPU 更有利:
1) 顺序访问一个向量数据,减少了 CPU CACHE 的 miss
2) 大多数计算工作在一个简单循环中,有助于 CPU 分支预测与指令流水线。
向量化执行和基于行的执行引擎性能比较
本节使用
TiDB
源码进行基准测试,并比较向量化前后的性能。使用相同数据(
2
列浮点数组成的
1024
行)分别
col0*0.8 + col1
计算:
 上面的结果表明向量化执行比基于行的执行引擎快
4
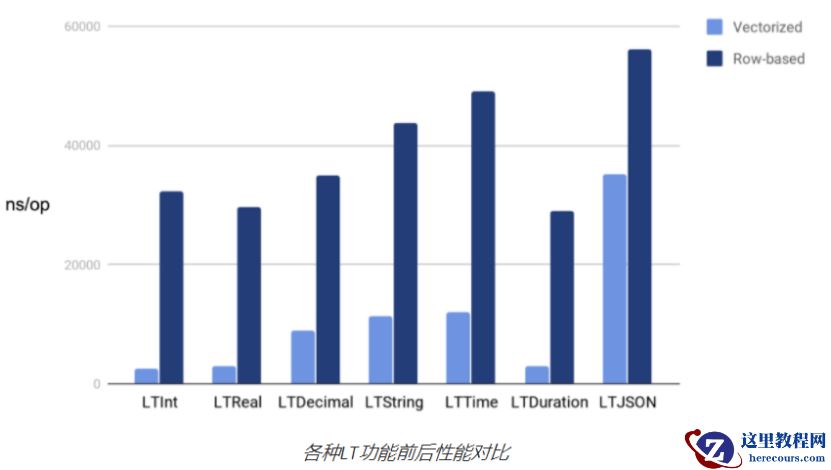
倍。下图对比了
LT
向量化前后各种小于(
LT
)函数的性能。横轴表示
LT
用于测试的函数,纵轴表示完成操作持续的时间(单位纳秒)
上面的结果表明向量化执行比基于行的执行引擎快
4
倍。下图对比了
LT
向量化前后各种小于(
LT
)函数的性能。横轴表示
LT
用于测试的函数,纵轴表示完成操作持续的时间(单位纳秒)
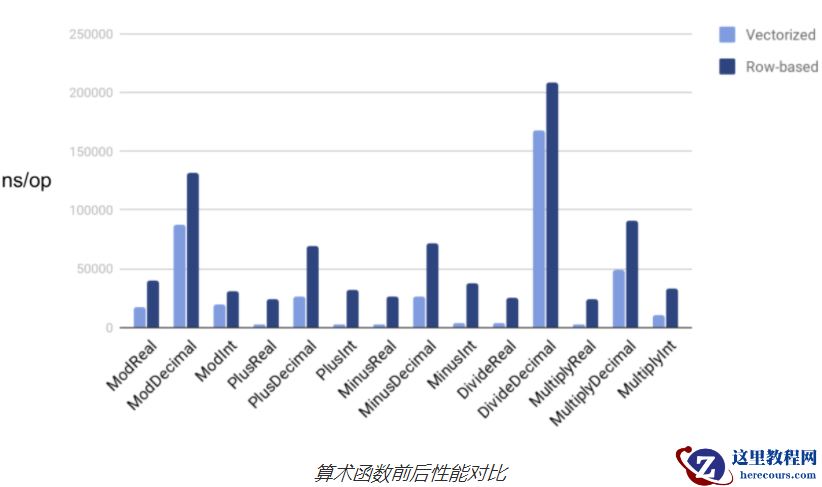
 下面比较了向量化前后算术函数的性能:
下面比较了向量化前后算术函数的性能:
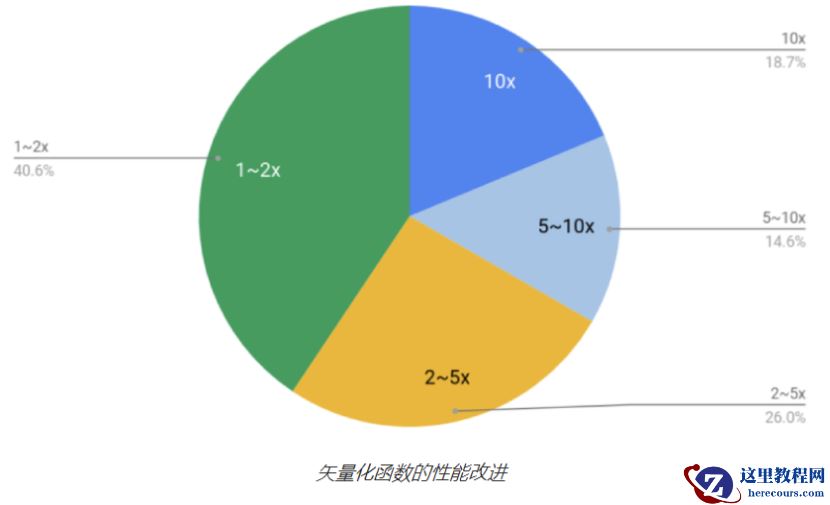
 我们测试了
300
多个向量化函数后,发现这些函数中有超过
50%
的函数性能提高了
1
倍以上,
18.7%
的函数实现了
10
的性能提升。
我们测试了
300
多个向量化函数后,发现这些函数中有超过
50%
的函数性能提高了
1
倍以上,
18.7%
的函数实现了
10
的性能提升。
如何将360+个内置函数向量化?
迈向 4.0 的过程中,表达式向量化是一个巨大的工程。因为涉及 500 多个内置函数。开发人员相当少 - 完成相当困难。位更有效开发代码,使用 Golang 将尽可能多的内置函数向量化 test/template 。此模板生成向量化函数的源码。位让更多人参与这个项目,我们在开发者社区中成立了向量化表达式工作组。通过这种方法,社区贡献者承担了向量化过程中大部分工作。 在我们的努力下,重构了仅三分之二的内置函数,大部分都有显著的性能提升。有些甚至能有一两个数量级的性能提升。
使用一个模板进行向量化
当我们对内置函数进行向量化时,我们发现很多函数都有相似之处。例如,大多数
LT( <)
、
GT( >)
和
LE( <=)
函数具有相似的逻辑。它们仅使用的运算符不同。因此,可以使用模板来生成这些函数的代码。目前,
Golang
不支持泛型类型和宏定义,所以我们使用
text/template
包来生成代码。基于
Golang
模板的语法,我们将要生成的函数抽象成模板。例如,这里是比较函数的模板,如
LTand GT
:
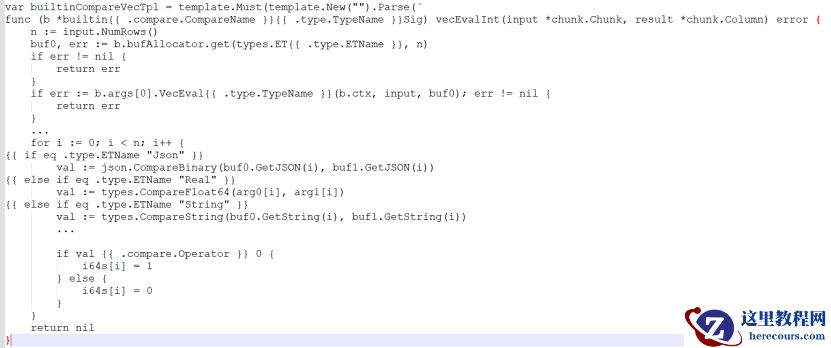 针对不同类型数据和算子,模板生成相应代码。这个模板在
expression/generator
包里。
针对不同类型数据和算子,模板生成相应代码。这个模板在
expression/generator
包里。
社区帮助完成向量化
除了使用模板向量化内置函数外,还在社区开始了向量化活动,让更多人参与进来。编写了一个脚本,为所有内置函数生成向量化接口:
func (b *builtinCastStringAsIntSig) vecEvalInt(input *chunk.Chunk, result *chunk.Column) error {
return errors.Errorf("not implemented")
}
func (b *builtinCastStringAsDurationSig) vectorized() bool {
return false
}
保留函数接口可以避免合并代码时不同
pull request
同时修改同一个文档引起的冲突。我们还编写了一个测试框架。贡献者将函数向量化后,他们可以使用框架来测试内置函数的正确性和性能,只需编写几行简单的配置即可。
如下代码所示,贡献者只需要在
vecBuiltinArithemeticCases
 接下来,它们可以按照我们编写的两个函数运行。然后,他们可以执行正确性和性能测试。
接下来,它们可以按照我们编写的两个函数运行。然后,他们可以执行正确性和性能测试。
 正确性和性能测试都直接生成随机数据,并比较向量化执行和基于行执行的性能。上述两个操作可以帮助贡献者轻松
向量
化我们的内置函数。在社区的帮助下,我们在短短两个月内对
360
多个函数进行了
向量
化处理。在此期间,我们的社区贡献者提交了
256
份
PR
。该活动还产生了九名活跃贡献者(他们在一年内合并了至少
8
个
PR
)和两个审阅者(他们在一年内合并了至少
30
个
PR
)。
正确性和性能测试都直接生成随机数据,并比较向量化执行和基于行执行的性能。上述两个操作可以帮助贡献者轻松
向量
化我们的内置函数。在社区的帮助下,我们在短短两个月内对
360
多个函数进行了
向量
化处理。在此期间,我们的社区贡献者提交了
256
份
PR
。该活动还产生了九名活跃贡献者(他们在一年内合并了至少
8
个
PR
)和两个审阅者(他们在一年内合并了至少
30
个
PR
)。
下一步做什么
通过引入向量化执行,我们显着提高了表达式执行的性能。目前,默认情况下,我们的主分支上启用了向量化执行。一旦表达式的所有内置函数都支持向量化执行,该表达式将使用向量化执行。未来我们也会使用向量化执行来提升 TiDB 的 HTAP 能力。 请注意,上面的所有性能测试数据都在内存中。如果数据存储在磁盘上,读取它可能会导致高开销。在这种情况下,向量化执行的好处可能不太明显。但总的来说,向量化执行明显提升了 TiDB 表达式评估的性能。 此外,当我们对表达式进行向量化时,我们发现向量化执行可以应用于许多其他情况以提高性能。例如: 在哈希连接中,我们为内部数据(参见 PR #12076 )和外部数据(参见 PR #12669 )向量计算哈希键。在某些场景下,性能分别提升 7% 和 18% 。我们要感谢一位名叫 sduzh 的社区贡献者,他独自完成了这些改进。 在哈希聚合中,我们对数据进行了向量化编码。在本地测试中,性能比以前快了 20% 到 60% 。有关详细信息,请参阅 PR #12729 。 在 StreamAggregation 运算符中,我们将数据向量划分为组。在本地测试中,性能提升了约 60% 。有关详细信息,请参阅 PR #12903 。
原文
https://en.pingcap.com/blog/10x-performance-improvement-for-expression-evaluation-made-possible-by-vectorized-execution












