这可咋办呢?索引也优化了,连接池也用上了,Redis缓存命中率也符合预期。然而,所有的请求都集中在一台主MySQL上,压测的时候,还是挺吃力的,那就来试试读写分离吧。
一. 主从复制逻辑
数据库一主多从,是很经典的结构,对于数据库的容灾、可扩展性和高可用性,都是有好处的。一主多从,依赖于主从复制,下面是主从复制的逻辑图,一起来看看:
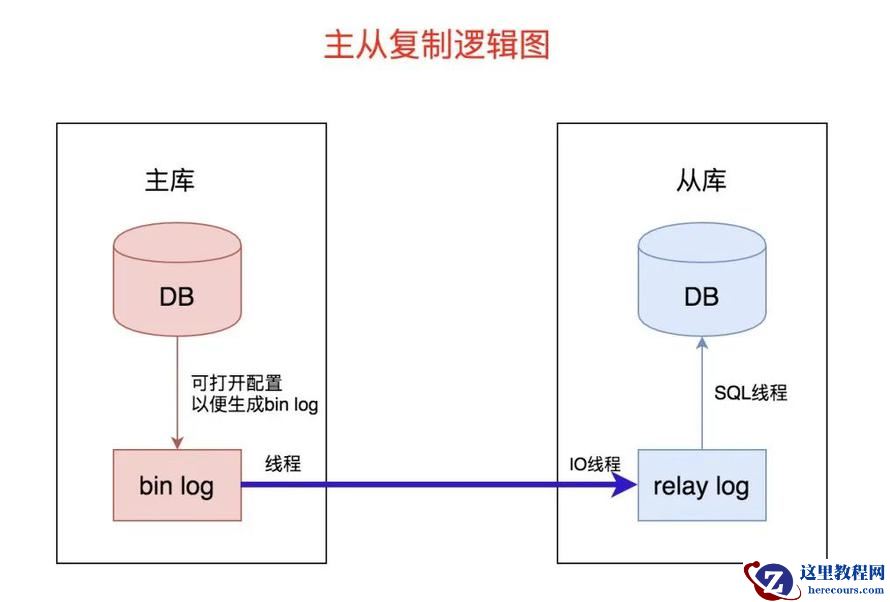
主从复制后,就可以开心地进行读写分离了。具体来说就是,让所有的写请求调度到主库,让大量读请求调度到从库。读写分离的逻辑图如下,非常直观且易懂:
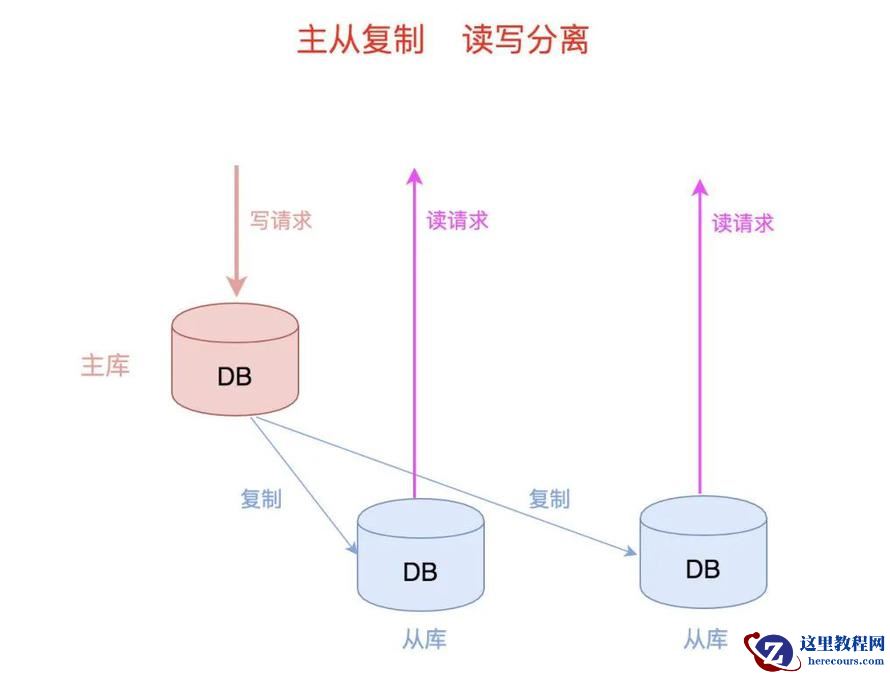
二. 读写分离效果
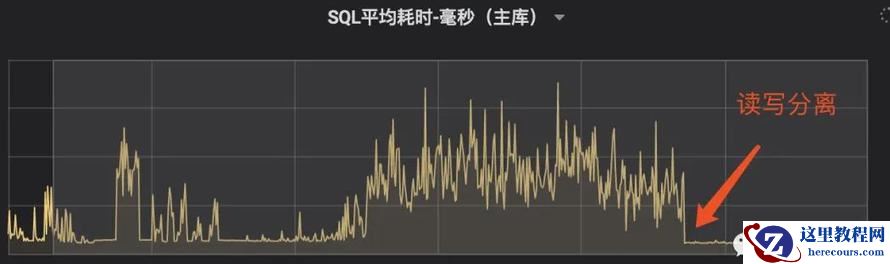
而且,实际也发现,调读到从库上后,大量读请求的耗时也有下降。自然地,主库上的写请求的性能也提升了近100%。读写分离的好处,可见一斑。爽爽哒!
对于应用服务来说,也可做读写分离。比如某服务提供读和写的接口,主调方可做读写分离,这样就能针对读和写进行不同的伸缩策略,提升了扩展的弹性。












