自己原文公众号: https://mp.weixin.qq.com/s/3mgeT93lP-PGCea0oZFDNA
如果要做分析大家第一想到的是大数据。还想到了Oracle MySQL PG不行。我听过不少人说,出报表去大数据啊。这个也不能说错,但是请问报表多大?如果就是几万条数据一个excel轻松搞定。为什么需要大数据?
分析做的好的都是列式数据库。行式数据库在交易场景是必须的,在分析场景下,无用功多了,显得有点慢。
但是那是说在数据量巨大(请注意何为巨大)我认为1000万一下都是常规得到。10亿以上再说大也不迟。
拿数据说话1000万的一个表,硬查也就7秒左右(我这个列少,列数多会慢,如果有几十列可能会20-30秒)如下图红框。(练习虚拟机,低配未优化)
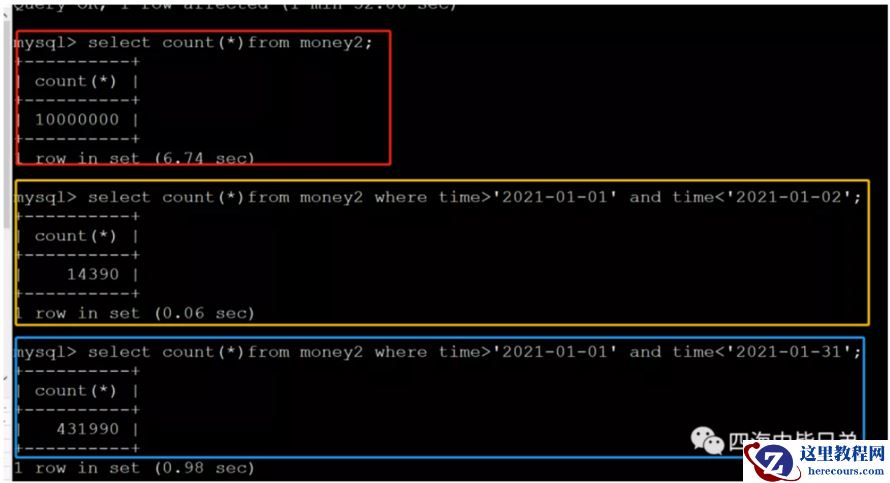
黄色框才是日常可能发生的聚合 count sum avg 等等。一天60毫秒。
蓝色框才是业务常用的一个月度的小报表,1秒。
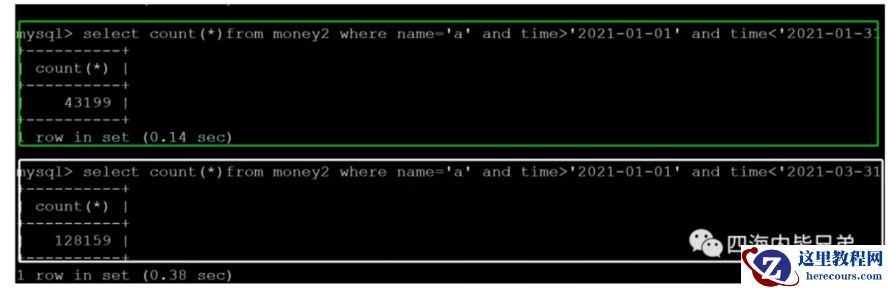
绿色框更加常见,某个用户的一个月的数据。140毫秒。
白色框,是某个用户的三个月的数据。380毫秒。
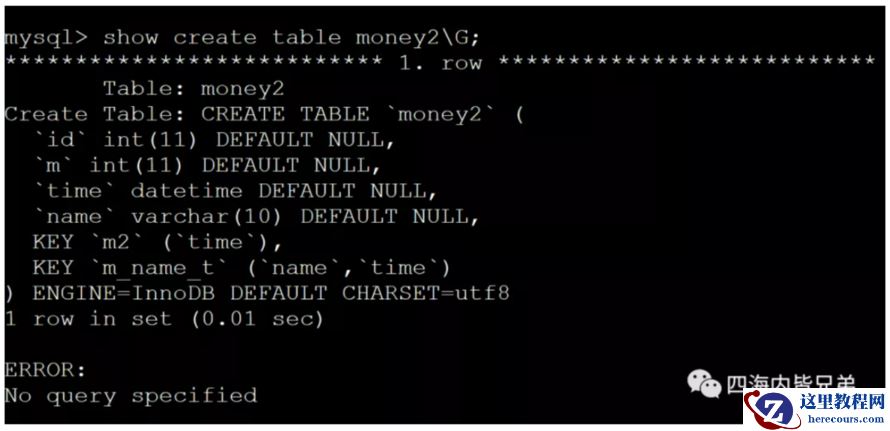
表结构如下:
可见在1000万级别下,使用索引查询。最慢的不超过1秒。(PG和Oracle 同样下不得不说比MySQL还要快一点)
如果说用大数据去查,数据同步都不止这个时间。别说MapReduce的时间了。还有数据预热和加载。
其实很多时候我们本地就能好好的完成任务了。
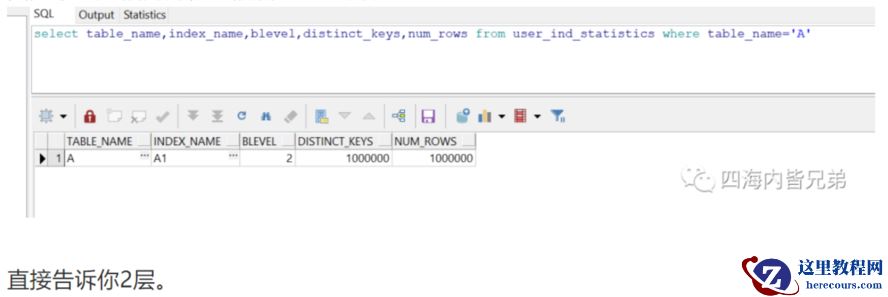
这是因为我们索引一共才3层。三次IO就行了。一次IO 5-10ms。所以说根本不可能慢。
select b.name,a.name,index_id,type,a.space,a.page_no from information_schema.innodb_sys_indexes a, information_schema.innodb_sys_tables b where a.table_id=b.table_id and a.space<>0 and b.name like '%money2%';
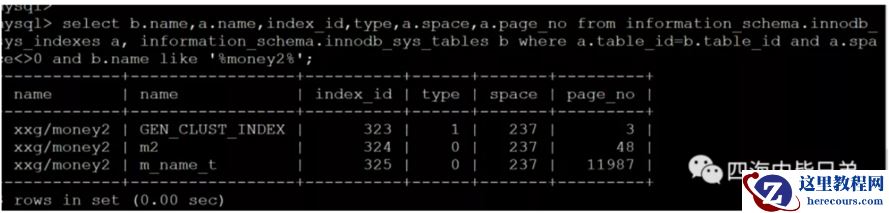


指定的偏移量的计算公式是page_no * innodb_page_size + 64。
49216 = 3 * 16384 +64 上面的49216是这么来的。
这里的0200是16进制。看着有点费劲是吧?
因为原理是相同的,直接看Oracle的。










mysql初体验篇")

