xid是mysql server层维护的,通过一个全局变量 global_query_id来生成,trx_id是innodb内部维护的,InnoDB 内部维护了一个 max_trx_id 全局变量,每次需要申请一个新的 trx_id 时,就获得 max_trx_id 的当前值,然后并将 max_trx_id 加 1, 如果当前语句是这个事务执行的第一条语句,那么 MySQL 还会同时把 Query_id 赋值给这个事务的 Xid。注意针对XID而言,所有的query(包括查询)都能让 global_query_id加1,但是trx_id而言,只读事务(查询语句)不分配 trx_id,trx_id如果达到最大值2的48次方后,trx_id从0再次开始,这样就会引起脏读,这个和一致性视图+mvcc实现一致性事务读有关系,然后xid存在的意义就是在于当无法通过redo来判断事务是前滚还是回滚,那么就得通过binlog是否完整来判断,然后是通过xid来联系redo和binlog的,接下来具体展开说:
一:首先说XID
Xid 是由 server 层维护的。InnoDB 内部使用 Xid,就是为了能够在 InnoDB 事务和 server 之间做关联。但是,InnoDB 自己的 trx_id,是另外维护的。
那么,Xid 在 MySQL 内部是怎么生成的呢?
MySQL 内部维护了一个全局变量 global_query_id,每次执行语句(包括select语句)的时候将它赋值给 Query_id,然后给这个变量加 1。如果当前语句是这个事务执行的第一条语句,那么 MySQL 还会同时把 Query_id 赋值给这个事务的 Xid。
而 global_query_id 是一个纯内存变量,重启之后就清零了。所以你就知道了,在同一个数据库实例中,不同事务的 Xid 也是有可能相同的。
但是 MySQL 重启之后会重新生成新的 binlog 文件,这就保证了,同一个 binlog 文件里,Xid 一定是惟一的。
虽然 MySQL 重启不会导致同一个 binlog 里面出现两个相同的 Xid,但是如果 global_query_id 达到上限后,就会继续从 0 开始计数。从理论上讲,还是就会出现同一个 binlog 里面出现相同 Xid 的场景。
因为 global_query_id 定义的长度是 8 个字节,这个自增值的上限是 2的64次方-1。要出现这种情况,必须是下面这样的过程:
执行一个事务,假设 Xid 是 A;
接下来执行 2的64次方 个查询语句(因为查询也会让global_query_id加1),让 global_query_id 回到 A;
再启动一个事务,这个事务的 Xid 也是 A。
不过,2的64这个值太大了,大到你可以认为这个可能性只会存在于理论上。
Innodb trx_id
Xid 和 InnoDB 的 trx_id 是两个容易混淆的概念。
Xid 是由 server 层维护的。InnoDB 内部使用 Xid,就是为了能够在 InnoDB 事务和 server 之间做关联。但是,InnoDB 自己的 trx_id,是另外维护的。
首先要说下mysql的两阶段提交:

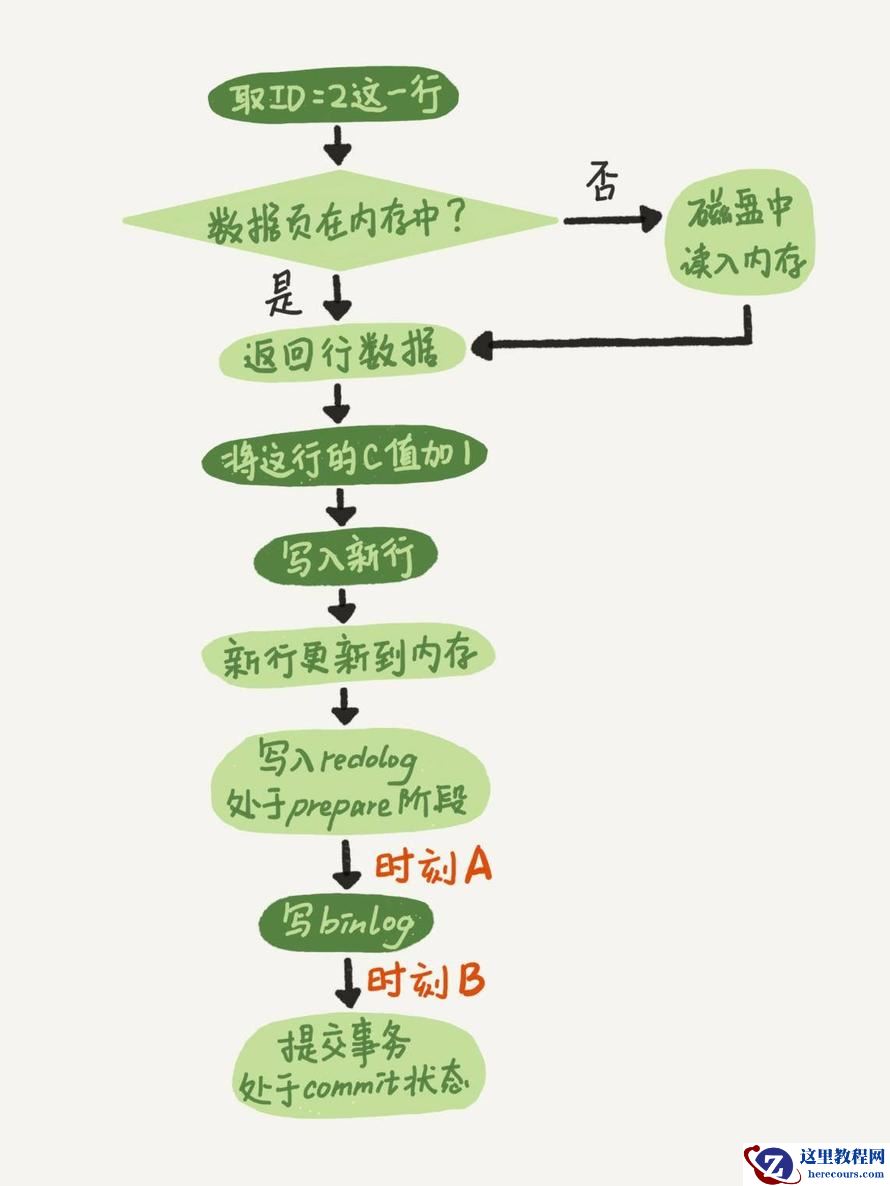

关于两阶段提交中写redo和binlog的时机如下图所示:

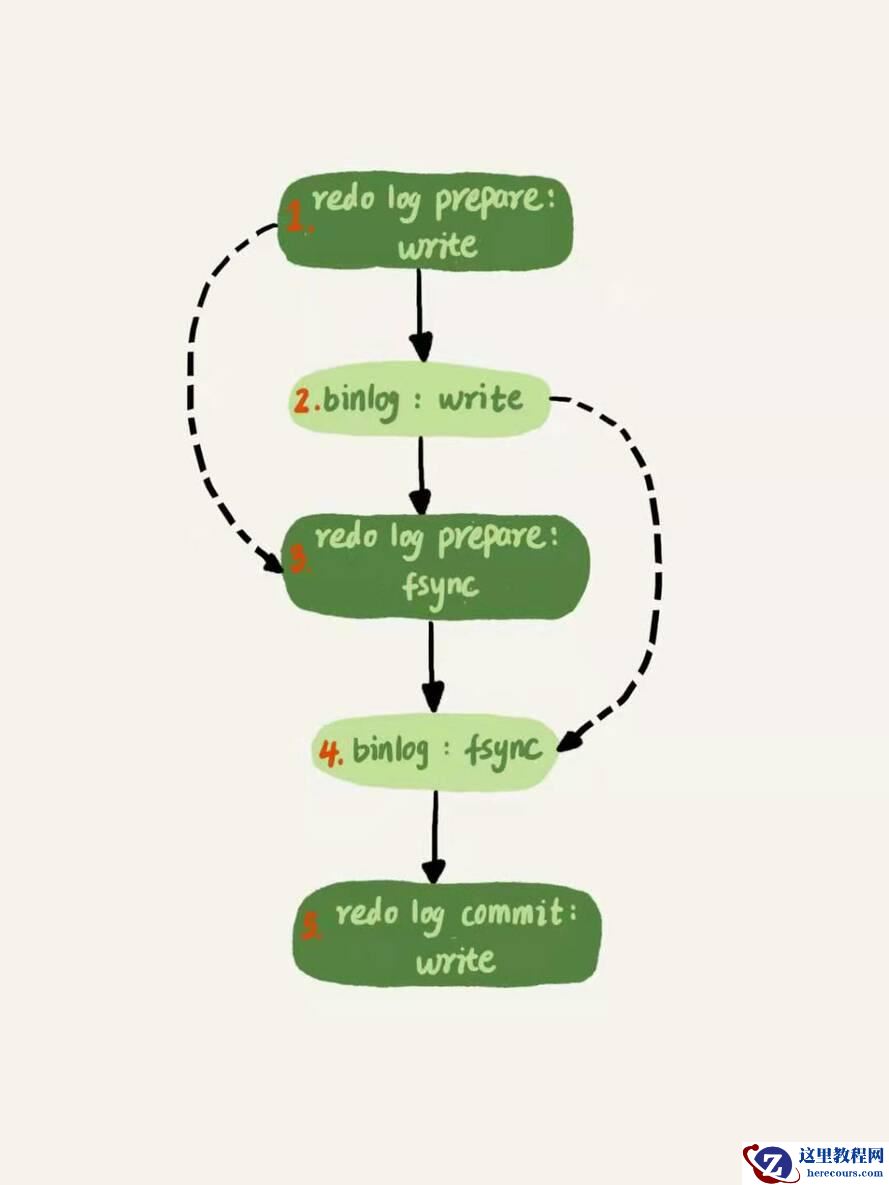
1)redo prepare write (page cache)
2)binlog write (page cache)
3)redo log fsync 到磁盘
4)binlog fsync 到磁盘
5)redo commit write
我们先来看一下崩溃恢复时的判断规则。 ----实战45讲的15讲
如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整:
a. 如果是,则提交事务;
b. 否则,回滚事务。
MySQL 怎么知道 binlog 是完整的?
一个事务的 binlog 是有完整格式的:
statement 格式的 binlog,最后会有 COMMIT;
row 格式的 binlog,最后会有一个 XID event。
另外,在 MySQL 5.6.2 版本以后,还引入了 binlog-checksum 参数,用来验证 binlog 内容的正确性。对于 binlog 日志由于磁盘原因,可能会在日志中间出错的情况,MySQL 可以通过校验 checksum 的结果来发现。所以,MySQL 还是有办法验证事务 binlog 的完整性的。
redo log 和 binlog 是怎么关联起来的?------xid的存在的意义
它们有一个共同的数据字段,叫 XID。崩溃恢复的时候,会按顺序扫描 redo log:
如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;
如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务。
二:关于mysql trx_id
Xid 和 InnoDB 的 trx_id 是两个容易混淆的概念。
Xid 是由 server 层维护的。InnoDB 内部使用 Xid,就是为了能够在 InnoDB 事务和 server 之间做关联。但是,InnoDB 自己的 trx_id,是另外维护的。
InnoDB 内部维护了一个 max_trx_id 全局变量,每次需要申请一个新的 trx_id 时,就获得 max_trx_id 的当前值,然后并将 max_trx_id 加 1。
InnoDB 数据可见性的核心思想是:每一行数据都记录了更新它的 trx_id,当一个事务读到一行数据的时候,判断这个数据是否可见的方法,就是通过事务的一致性视图与这行数据的 trx_id 做对比。
对于正在执行的事务,你可以从 information_schema.innodb_trx 表中看到事务的 trx_id。
我在上一篇文章的末尾留给你的思考题,就是关于从 innodb_trx 表里面查到的 trx_id 的。现在,我们一起来看一个事务现场:


图 3 事务的 trx_id
session B 里,我从 innodb_trx 表里查出的这两个字段,第二个字段 trx_mysql_thread_id 就是线程 id。显示线程 id,是为了说明这两次查询看到的事务对应的线程 id 都是 5,也就是 session A 所在的线程。
可以看到,T2 时刻显示的 trx_id 是一个很大的数;T4 时刻显示的 trx_id 是 1289,看上去是一个比较正常的数字。这是什么原因呢?
实际上,在 T1 时刻,session A 还没有涉及到更新,是一个只读事务。而对于只读事务,InnoDB 并不会分配 trx_id。也就是说:
在 T1 时刻,trx_id 的值其实就是 0。而这个很大的数,只是显示用的。一会儿我会再和你说说这个数据的生成逻辑。
直到 session A 在 T3 时刻执行 insert 语句的时候,InnoDB 才真正分配了 trx_id。所以,T4 时刻,session B 查到的这个 trx_id 的值就是 1289。
需要注意的是,除了显而易见的修改类语句外,如果在 select 语句后面加上 for update,这个事务也不是只读事务。
在上一篇文章的评论区,有同学提出,实验的时候发现不止加 1。这是因为:
update 和 delete 语句除了事务本身,还涉及到标记删除旧数据,也就是要把数据放到 purge 队列里等待后续物理删除,这个操作也会把 max_trx_id+1, 因此在一个事务中至少加 2;
InnoDB 的后台操作,比如表的索引信息统计这类操作,也是会启动内部事务的,因此你可能看到,trx_id 值并不是按照加 1 递增的。
那么,T2 时刻查到的这个很大的数字是怎么来的呢?
其实,这个数字是每次查询的时候由系统临时计算出来的。它的算法是:把当前事务的 trx 变量的指针地址转成整数,再加上 248。使用这个算法,就可以保证以下两点:
因为同一个只读事务在执行期间,它的指针地址是不会变的,所以不论是在 innodb_trx 还是在 innodb_locks 表里,同一个只读事务查出来的 trx_id 就会是一样的。
如果有并行的多个只读事务,每个事务的 trx 变量的指针地址肯定不同。这样,不同的并发只读事务,查出来的 trx_id 就是不同的。
那么,为什么还要再加上 2的48次方呢?
在显示值里面加上 248,目的是要保证只读事务显示的 trx_id 值比较大,正常情况下就会区别于读写事务的 id。但是,trx_id 跟 row_id 的逻辑类似,定义长度也是 8 个字节。
因此,在理论上还是可能出现一个读写事务与一个只读事务显示的 trx_id 相同的情况。不过这个概率很低,并且也没有什么实质危害,可以不管它。
另一个问题是,只读事务不分配 trx_id,有什么好处呢?
一个好处是,这样做可以减小事务视图里面活跃事务数组的大小。因为当前正在运行的只读事务,是不影响数据的可见性判断的。所以,在创建事务的一致性视图时,InnoDB 就只需要拷贝读写事务的 trx_id。
另一个好处是,可以减少 trx_id 的申请次数。在 InnoDB 里,即使你只是执行一个普通的 select 语句,在执行过程中,也是要对应一个只读事务的。所以只读事务优化后,普通的查询语句不需要申请 trx_id,就大大减少了并发事务申请 trx_id 的锁冲突。
由于只读事务不分配 trx_id,一个自然而然的结果就是 trx_id 的增加速度变慢了。
但是,max_trx_id 会持久化存储,重启也不会重置为 0,那么从理论上讲,只要一个 MySQL 服务跑得足够久,就可能出现 max_trx_id 达到 248-1 的上限,然后从 0 开始的情况。
当达到这个状态后,MySQL 就会持续出现一个脏读的 bug,我们来复现一下这个 bug。
首先我们需要把当前的 max_trx_id 先修改成 248-1。注意:这个 case 里使用的是可重复读隔离级别。具体的操作流程如下:


图 4 复现脏读
由于我们已经把系统的 max_trx_id 设置成了 2的48次方-1,所以在 session A 启动的事务 TA 的低水位就是 2的48次方-1。
在 T2 时刻,session B 执行第一条 update 语句的事务 id 就是 2的48次方-1,而第二条 update 语句的事务 id 就是 0 了,这条 update 语句执行后生成的数据版本上的 trx_id 就是 0。
在 T3 时刻,session A 执行 select 语句的时候,判断可见性发现,c=3 这个数据版本的 trx_id,小于事务 TA 的低水位,因此认为这个数据可见。
但,这个是脏读。
由于低水位值会持续增加,而事务 id 从 0 开始计数,就导致了系统在这个时刻之后,所有的查询都会出现脏读的。
并且,MySQL 重启时 max_trx_id 也不会清 0,也就是说重启 MySQL,这个 bug 仍然存在。
那么,这个 bug 也是只存在于理论上吗?
假设一个 MySQL 实例的 TPS 是每秒 50 万,持续这个压力的话,在 17.8 年后,就会出现这个情况。如果 TPS 更高,这个年限自然也就更短了。但是,从 MySQL 的真正开始流行到现在,恐怕都还没有实例跑到过这个上限。不过,这个 bug 是只要 MySQL 实例服务时间够长,就会必然出现的。
编辑推荐:
- mysql XID和trx_id小结03-01
- 14.5.4 Log Buffer03-01
- mysql多版本实例安装03-01
- load语句在binlog中的记录方式03-01
- MySQL rename table方法大全03-01
- 致同:为客户提供全方位专业服务03-01
- 测试03-01
- 带你看懂MySQL执行计划03-01
下一篇:
相关推荐
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-

雷神推出 MIX PRO II 迷你主机:基于 Ultra 200H,玻璃上盖 + ARGB 灯效
2 月 9 日消息,雷神 (THUNDEROBOT) 现已宣布推出基于英
-

制造商 Musnap 推出彩色墨水屏电纸书 Ocean C:支持手写笔、第三方安卓应用
2 月 10 日消息,制造商 Musnap 现已在海外推出一款 Oce
热文推荐
- mysql XID和trx_id小结

mysql XID和trx_id小结
26-03-01 - load语句在binlog中的记录方式

load语句在binlog中的记录方式
26-03-01 - 令人咋舌的隐式转换
令人咋舌的隐式转换
26-03-01 - 集成电路行业ERP管理系统的三大分类

集成电路行业ERP管理系统的三大分类
26-03-01 - centos7 编译安装mysql 5.7.28图文详细教程

centos7 编译安装mysql 5.7.28图文详细教程
26-03-01 - 谈谈MYSQL索引是如何提高查询效率的

谈谈MYSQL索引是如何提高查询效率的
26-03-01 - 部署otter实现mysql主备数据同步(下)
")
部署otter实现mysql主备数据同步(下)
26-03-01 - MySQL不区分大小写设置

MySQL不区分大小写设置
26-03-01 - Navicat连接MySQL Server8.0版Client does not support authentication protocol req
- 部署otter实现mysql主备数据同步(上)
")
部署otter实现mysql主备数据同步(上)
26-03-01
