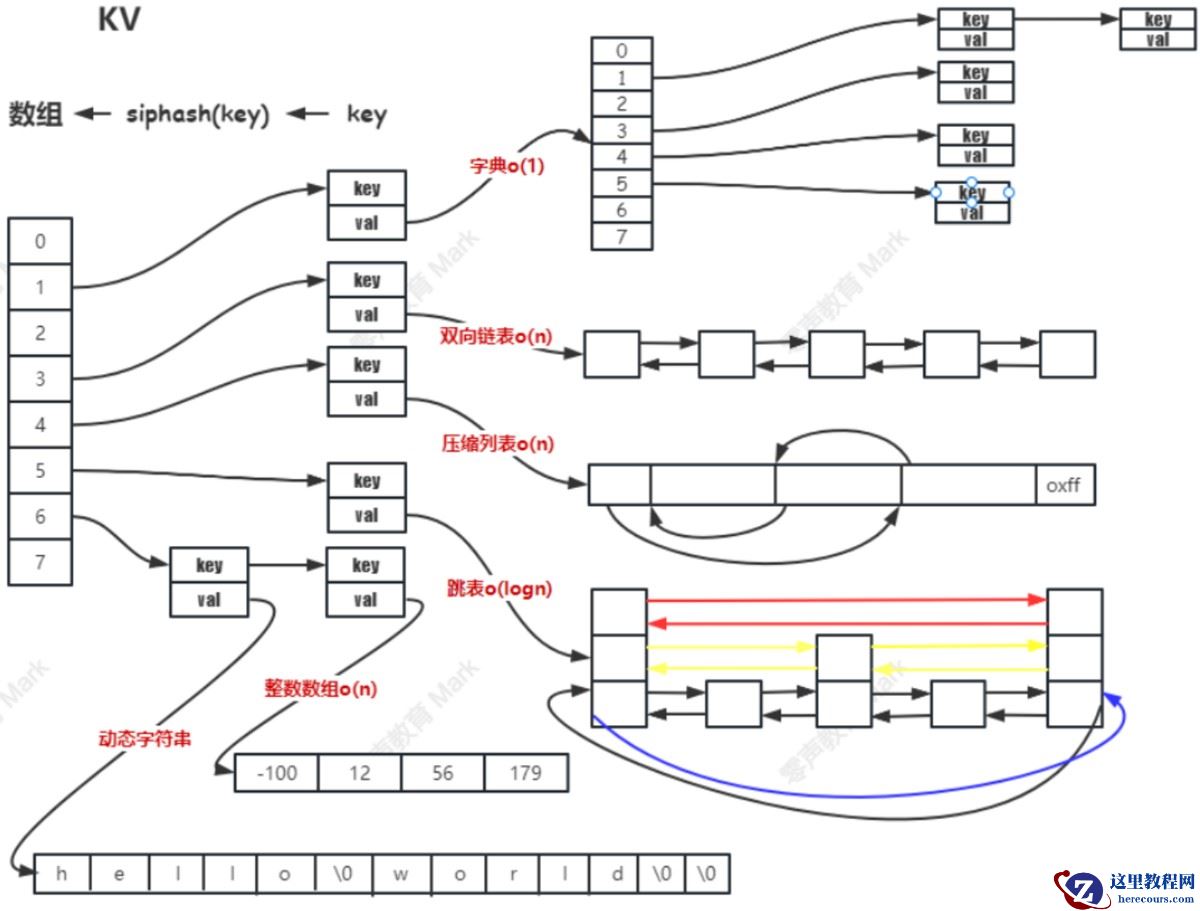
1.1 KV结构
Redis 本质上是一个 Key-Value(键值对,KV)数据库,在它丰富多样的数据结构底层,都基于一种统一的键值对存储结构来进行数据的管理和操作
Redis 使用一个全局的哈希表来管理所有的键值对,这个哈希表就像是一个大字典,通过键(Key)能快速定位到对应的值(Value)。
从用户视角看,用户使用各种命令操作不同类型的数据结构(如 String、Hash、List 等),但从底层实现角度,它们都是以键值对形式存储在这个哈希表中。
Redis的存储分类的目的是,在数据量小的时候,追求存储效率高;在数据量大的时候,追求运行速度快。
1.2 字典(dict)
Redis 中的字典(dict) 是一种高效的键值对存储结构,广泛用于实现 Redis 核心的 KV 存储(全局键值对)以及 Hash 类型在数据量较大时的底层存储(当 Hash 节点数>512 或字符串长度>64 时)。
其设计借鉴了哈希表的思想,通过链地址法处理冲突,并支持动态扩容(重哈希)以保证性能
字典数据结构组成
字典由三个核心结构体组成,层层嵌套实现哈希表的功能:
1.dictEntry哈希表节点
存储单个键值对(key-value),next 指针用于连接哈希冲突的节点(形成链表)
typedef struct dictEntry { void *key; // 键(字符串类型) union { // 值(支持多种类型) void *val; // 指针类型(如复杂数据结构) uint64_t u64; // 无符号整数 int64_t s64; // 有符号整数 double d; // 浮点数 } v; struct dictEntry *next; // 下一个节点指针(处理哈希冲突的链表) } dictEntry;
2.dictht哈希表
管理哈希表数组,table 是存放 dictEntry 指针的数组,sizemask 用于快速计算键的索引(替代取余运算)。
typedef struct dictht { dictEntry **table; // 哈希表数组(存储dictEntry指针) unsigned long size; // 数组长度(必须是2的幂,如4、8、16...) unsigned long sizemask; // 掩码,值为 size-1(用于计算数组索引) unsigned long used; // 已存储的节点数量(key-value总数) } dictht;
3.dict字典顶层结构
通过 ht[2] 支持渐进式重哈希(避免一次性扩容的性能波动),rehashidx 跟踪重哈希进度。
typedef struct dict { dictType *type; // 字典类型(包含哈希函数、键值复制/释放函数等) void *privdata; // 私有数据(供type中的函数使用) dictht ht[2]; // 两个哈希表(ht[0]:当前使用;ht[1]:重哈希时使用) long rehashidx; // 重哈希索引(-1表示未进行重哈希;≥0表示当前迁移进度) int16_t pauserehash; // 重哈希暂停标记(>0表示暂停,避免遍历期间干扰) } dict;
哈希运算与索引映射
字典通过哈希函数将 key 映射到哈希表数组的索引,步骤如下:
计算哈希值:对 key(字符串)执行哈希函数(如 siphash),得到一个 64 位整数哈希值。
映射到数组索引:利用 sizemask(size-1)对哈希值进行位运算(哈希值 & sizemask),得到数组索引。
示例:若 size=4(2 的幂),则 sizemask=3(二进制 11)。哈希值 5(二进制 101)与 3 做 & 运算,结果为 1(二进制 01),即索引为 1。
优势:位运算(&)比取余运算(%)效率更高,且当 size 是 2 的幂时,哈希值 % size 等价于 哈希值 & sizemask。
哈希冲突的处理
由于哈希值范围(64 位)远大于哈希表数组长度(size),根据抽屉原理(n+1 个苹果放入 n 个抽屉,至少一个抽屉有 2 个),必然存在不同 key 映射到同一索引的情况(哈希冲突)。
字典采用链地址法解决冲突:
每个dictEntry 节点通过 next 指针形成单向链表,同一索引的所有冲突节点串联在链表中。查找时:先通过索引定位到链表头,再遍历链表比较 key 以找到目标节点(时间复杂度:理想 O (1),冲突严重时 O (n))。
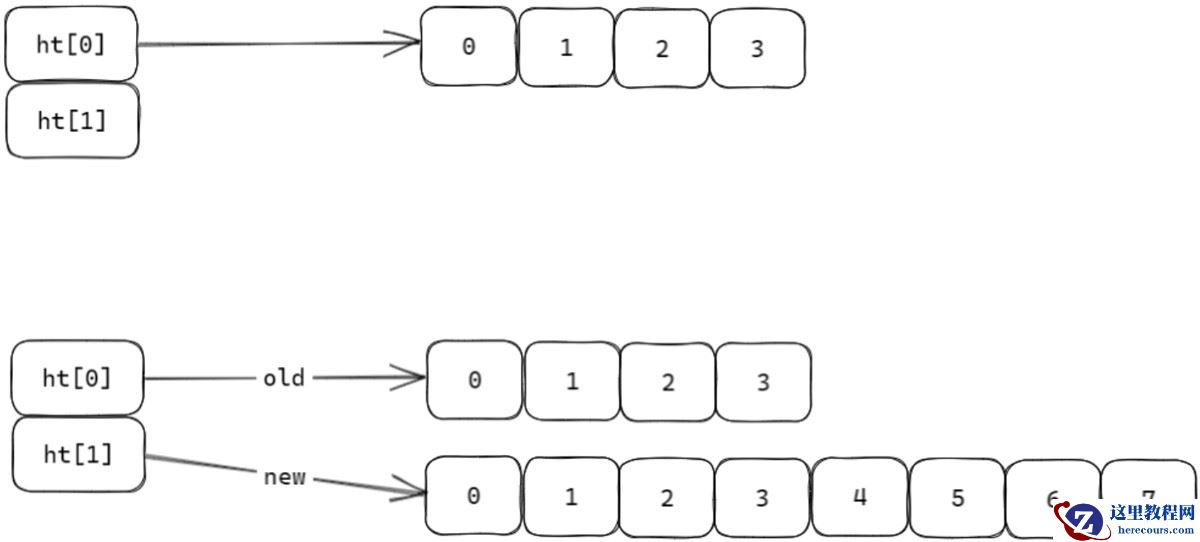
渐进式重哈希(扩容 / 缩容)
当哈希表的负载因子(used / size)过高(扩容)或过低(缩容)时,需要调整数组大小以优化性能:
size 扩大为当前的 2 倍(仍为 2 的幂)。缩容触发:负载因子<0.1,size 缩小为大于 used 的最小 2 的幂。
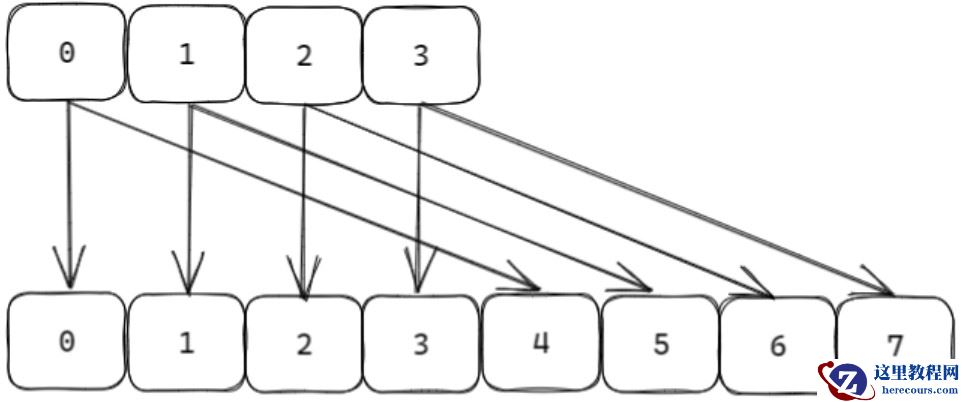
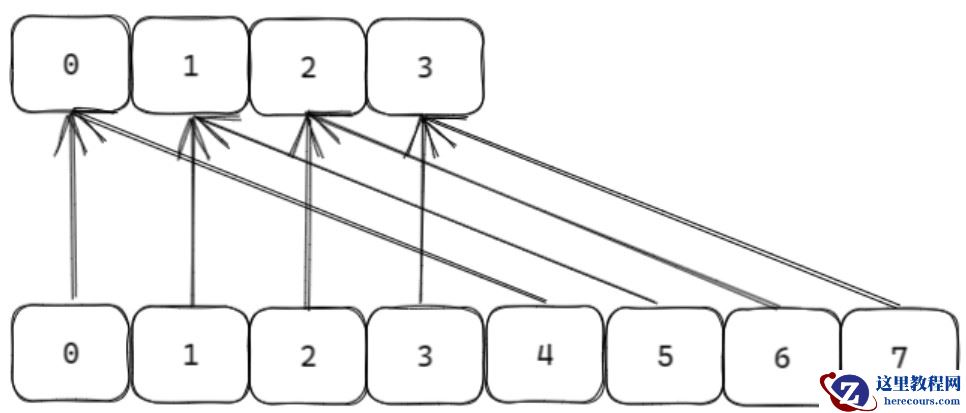
为避免一次性迁移所有节点导致的性能阻塞,字典采用渐进式重哈希:
初始化:创建 ht[1] 并设置新 size(如扩容为 ht[0].size * 2),rehashidx 设为 0(开始重哈希)。
渐进式迁移:
每次对字典执行增删改查时,顺带将ht[0] 中 rehashidx 索引的所有节点迁移到 ht[1],并将 rehashidx 递增 1。遍历操作(如 HGETALL)时,会暂停重哈希(pauserehash 标记),避免遍历期间节点迁移导致数据不一致。
完成迁移:当 ht[0].used 变为 0 时,释放 ht[0],将 ht[1] 赋值给 ht[0],ht[1] 重置为空,rehashidx 设为 - 1(重哈希结束)。
scan
Redis 的 scan 命令是用于渐进式遍历集合类数据(如键空间、哈希表、集合等)的命令,主要解决了 keys 命令因一次性全量遍历导致服务器阻塞的问题
实现目标:
实现对 scan 开始时刻已存在的数据 进行遍历,保证 不重复、不遗漏不阻塞服务器,通过分批次、渐进式的方式遍历,每次返回部分结果,避免一次性处理大量数据导致的性能波动。遍历机制:
遍历顺序:采用 高位进位加法 的遍历顺序。这种方式的优势是,在哈希表发生扩容 / 缩容(rehash)时,新旧哈希表的槽位在遍历顺序上是相邻的,确保遍历过程能适配哈希表结构的动态变化,维持遍历的连续性。游标机制:通过游标(cursor)记录每次遍历的位置。首次调用时游标为0,每次返回部分元素和新游标,当游标为 0 时表示遍历结束。

scan 仍能正确遍历 scan 开始时已存在的数据,不会因 rehash 导致重复或遗漏。
1.3 Expire 机制
Redis 的 expire 机制用于管理设置了过期时间的键(key),通过两种核心策略结合,在 “内存占用” 与 “性能消耗” 之间平衡,确保过期键能被及时清理
1. 惰性删除(Lazy Expiration)
触发时机:
当执行任何涉及该 key 的命令(如 GET、SET 等)时,Redis 会先检查 key 是否过期。
执行逻辑:
若 key 已过期,立即删除该 key,再执行后续命令;若未过期,直接执行命令。特点:
优势:“按需删除”,不占用额外 CPU 资源(仅在访问时检查);劣势:若过期 key 长期未被访问,会占用内存(内存泄漏风险)。适用范围:仅支持对最外层 key 设置过期时间(如 Hash、List 等结构的内部字段无法单独设置过期时间)。
相关命令:
expire key seconds:设置 key 的过期时间(秒);pexpire key milliseconds:设置 key 的过期时间(毫秒);ttl key:返回 key 剩余过期时间(秒,-1 表示永不过期,-2 表示已过期);pttl key:返回 key 剩余过期时间(毫秒)。
2. 定时删除(Active Expiration)
为弥补惰性删除的内存泄漏问题,Redis 同时采用定时删除策略,主动清理部分过期 key。
触发机制:由后台定时器定期执行,每次检查一定数量的过期 key。
核心配置与逻辑:
默认每次检查 25 个 key(由ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 定义);可通过 effort 参数调整检查强度(默认 1,最大 10),计算公式为:config_keys_per_loop = 20 + 20/4*effort(effort 越大,每次检查的 key 越多);执行函数 activeExpireCycleTryExpire 负责具体的过期检查与删除。
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */ /*The default effort is 1, and the maximum configurable effort * is 10. */ config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP + ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort, int activeExpireCycleTryExpire(redisDb *db, dictEntry *de, long long now);
特点:
优势:主动清理长期未访问的过期 key,减少内存占用;劣势:若检查过于频繁,会消耗 CPU 资源(Redis 通过控制检查频率和数量避免性能波动)。惰性删除保证 “访问时过期键必被清理”,避免无效数据干扰;定时删除主动清理 “长期未访问的过期键”,防止内存溢出。两者结合,既保证了性能,又控制了内存占用
1.4 大Key
“大 Key” 指 Redis 中存储的体积过大的对象(如包含数万字段的 Hash、百万元素的 ZSet 等),这类 key 会导致明显的性能问题
大 Key 的危害
扩容卡顿:大 Key 所在的哈希表或数据结构(如 Hash、ZSet)扩容时,需要一次性申请大量内存(如从 1MB 扩容到 2MB),可能导致 Redis 短暂阻塞;删除卡顿:删除大 Key 时,Redis 需要一次性释放大量内存,触发内存回收机制,同样会导致卡顿;内存波动:大 Key 的创建 / 删除会导致 Redis 内存使用 “大起大落”,容易触发内存告警或 OOM(内存溢出)。大Key 的检测
通过 Redis 自带的 redis-cli --bigkeys 命令检测大 Key,该命令基于 SCAN 遍历所有键,统计不同类型中体积最大的键。
redis-cli -h 127.0.0.1 --bigkeys -i 0.1
--bigkeys:开启大 Key 检测;-i 0.1:每执行 100 条 SCAN 命令后,暂停 0.1 秒,避免检测过程阻塞 Redis 服务。
解决方案
拆分大 Key:将大 Hash 拆分为多个小 Hash,大 ZSet 按范围拆分为多个小 ZSet;避免批量操作:对大 Key 避免使用HGETALL、ZRANGE 0 -1 等全量查询命令;异步删除:Redis 4.0+ 支持 UNLINK 命令(异步删除),替代 DEL,减少删除时的卡顿。
1.5 跳表
Redis 中的跳表(Skiplist)是一种多层级有序链表结构,主要用于实现有序集合(ZSet),支持高效的范围查询(如 ZRANGE、ZREVRANGE)和排序操作。其设计兼顾了查询性能与实现复杂度,通过 “空间换时间” 的思路,在保证平均时间复杂度接近 平衡树的同时,避免了复杂的节点分 裂 / 重构操作
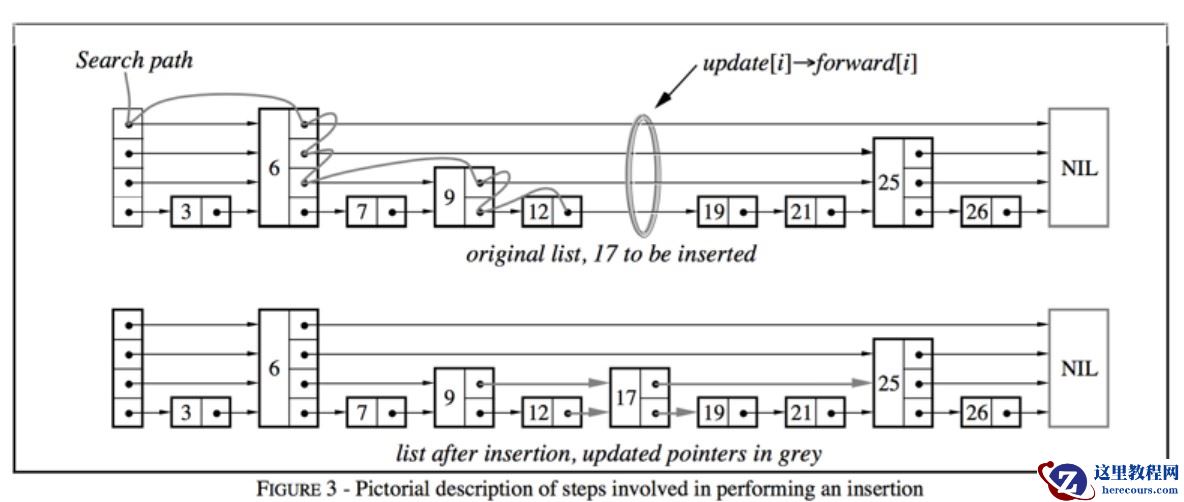
为什么使用跳表?
跳表的诞生是为了解决 “有序集合的高效查询与修改” 问题:
有序数组通过二分查找可实现 O (logN) 查询,但插入 / 删除需移动元素(O (N) 复杂度);平衡二叉树(如 B+ 树)可实现 O (logN) 操作,但节点分 裂 / 合并逻辑复杂,不适合 Redis 对 “简单高效” 的需求;跳表通过多层级链表模拟 “跳跃式查询”,兼顾查询效率(接近 O (logN))和实现简单性(插入 / 删除无需复杂重构),成为 ZSet 的理想底层结构。跳表时间复杂度分析
理想跳表的逻辑
理想情况下,跳表每间隔一个节点生成一个 “高层级节点”,模拟二叉树结构(如第 1 层每 2 个节点有 1 个高层节点,第 2 层每 4 个节点有 1 个高层节点),此时查询时间复杂度为 O(logN)。但这种结构在插入 / 删除后难以维护(重构成本极高)。
概率化跳表(实际实现)
为避免重构,跳表采用概率化层级生成:
每个新节点有 25%(Redis 中为ZSKIPLIST_P=0.25)的概率增加 1 个层级,25%×25% 的概率增加 2 个层级,以此类推(最高层级有限制)。当数据量足够大(如 ≥128)时,概率化生成的跳表结构趋向于理想跳表,查询、插入、删除的平均时间复杂度仍为 O(logN),且无需复杂重构。
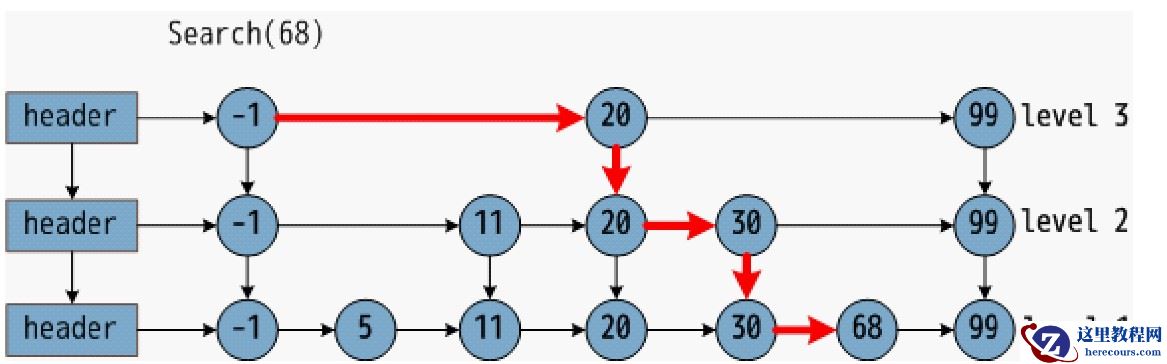
跳表的实现
最高层级:ZSKIPLIST_MAXLEVEL=32(足够支持 2^64 个元素),避免层级过高导致的内存浪费。层级概率:ZSKIPLIST_P=0.25(1/4),即每个节点晋升到下一层的概率为 25%,平衡层级数量与内存占用。
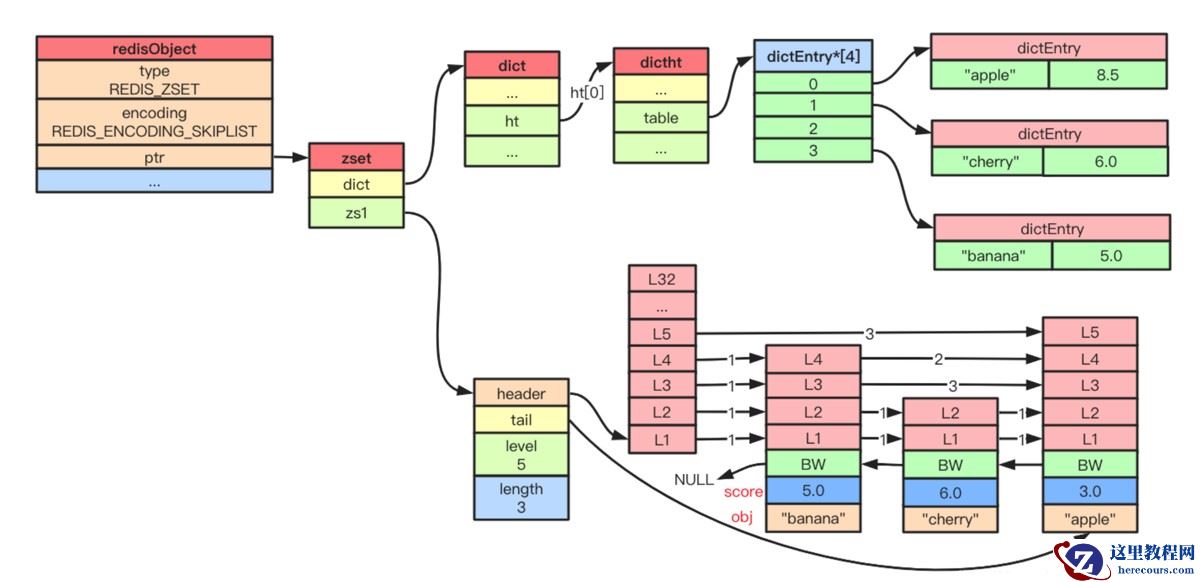
Redis 跳表通过 zskiplistNode(节点)和 zskiplist(跳表顶层结构)实现,配合 zset 结构体与字典(dict)协同工作
// 跳表节点 typedef struct zskiplistNode { sds ele; // 元素值(字符串) double score; // 排序分数(仅支持浮点数) struct zskiplistNode *backward; // 后退指针(用于反向遍历) struct zskiplistLevel { struct zskiplistNode *forward; // 前进指针(当前层级的下一个节点) unsigned long span; // 跨度(当前节点到下一个节点的元素数量,用于计算排名 ZRANK) } level[]; // 动态层级数组(长度为节点实际层级) } zskiplistNode; // 跳表顶层结构 typedef struct zskiplist { struct zskiplistNode *header, *tail; // 头节点、尾节点 unsigned long length; // 元素总数(对应 ZCARD 命令) int level; // 当前跳表的最高层级 } zskiplist; // ZSet 结构体(结合跳表与字典) typedef struct zset { dict *dict; // 字典:key=元素值,value=分数(快速查询元素分数) zskiplist *zsl; // 跳表:按分数排序,支持范围查询 } zset;
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。












