让我们首先创建一些表:
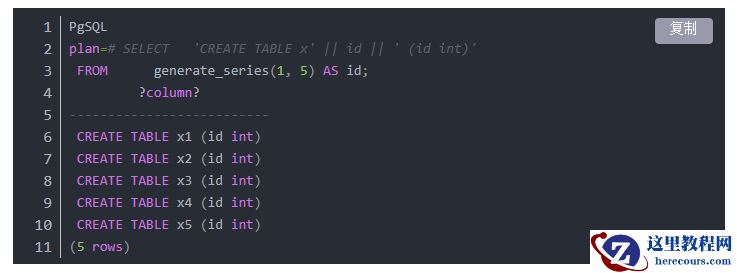 在 PostgreSQL 中,我们可以轻松地使用 SQL 创建 SQL。psql 的优点在于,只需运行 gexec 即可将先前的输出用
作新输入:
在 PostgreSQL 中,我们可以轻松地使用 SQL 创建 SQL。psql 的优点在于,只需运行 gexec 即可将先前的输出用
作新输入:

在 POSTGRESQL 中连接表
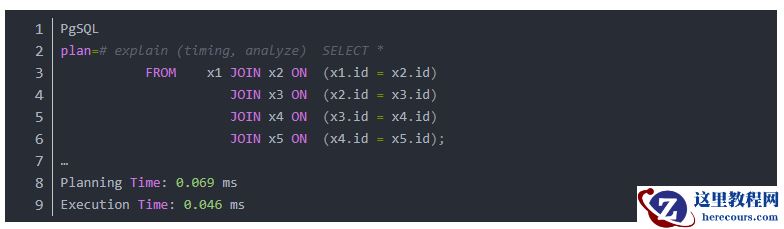
控制 SQL 中的连接行为
如果规划时间是一个问题,我们可以强制 PostgreSQL 使用我们希望它使用的连接顺序。控制此行为的变量是
join_collapse_limit。这是什么意思?基本上它控制隐式规划的显式连接的数量。换句话说:PostgreSQL 可以优化
多少个显式连接。
如果我们将这个变量设置为 1,则意味着我们强制 PostgreSQL 使用我们选择的连接顺序:
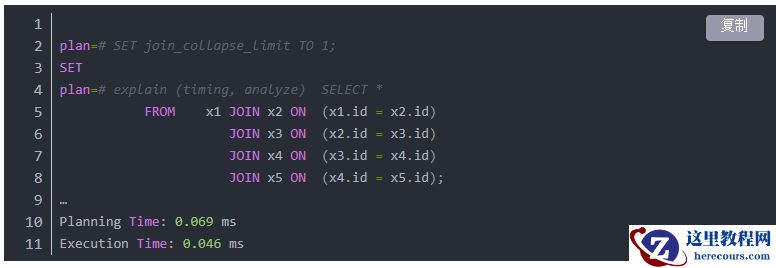 真正值得注意的是规划速度的显著提升。我们可以看到惊人的 4 倍加速。
但是,我还要提醒大家:优化器首先尝试重新构建连接是有原因的。如果查询比我们在此示例中看到的更昂贵,
那么投入更多时间创建计划就很有意义了。换句话说:除非最终用户完全了解正在发生的事情,否则更改此变量
可能会适得其反。因此,我们建议在更改此设置之前使用真实数据和真实工作负载测试您的查询和整个设置。通常,
只更改单个查询的变量并保留 postgresql.conf 中的默认值(与所有其他操作一样)也是有益的。
真正值得注意的是规划速度的显著提升。我们可以看到惊人的 4 倍加速。
但是,我还要提醒大家:优化器首先尝试重新构建连接是有原因的。如果查询比我们在此示例中看到的更昂贵,
那么投入更多时间创建计划就很有意义了。换句话说:除非最终用户完全了解正在发生的事情,否则更改此变量
可能会适得其反。因此,我们建议在更改此设置之前使用真实数据和真实工作负载测试您的查询和整个设置。通常,
只更改单个查询的变量并保留 postgresql.conf 中的默认值(与所有其他操作一样)也是有益的。










")

")
