来源:PostgreSQL学徒
前言
前些天,一位做元数据信息采集的同事问我
“information_schema.columns 中的 character_octet_length 和 character_maximum_length 是什么意思?
这个问题看似很小,却可以引申出很多类似的问题,比如 length、octet_length 的差异,pg_column_size 是如何计算的,pg_relation_size 和 pg_table_size 的差异等等,让我们逐一分析一下。
剖析
为了演示,先插入一点表情符号、中文和普通字符
postgres=# create table t1(col1 varchar(2),col2 varchar(3),col3 char(4));
CREATE TABLE
postgres=# insert into t1 values('ab','abc','abcd');
INSERT 0 1
postgres=# insert into t1 values('ab','ef','abc');
INSERT 0 1
postgres=# insert into t1 values('ab','abc','你好不好');
INSERT 0 1
postgres=# insert into t1 values('ab','abc','????????????????');
INSERT 0 1
postgres=# select * from t1;
col1 | col2 | col3
------+------+----------
ab | abc | abcd
ab | ef | abc
ab | abc | 你好不好
ab | abc | ????????????????
(4 rows)
postgres=# select character_maximum_length,character_octet_length from information_schema.columns where table_name = 't1';
character_maximum_length | character_octet_length
--------------------------+------------------------
2 | 8
3 | 12
4 | 16
(3 rows)
数据库编码延用默认的 UTF-8。官网有对于这两个字段的介绍:
十分明了,一个是定义时声明的最大字符长度,另一个是可能的最大字节长度,一个字符一个字节。
“维基百科:UTF-8(8-bit Unicode Transformation Format)是一种针对 Unicode 的可变长度字符编码,也是一种前缀码。它可以用一至四个字节对 Unicode 字符集中的所有有效编码点进行编码,属于 Unicode 标准的一部分。
在 UTF-8 中,中文一般占 3 个字节,一些较复杂的文字和繁体字占 4 个字节,大多数的 emoji 表情也占 4 个字节 (联想一下为什么在 MySQL 中需要 utf8mb4 来存储 emoji,因为 MySQL 中的 UTF8 并不是真正的 UTF8,需要当心,否则插入 emoji 会报错的)。但是对于复杂一点的表情,比如 ????????,一个戴着中国帽的中国男人,它需要由????戴着中国帽的男人与????黄种肤色放在一起,两个字符拼凑而成,所以总共需要 8 个字节。而更复杂的,比如 ????????????????,两对父子,需要 17 个字节表示。
验证一下,使用 octet_length 来判断字节的长度:
postgres=# select octet_length('????'); ---4个字节
octet_length
--------------
4
(1 row)
postgres=# select octet_length('????????'); ---8个字节
octet_length
--------------
8
(1 row)
postgres=# select octet_length('????'),length('????'),character_length('????'),char_length('????');
octet_length | length | character_length | char_length
--------------+--------+------------------+-------------
4 | 1 | 1 | 1
(1 row)
所以上面看到 character_octet_length 是 character_maximum_length 的 4 倍。这个问题分析清楚之后,让我们再看一下用于获取列长度的 pg_column_size,这个函数也经常会用到
“Shows the number of bytes used to store any individual data value. If applied directly to a table column value, this reflects any compression that was done.
postgres=# SELECT octet_length(repeat('1234567890',(2^n)::integer)), pg_column_size(repeat('1234567890',(2^n)::integer)) FROM generate_series(0,12) n;
octet_length | pg_column_size
--------------+----------------
10 | 14
20 | 24
40 | 44
80 | 84
160 | 164
320 | 324
640 | 644
1280 | 1284
2560 | 2564
5120 | 5124
10240 | 10244
20480 | 20484
40960 | 40964
(13 rows)
postgres=# SELECT octet_length(repeat('1234567890',(2^n)::integer)), pg_column_size(repeat('1234567890',(2^n)::integer)) FROM generate_series(0,0) n;
octet_length | pg_column_size
--------------+----------------
10 | 14
(1 row)
postgres=# select octet_length('1234567890'),pg_column_size('1234567890');
octet_length | pg_column_size
--------------+----------------
10 | 11
(1 row)
octet_length 的结果没有什么疑问,但为什么 pg_column_size 显式的要多 4 个字节?而自己调用 pg_column_size 返回的又是 11 个字节?却仅多了 1 个字节?好在函数简单,代码里很容易就找到了
/*
* Return the size of a datum, possibly compressed
*
* Works on any data type
*/
Datum
pg_column_size(PG_FUNCTION_ARGS)
{
Datum value = PG_GETARG_DATUM(0);
int32 result;
int typlen;
/* On first call, get the input type's typlen, and save at *fn_extra */
if (fcinfo->flinfo->fn_extra == NULL)
{
/* Lookup the datatype of the supplied argument */
Oid argtypeid = get_fn_expr_argtype(fcinfo->flinfo, 0);
typlen = get_typlen(argtypeid);
if (typlen == 0) /* should not happen */
elog(ERROR, "cache lookup failed for type %u", argtypeid);
fcinfo->flinfo->fn_extra = MemoryContextAlloc(fcinfo->flinfo->fn_mcxt,
sizeof(int));
*((int *) fcinfo->flinfo->fn_extra) = typlen;
}
else
typlen = *((int *) fcinfo->flinfo->fn_extra);
if (typlen == -1)
{
/* varlena type, possibly toasted */
result = toast_datum_size(value);
}
else if (typlen == -2)
{
/* cstring */
result = strlen(DatumGetCString(value)) + 1;
}
else
{
/* ordinary fixed-width type */
result = typlen;
}
PG_RETURN_INT32(result);
}
可以看到,
我们可以通过查询 pg_type.typlen 来确认,如下便是查询变长的数据类型
postgres=# SELECT typname FROM pg_type WHERE typlen = -1 limit 5;
typname
------------
bytea
int2vector
text
oidvector
pg_type
(5 rows)
经过调试,发现 from generate_series 的方式,typlen 是 -1,因此是一个变长数据,流程是 pg_column_size → toast_datum_size → VARSIZE
else
{
/*
* Attribute is stored inline either compressed or not, just calculate
* the size of the datum in either case.
*/
result = VARSIZE(attr);
}
#define VARDATA(PTR) VARDATA_4B(PTR)
#define VARSIZE(PTR) VARSIZE_4B(PTR) ---4字节的header
#define VARSIZE_SHORT(PTR) VARSIZE_1B(PTR)
#define VARDATA_SHORT(PTR) VARDATA_1B(PTR)
/* VARSIZE_4B() should only be used on known-aligned data */
#define VARSIZE_4B(PTR) \
((((varattrib_4b *) (PTR))->va_4byte.va_header >> 2) & 0x3FFFFFFF)
VARSIZE 表示数据行内存储,可能被压缩过。并且可以看到,它含有一个 4 字节的变长头,可以存储不超过 1GB 的数据,之前的文章已经反复讲过,此处就不再赘述。因此这里的 14 字节 = 10 字节 + 4 字节的变长头 ( Varlena header )。
postgres=# select pg_column_size(repeat('1234567890',1));
pg_column_size
----------------
14
(1 row)
postgres=# select pg_column_size('1234567890');
pg_column_size
----------------
11
(1 row)
而第二种方式返回 11 字节,代码走到了 typlen = -2 的逻辑里面,加了 1 字节。
else if (typlen == -2)
{
/* cstring */
result = strlen(DatumGetCString(value)) + 1;
}
现在,让我们建个表,插入这些相同数据
postgres=# create table test as select repeat('1234567890',(2^n)::integer) AS data FROM generate_series(0,12) n;
SELECT 13
postgres=# select octet_length(data), pg_column_size(data) FROM test;
octet_length | pg_column_size
--------------+----------------
10 | 11
20 | 21
40 | 41
80 | 81
160 | 164
320 | 324
640 | 644
1280 | 1284
2560 | 51
5120 | 79
10240 | 138
20480 | 254
40960 | 488
(13 rows)
这次可以看到又有所不同了,原因想必各位已经清楚了——pg_column_size 也会计算 "toast-able" 的值,建表之后,默认 data 列是变长列,存储策略是 extended,允许压缩和行外存储。会先尝试压缩,如果还是太大,就会行外存储。这是大多数可以 TOAST 的数据类型的默认策略。
前面多了 1 个字节的都是 varattrib_1b (不超过 127 byte),多了 4 个字节的是 varattrib_4b (不超过 1GB),而后面的 51、79 说明是被压缩了,最简单的验证方式查询 TOAST 表即可。
postgres=# truncate table test;
TRUNCATE TABLE
postgres=# insert into test select repeat('1234567890',(2^n)::integer) FROM generate_series(8,12) n;
INSERT 0 5
postgres=# SELECT oid::regclass,
reltoastrelid::regclass,
pg_relation_size(reltoastrelid) AS toast_size
FROM pg_class
WHERE relkind = 'r'
AND reltoastrelid <> 0
and relname = 'test' ORDER BY 3 DESC;
oid | reltoastrelid | toast_size
------+-------------------------+------------
test | pg_toast.pg_toast_25889 | 0
(1 row)
postgres=# select * from pg_toast.pg_toast_25889;
chunk_id | chunk_seq | chunk_data
----------+-----------+------------
(0 rows)
现在让我们修改列的策略是 external,允许行外存储,但不许压缩,这次 toast 表就有数据了。
postgres=# truncate table test;
TRUNCATE TABLE
postgres=# alter table test alter column data set storage external ;
ALTER TABLE
postgres=# insert into test select repeat('1234567890',(2^n)::integer) FROM generate_series(0,12) n;
INSERT 0 13
postgres=# select octet_length(data), pg_column_size(data) FROM test ;
octet_length | pg_column_size
--------------+----------------
10 | 11
20 | 21
40 | 41
80 | 81
160 | 164
320 | 324
640 | 644
1280 | 1284
2560 | 2560
5120 | 5120
10240 | 10240
20480 | 20480
40960 | 40960
(13 rows)
postgres=# select count(*) from pg_toast.pg_toast_25889;
count
-------
43
(1 row)
另外,就是我们日常使用的获取表大小的函数有很多种,比如 pg_relation_size、pg_table_size
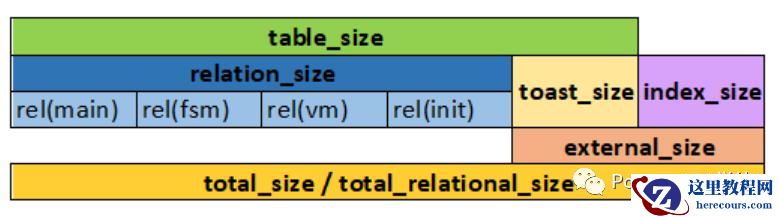
参照此图,我们可以看到:
pg_relation_size 会包含各个 fork,也就是我们熟知的 fsm、vm 等,但不会包含 toast 的大小
pg_table_size 会额外包含 TOAST 的大小,但不包括索引。
total_relation_size 会包括全部大小,包括索引
postgres=# SELECT
relname AS table_name,
pg_size_pretty(pg_total_relation_size(relid)) AS total,
pg_size_pretty(pg_relation_size(relid)) AS internal,
pg_size_pretty(pg_table_size(relid) - pg_relation_size(relid)) AS external,
pg_size_pretty(pg_indexes_size(relid)) AS indexes
FROM pg_catalog.pg_statio_user_tables where relname = 'test' ORDER BY pg_total_relation_size(relid) DESC;
table_name | total | internal | external | indexes
------------+--------+------------+----------+---------
test | 128 kB | 8192 bytes | 120 kB | 0 bytes
(1 row)
小结
通过这个例子,各位其实可以发现,generate_series 的处理方式类似于从表中获取数据,每次都多了一个 4 字节的 Varlena header ,用于存储不超过 1GB 的数据,而实际的表,会根据 TOAST 策略,选择是压缩,还是行内存储,还是存储在 TOAST 表中。
参考
https://www.postgresql.org/docs/current/functions-admin.html
https://zh.wikipedia.org/wiki/UTF-8





")


")


")
