整理MySQL常用性能相关参数如下 general_log记录所有执行的语句,在需要分析问题打开即可,正常服务时不需要开启,以免带来io性能影响 query_cache_size缓存sql文本和查询结果的,如果对应的表没有变化,下次碰到一样的SQL,跳过解析和查询,直接返回结果。但是表变化非常频繁,SQL也是动态生产的,由于需要不断更新cache内容,这时锁力度很大,反而照成瓶颈。这时最好关掉这个功能,设置参数为0 sort_buffer_size针对单个session的参数,排序时,如果用不到index,session就会申请一块这么大的内存空间进行排序。如果这个参数值过小会把排序结果写入硬盘中,会影响效率。如果太大,又可能导致物理内存耗尽,导致OOM。 join_buffer_size在join无法使用到index时候用到的buffer,和sort_buffer_size类似 tmp_table_size在group by和distinct时如果SQL用不到索引,就会使用系统内部临时表记录中间状态。如果该值不够大,就使用物理硬盘。mysql> show global status like 'created_tmp%';+-------------------------+-------+| Variable_name | Value |+-------------------------+-------+| Created_tmp_disk_tables | 0 || Created_tmp_files | 5 || Created_tmp_tables | 23 |+-------------------------+-------+3 rows in set (0.00 sec)每次创建临时表,Created_tmp_tables增加,如果临时表大小超过tmp_table_size,则是在磁盘上创建临时表,Created_tmp_disk_tables也增加,Created_tmp_files表示MySQL服务创建的临时文件文件数,比较理想的配置是:Created_tmp_disk_tables / Created_tmp_tables * 100% <= 25%默认为16M,可调到64-256最佳,线程独占,太大可能内存不够I/O堵塞注意:MySQL中的 max_heap_table_size 参数会影响到临时表的内存缓存大小 。 max_heap_table_size 是MEMORY内存引擎的表大小 , 因为临时表也是属于内存表所以也会受此参数的限制 所以如果要增加 tmp_table_size 的大小 也需要同时增加 max_heap_table_size 的大小 table_open_cache所有线程打开表数量,增加这个值会增加mysqld需要的文件描述符数量mysql> show global status like 'open%tables%';
+---------------+-------+| Variable_name | Value |+---------------+-------+| Open_tables | 1182 | --打开后在缓存中的表数量| Opened_tables | 1189 | --打开的所有表数量+---------------+-------+2 rows in set (0.00 sec)系统高峰时在没有执行flush tables命令时,通过以上两个值来判断 table_open_cache参数是否到达瓶颈
当缓存中的值open_tables 临近到了 table_open_cache 值时,说明表缓存池快要满了但Opened_tables还在一直有增长 说明你还有很多未被缓存的表,这时可以适当增加 table_open_cache 的大小。
如:通过 show processlist 看到大量的 Opening tables、closing tables状态,导致应用端访问操作。
需要确认 table_open_cache=最大并发数表数量(join里可能用到2张表),时候满足当前配置。
如:但并发线程数达到1000,假设这些并发连接中有40%是访问2张表,其他都是单表,那么cache size就会达到(1000*40%2+1000*60%*1)=1400
建议定期监控值:
Open_tables / Opened_tables >= 0.85 表的重复使用率
Open_tables / table_open_cache <= 0.95 缓存里存在已打开的表
Innodb_buffer_pool_sizeInnoDB最重要的缓存,用来缓存innodb索引页面、undo页面及其他辅助数据。一般设定物理内存50%~75%
Innodb_buffer_pool_instances通过这个参数可以把整块buffer pool分割为多块instance内存空间,每个空间独立管理自己的内存和链表,来提升MySQL请求处理的并发能力。因为buffer pool是通过链表来管理的,同时为了保护页面,需要在存取的时候对链表加锁,在多线程情况下,并发读写buffer pool缓存会有锁竞争和等待。官方说超过1G的Innodb_buffer_pool_size 考虑设定instances去切分内存
Innodb_log_file_size,innodb_log_files_in_group两个参数决定redo空间的大小,设置存储更新redo越大,有效降低buffer pool脏页被淘汰的速度,减少了checkpoint此书,降低磁盘I/O不过设置过大,在数据库异常宕机时,恢复时间越长
Innodb_old_blocks_pct,innodb_old_blocks_time
innodb_old_blocks_pct:全局、动态变量,默认值 37,取值范围为5~95. 用来确定LRU链表中old sublist所占比例innodb_old_blocks_time:全局、动态变量,默认值 1000,取值范围为0~2**32-1,单位ms。用来控制old sublist中page的转移策略,新的page页在进入LRU链表中时,会先插入到old sublist的头部,然后page需要在old sublist中停留innodb_old_blocks_time这么久后,下一次对该page的访问才会使其移动到new sublist的头部,该参数的设置可以保护new sublist,尽可能的防止其being filled by page that is referenced only for a brief period。
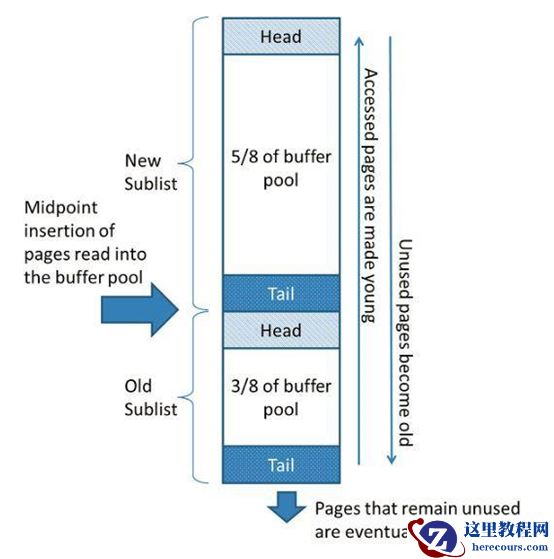 默认的缓冲中的页在第一次被读取时(也就是命中缓存)会被移动到新页子表头部,意味着其会长期待在缓冲池中不会被淘汰。这样就会存在一个问题,一次表扫描(比如使用select查询)可能会将大量数据放入缓存中,并淘汰相应数量的旧数据,但是可能这些数据只使用一次,后面不再使用;同样地,因为read-ahead也会在下一次访问该页时被放入新页子表头部。这些情形会将本应会被频繁使用的页移动到旧页子表中。所以3/8位置处。在后面的第一次命中(被访问时)的页会被移动到列表的头部。因此,那些读入缓存但是后面从来不会被访问的页也从不会被放入列表的头部,也就会在后面被从缓冲池淘汰。MySQL提供了配置参数,milliseconds)读取不会被标识为年轻,也就是不会被移动到列表头部。参数1000,增大这个参数将会造成更多的页会更快的从缓冲池中被淘汰。参考:
https://blog.csdn.net/u014710633/java/article/details/94594598
https://www.jianshu.com/p/10bd165a6a48
Innodb_flush_methodInnodb刷数据和日志到磁盘的方式,这个值默认为空,其实:Linux默认fsyncWindows 默认async_unbufferedSSD和PCIE存储时可以使用o_direct 提升性能
Innodb_doublewriteMySQL默认每个page size是16k,而OS通常最小I/O单元是4k,所以如果写page时可能需要调用4次OS I/O才能完成。假定在执行两次时DB crash了,这时page只写了一部分,就产生了partial write(不完整写)。MySQL double write的设定就是为了在发生partial write时任然保证已经commit的数据不丢失,以及数据文件不损坏。但如果底层存储支持原子性可以关闭两次写,主要看OS page size和DB page size的关系。参考:
http://blog.itpub.net/25583515/viewspace-2685493/
Innodb_io_capacity控制后台不断将内存(dirty data)数据flush硬盘的操作,遇到周期性IO QPS下降时可以考虑提高参数的设定,以加速flush的频率参考实验提高Innodb_io_capacity的设置,已提升QPS
http://blog.itpub.net/26506993/viewspace-2214703/
Innodb_thread_concurrency在并发量大的时,增加这个值,儿科降低innodb在并发线程之间切换开销,以增加系统的并发吞吐量
innodb_flush_log_at_trx_commit控制redo log刷盘机制
innodb_flush_log_at_trx_commit=0事务提交时,不会处理log buffer的内容,也不会处理log file在OS cache的刷盘操作,由MySQL后台master线程每隔1秒将log buffer刷新到磁盘的log file中。在MySQL服务宕掉,服务器正常或宕机时:由于事务提交不刷新logbuffer,即使事务提交了,logbuffer也会全部丢失,但只丢失最近1秒的事务
innodb_flush_log_at_trx_commit=1事务提交时,会将log buffer的内容写入OS cache文件中,同时会将OS cache刷新到磁盘log file中。在MySQL服务宕掉,服务器正常或宕机时:由于事务提交会刷新到磁盘log file中,所以数据都不会丢失
innodb_flush_log_at_trx_commit
=2事务提交时,会将log buffer的内容写到OS cache文件中,由MySQL后台master线程每隔1秒将OS cache的log file刷新到磁盘。在MySQL服务宕掉,服务器正常:
由于事务已经刷新到OS cache中,然而服务器没宕机,这样日志还是会被刷新到磁盘中,那么数据就不会丢失在MySQL服务宕掉,服务器宕机:由于事务只刷新到OS cache中,服务器宕机话,日志没用被刷新到磁盘中,会丢失1秒的事务
sync_binlog控制binlog同步到磁盘的方式
sync_binlog=0,事务提交时将MySQL Binlog信息写入OS cache Binlog中,由OS自己空间其缓存的刷新。如果是服务器宕机binlog cache中所有binlog都会丢失
sync_binlog=1,每个事务提交时,MySQL都会把Binlog刷新到物理磁盘中。这样安全性最高,性能损耗是最大。特别是在多事务同行提交,会对I/O性能带来很大影响。
但
group commit可以缓解压力:
binlog_group_commit_sync_delay=N,默认是0,定时执行,在commit后等待N 微秒后,进行binlog刷盘操作
binlog_group_commit_sync_no_delay_count=N,在commit后等待达到最大事务等待数量N, 就忽视binlog_group_commit_sync_delay的设置,直接开始刷盘,注意如果binlog_group_commit_sync_delay设置为0,则此选项无效不过group commit的设置,可能会影响commit执行执行速度,可参考:
https://www.cnblogs.com/ziroro/p/9600359.html
默认的缓冲中的页在第一次被读取时(也就是命中缓存)会被移动到新页子表头部,意味着其会长期待在缓冲池中不会被淘汰。这样就会存在一个问题,一次表扫描(比如使用select查询)可能会将大量数据放入缓存中,并淘汰相应数量的旧数据,但是可能这些数据只使用一次,后面不再使用;同样地,因为read-ahead也会在下一次访问该页时被放入新页子表头部。这些情形会将本应会被频繁使用的页移动到旧页子表中。所以3/8位置处。在后面的第一次命中(被访问时)的页会被移动到列表的头部。因此,那些读入缓存但是后面从来不会被访问的页也从不会被放入列表的头部,也就会在后面被从缓冲池淘汰。MySQL提供了配置参数,milliseconds)读取不会被标识为年轻,也就是不会被移动到列表头部。参数1000,增大这个参数将会造成更多的页会更快的从缓冲池中被淘汰。参考:
https://blog.csdn.net/u014710633/java/article/details/94594598
https://www.jianshu.com/p/10bd165a6a48
Innodb_flush_methodInnodb刷数据和日志到磁盘的方式,这个值默认为空,其实:Linux默认fsyncWindows 默认async_unbufferedSSD和PCIE存储时可以使用o_direct 提升性能
Innodb_doublewriteMySQL默认每个page size是16k,而OS通常最小I/O单元是4k,所以如果写page时可能需要调用4次OS I/O才能完成。假定在执行两次时DB crash了,这时page只写了一部分,就产生了partial write(不完整写)。MySQL double write的设定就是为了在发生partial write时任然保证已经commit的数据不丢失,以及数据文件不损坏。但如果底层存储支持原子性可以关闭两次写,主要看OS page size和DB page size的关系。参考:
http://blog.itpub.net/25583515/viewspace-2685493/
Innodb_io_capacity控制后台不断将内存(dirty data)数据flush硬盘的操作,遇到周期性IO QPS下降时可以考虑提高参数的设定,以加速flush的频率参考实验提高Innodb_io_capacity的设置,已提升QPS
http://blog.itpub.net/26506993/viewspace-2214703/
Innodb_thread_concurrency在并发量大的时,增加这个值,儿科降低innodb在并发线程之间切换开销,以增加系统的并发吞吐量
innodb_flush_log_at_trx_commit控制redo log刷盘机制
innodb_flush_log_at_trx_commit=0事务提交时,不会处理log buffer的内容,也不会处理log file在OS cache的刷盘操作,由MySQL后台master线程每隔1秒将log buffer刷新到磁盘的log file中。在MySQL服务宕掉,服务器正常或宕机时:由于事务提交不刷新logbuffer,即使事务提交了,logbuffer也会全部丢失,但只丢失最近1秒的事务
innodb_flush_log_at_trx_commit=1事务提交时,会将log buffer的内容写入OS cache文件中,同时会将OS cache刷新到磁盘log file中。在MySQL服务宕掉,服务器正常或宕机时:由于事务提交会刷新到磁盘log file中,所以数据都不会丢失
innodb_flush_log_at_trx_commit
=2事务提交时,会将log buffer的内容写到OS cache文件中,由MySQL后台master线程每隔1秒将OS cache的log file刷新到磁盘。在MySQL服务宕掉,服务器正常:
由于事务已经刷新到OS cache中,然而服务器没宕机,这样日志还是会被刷新到磁盘中,那么数据就不会丢失在MySQL服务宕掉,服务器宕机:由于事务只刷新到OS cache中,服务器宕机话,日志没用被刷新到磁盘中,会丢失1秒的事务
sync_binlog控制binlog同步到磁盘的方式
sync_binlog=0,事务提交时将MySQL Binlog信息写入OS cache Binlog中,由OS自己空间其缓存的刷新。如果是服务器宕机binlog cache中所有binlog都会丢失
sync_binlog=1,每个事务提交时,MySQL都会把Binlog刷新到物理磁盘中。这样安全性最高,性能损耗是最大。特别是在多事务同行提交,会对I/O性能带来很大影响。
但
group commit可以缓解压力:
binlog_group_commit_sync_delay=N,默认是0,定时执行,在commit后等待N 微秒后,进行binlog刷盘操作
binlog_group_commit_sync_no_delay_count=N,在commit后等待达到最大事务等待数量N, 就忽视binlog_group_commit_sync_delay的设置,直接开始刷盘,注意如果binlog_group_commit_sync_delay设置为0,则此选项无效不过group commit的设置,可能会影响commit执行执行速度,可参考:
https://www.cnblogs.com/ziroro/p/9600359.html
sync_binlog=N, 表示每N次事务提交,MySQL会做刷盘。如果DB服务或者服务器宕机会丢失一些事务 注:开启Binlog后,MySQL内部会自动将事务当作一个XA事务处理,在提交事务过程中,会自动分配一个唯一的XID,XID会记录到Binlog和redo log中。事务在提交过程会自动份为Prepare和Commit两个阶段。Prepare阶段:告诉InnoDB做prepare,InnoDB更改事务状态,并将redo log刷入磁盘Commit阶段:先记录Binlog,然后告诉InnoDB commit binlog_format binlog_format=STATEMENT写入执行的SQL语句到binlog,从库读取这些SQL并执行优势:技术成熟减少binlog的写入量binlog包含所有修改语句没便于审计缺点:有些函数不能再slave上复杂,如sleep(),last_insert_id(),udf等会除问题与基于row的复制比,insert...select需要更多的锁隔离级别必须是repeatable-read,而这是发生死锁的元凶之一 binlog_format=MIXED默认使用STATEMENT记录日志,特定情况下转换成ROW记录 binlog_format=ROWMySQL5.7.7之后的默认值优点:复制是最安全的slave需要的锁也最少缺点:binlog会记录更多的数据无法在slave上看到master上获取的语句,因为都是event。但可以开启binlog_rows_query_log_events参数,让binlog记录events同时也记录原始SQL语句。( 复制建议使用row模式,其它模式有可能出现主从数据不一致) tx_isolation MySQL隔离级别,默认是 repeatable-readRead UncommittedRead CommittedRepeatable ReadSerializable这四种级别越来越严格,但性能越来越差。 推荐使用Read Committed,同时binlog_format=ROW ,确认binlog同步数据主从库一致性,兼顾安全,满足绝大多数业务。 slave_parallel_workersMySQL 5.6中,设置参数slave_parallel_workers = 4,即可有4个SQL Thread(coordinator线程)来进行并行复制,其状态为:Waiting for an evant from Coordinator。但是其并行只是基于database的。如果数据库实例中存在多个database,这样设置对于Slave复制的速度可以有比较大的提升。其核心思想是:不同database下的表并发提交时的数据不会相互影响,即slave节点可以用对relay log中不同的schema各分配一个类似SQL功能的线程,来重放relay log中主库已经提交的事务,保持数据与主库一致。 在MySQL 5.7中,引入了基于组提交的并行复制(Enhanced Multi-threaded Slaves), 设置slave_parallel_workers>0并且global.slave_parallel_type=‘LOGICAL_CLOCK’,即可支持一个database下,slave_parallel_workers个的worker线程并发执行relay log中主库提交的事务。其核心思想:一个组提交的事务都是可以并行回放(配合binary log group commit);slave机器的relay log中 last_committed相同的事务(sequence_num不同)可以并发执行。参数slave_parallel_type可以有两个值:DATABASE 默认值,基于库的并行复制方式LOGICAL_CLOCK:基于组提交的并行复制方式 参考: https://www.cnblogs.com/langdashu/p/6125621.html MySQL性能相关参数的使用及说明如上,有理解不准确和不完善的后续再补充。文中内容主要参考:《MySQL运维内参》书籍《深入浅出MySQL》书籍MySQL 5.7官方文档 https://dev.mysql.com/doc/refman/5.7/en/
编辑推荐:
- MySQL性能相关参数03-01
- mysql双写造成主从数据不一致的实验03-01
- 使用elasticsearch搭建自己的搜索系统03-01
- 搭建node服务(二):操作MySQL03-01
- 更改用户host留下的坑03-01
- MySQL索引知识介绍03-01
- Lost connection to MySQL server at 'reading authorization packet'03-01
- 深入理解MDL元数据锁03-01
相关推荐
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-

雷神推出 MIX PRO II 迷你主机:基于 Ultra 200H,玻璃上盖 + ARGB 灯效
2 月 9 日消息,雷神 (THUNDEROBOT) 现已宣布推出基于英
-

制造商 Musnap 推出彩色墨水屏电纸书 Ocean C:支持手写笔、第三方安卓应用
2 月 10 日消息,制造商 Musnap 现已在海外推出一款 Oce









