来源:PostgreSQL学徒
序言
2022 年 11 月 30 日,OpenAI 推出了全新的对话式通用人工智能工具——ChatGPT,ChatGPT 表现出了非常惊艳的语言理解、生成、知识推理能力,ChatGPT 的横空出世拉开了大语言模型产业和生成式 AI 产业蓬勃发展的序幕,大模型作为新一代的 AI 处理器,提供了数据处理能力;而向量数据库提供了存储能力,成为大模型时代的重要基座。向量数据库因为可以为大模型提供记忆而需求倍增,随着 AI 的热潮开始崭露头角,本文也聚焦于被 AI 炒火了的向量数据库,介绍什么是向量数据库,以及以插件形式存在的 pgvector,与 PostgreSQL 强强联合,成为 AI 浪潮下的崛起新星。
前置知识
向量
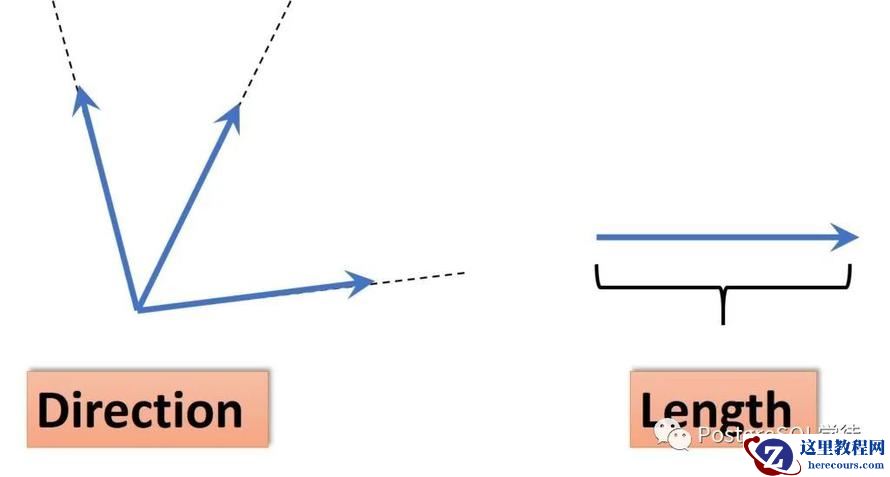
在数学中,向量是有大小和方向的量,可以使用带箭头的线段表示,箭头指向即为向量的方向,线段的长度表示向量的大小。两个向量的距离或者相似性可以通过欧式距离、余弦距离等得到。
向量数据
在提及向量数据之前,我们先思考一个问题,为什么我们可以在生活中区分不同的物品和事物?比如看到一个动物,我们可以分辨出是猫还是狗,看到一个人可以分辨其是女性还是男性。如果从理论角度出发,这是因为我们会通过识别不同事物之间不同的特征来识别种类,例如分别不同种类的小狗,就可以通过体型大小、毛发长度、鼻子长短等特征来区分。

上面这张照片如果按照体型排序,可以看到体型越大的狗越靠近坐标轴右边,这样就能得到一个体型特征的一维坐标和对应的数值,从 0 到 1 的数字中得到每只狗在坐标系中的位置。

然而单靠一个体型大小的特征并不够,像照片中哈士奇、金毛和拉布拉多的体型就非常接近,我们无法区分。

所以我们会继续观察其它的特征,例如毛发的长短。所以我们再建立一个坐标轴,每只狗对应一个二维坐标点,我们就能轻易的将哈士奇、金毛和拉布拉多区分开来,但是这时你会发现仍然无法很好的区分德牧和罗威纳犬。

我们就可以继续再从其它的特征区分,比如鼻子的长短,这样就能得到一个三维的坐标系和每只狗在三维坐标系中的位置。在这种情况下,只要特征足够多 (比如眼睛的大小,毛发的颜色,甚至一些抽象性的特征比如攻击性、服从性等等),就能够将所有的狗区分开来,最后就能得到一个高维的坐标系,虽然我们想象不出高维坐标系长什么样,但是在数组中,我们只需要一直向数组中追加数字就可以了,这个就是向量的维度。

实际上,只要维度够多,我们就能够将所有的事物区分开来,世间万物都可以用一个多维坐标系来表示,它们都在一个高维的特征空间中对应着一个坐标点。
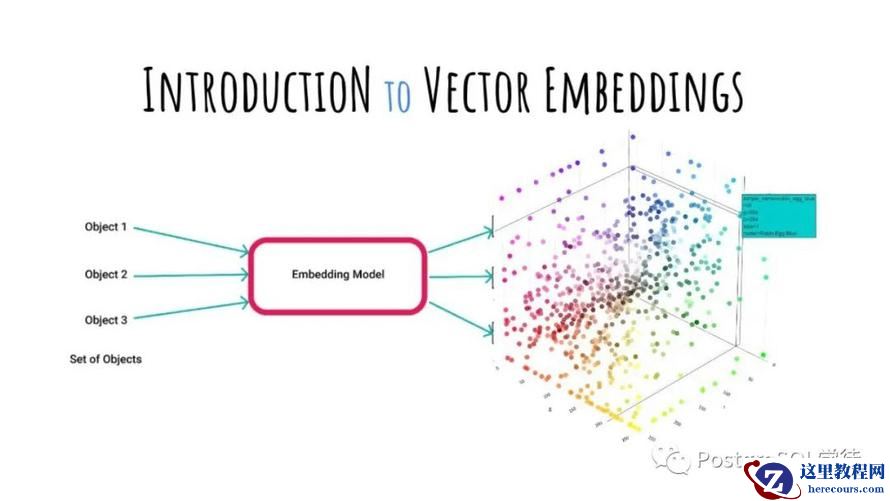
简而言之,向量表示是一种将非结构化的数据转换为嵌入向量的技术,通过多维度向量数值表述某个对象或事物的属性或者特征。通过嵌入技术,任何图像、声音、文本都可以被表达为一个高维的向量。
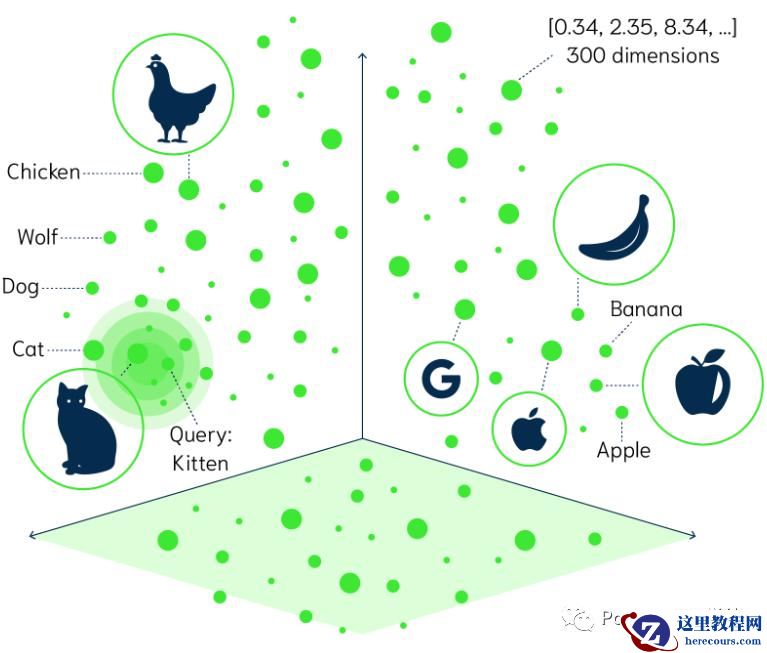
通过向量,那些概念上更为接近的点在空间中更为聚集 (不妨通俗地理解成我们常说的——物理类聚,人以群分),而那些概念相差甚远的点,在坐标系里的距离也就相距很远。比如鸡 (chicken) 和猫 (cat) 都属于动物,所以在坐标系里的距离相近,而与香蕉 (banana) 相距甚远。
通过向量这样的表达方式,甚至让我们有了一定的推理能力,比如警察减去小偷的向量和猫减去老鼠的向量相似,那么这也意味二者的关系也类似 (猫抓老鼠、警察抓小偷)。贴近我们生活的案例比如平安城市,公安会把类似的作案手法的案发现场的周边的人脸做对比,看看有哪些人在多个案发现场同时出现过,作为重点嫌疑人进行排查。
我们都知道向量是具有大小和方向的数学结构,所以可以将这些特征用向量来表示,这样就能够通过计算向量之间的距离来判断它们的相似度,这就是相似性搜索。
向量检索
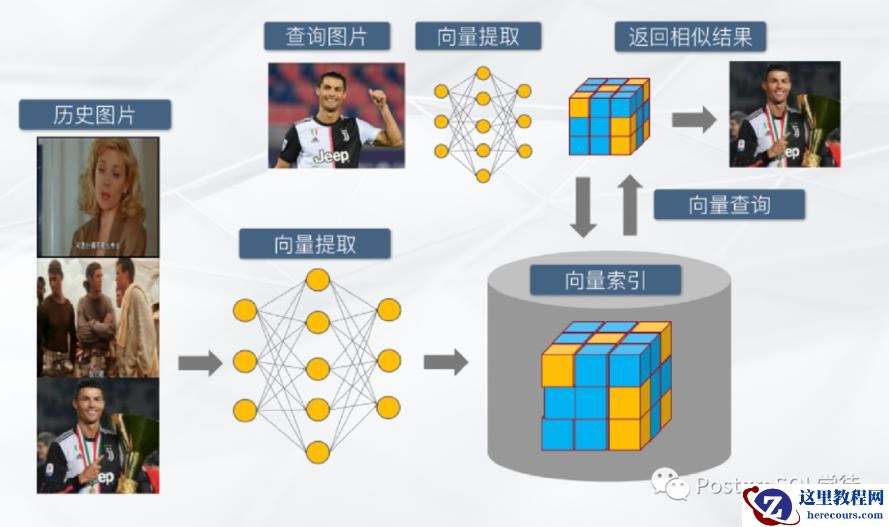
有了向量,另外一个问题便是如何检索了——向量检索是将向量与数据库进行比较以查找与查询向量最相似的向量的过程。相似的向量通常具有相近的原始数据,通过向量检索可以挖掘出原始非结构化数据之间的联系。例如在图像向量数据库中,用户输入一张图片进行搜索时,先将这张图片转换为一个向量,通过向量之间的近似检索,找到与输入图片最相似的图片,这便是我们经常用到的搜图功能。
向量数据库
但是仅有向量检索就行了吗?比如过滤、索引、10 分钟内导入 10 亿数据、数据删除更新、多副本、资源隔离、易用的查询能力 (Restful,Python,SQL) 数据备份、监控、报警、流控、API & SDK、是否支持分布式横向扩展以满足大规模数据的查询和存储等等,这些场景该需要如何解决?以上便是向量数据库需要做的。
TL,NR
“向量数据库让大模型有了"记忆"的功能,在初始的 LLM 中,世界知识和语义理解被压缩为静态参数,模型不会随着交互记住用户的聊天记录和喜好,也无法调用额外知识信息来辅助判断,因此模型只能根据历史训练数据回答问题,并且经常产生幻觉,给出与事实相悖的答案。所谓的记忆功能只是开发者将对话记录存储在内存或者数据库中,当你发送消息给 gpt 模型时,程序会自动将最近的几次对话记录(基于对话的字数限制在 4096 tokens 内)通过 prompt 组合成最终的问题,并发送给 ChatGPT。简而言之,如果你的对话记忆超过了 4096 tokens,那么它就会忘记之前的对话,这就是目前 GPT 在需求比较复杂的任务中无法克服的缺陷。目前,不同模型对于 token 的限制也不同,gpt-4 是 32K tokens 的限制,而目前最大的 token 限制是 Claude 模型的 100K,这意味可以输入大约 75000 字的上下文给 GPT,这也意味着 GPT 直接理解一部《哈利波特》的所有内容并回答相关问题。但这样就能解决我们所有的问题了吗?答案是否定的,首先 Claude 给出的例子是 GPT 处理 72K tokens 上下文的响应速度是 22 秒。如果我们拥有 GB 级别或更大的文档需要进行 GPT 理解和问答,目前的算力很难带来良好体验,更关键的是目前 GPT API 的价格是按照 tokens 来收费的,所以输入的上下文越多,其价格越按昂贵。这种情况有点类似于早期开发者面对内存只有几 MB 甚至几 KB 时期开发应用的窘境,一是内存昂贵,二是内存太小,所以在 GPT 模型在性能、成本、注意力机制等方面有重大革命性进展前,开发者不得不面对的绕过 GPT tokens 限制的难题。当模型需要记忆大量的聊天记录或行业知识库时,可将其储存在向量数据库中,后续在提问时将问题向量化,送入向量数据库中匹配相似的语料作为 prompt,向量数据库通过提供记忆能力使 prompt 更精简和精准,从而使返回结果更精准。
如果说 LLM 是容易失忆的大脑,向量数据库就是海马体,记忆的缺失让每一次和 LLM 的交互像是一次次不断重头再来的闭卷考。而向量数据库的存在让这一过程能变成开卷考:一方面,LLM 能浏览专用数据与知识,解决 Hallucination 的问题使回答更精准;另一方面,LLM 能回忆自己过往的经验与历史,更了解用户的需求,通过反思实现更好的个性化。
因此,向量数据库是一种专门用于存储和查询向量数据的数据库系统,与传统数据库相比,向量数据库使用向量化计算,能够高速地处理大规模的复杂数据;并可以处理高维数据,例如图像、音频和视频等,解决传统关系型数据库中的痛点;同时,向量数据库支持复杂的查询操作,也可以轻松地扩展到多个节点,以处理更大规模的数据。
向量数据库的主要技术
向量嵌入
前面已经介绍过,AI 模型实际识别和理解的不是一个个具体的文字符号,而是对各类数据的向量化表示,巧妙地转化为一个数学问题。利用嵌入技术将高维度的数据 (例如文字、图片、音频) 映射到低维度空间,即把图片、声音和文字转化为向量来表示,将这些向量存储在向量数据库中。对于传统数据库,搜索功能都是基于特定的扫描方式加上匹配过滤等算法实现的 (精准搜索) ,对于关键字的搜索功能非常合适,但对于语义搜索功能就非常弱。
例如,如果你搜索"小狗",那么你只能得到带有"小狗"关键字相关的结果,而无法得到"柯基"、"金毛等结果,因为"小狗"和"金毛"是不同的词,传统数据库无法识别它们的语义关系,所以传统的应用需要人为的将"小狗"和"金毛""等词之间打上特征标签进行关联,这样才能实现语义搜索。
但是如果你需要处理非结构化的数据,就会发现非结构化数据的特征数量会开始快速膨胀,例如我们处理的是图像、音频、视频等数据,这个过程就变得非常困难。例如,对于图像,可以标注颜色、形状、纹理、边缘、对象、场景等特征,对于视频,你可以标注大小、清晰度、类别、方向等,这些特征太多了,而且很难人为的进行标注,所以我们需要一种自动化的方式来提取这些特征,而这可以通过向量嵌入 (Vector Embedding) 来实现。Vector Embedding 是由 AI 模型 (例如大型语言模型 LLM等) 生成的
AI 模型会根据不同的算法生成高维度的向量数据,代表着数据的不同特征,这些特征代表了数据的不同维度。例如,对于文本,这些特征可能包括词汇、语法、语义、情感、情绪、主题、上下文等。对于音频,这些特征可能包括音调、节奏、音高、音色、音量、语音、音乐等。
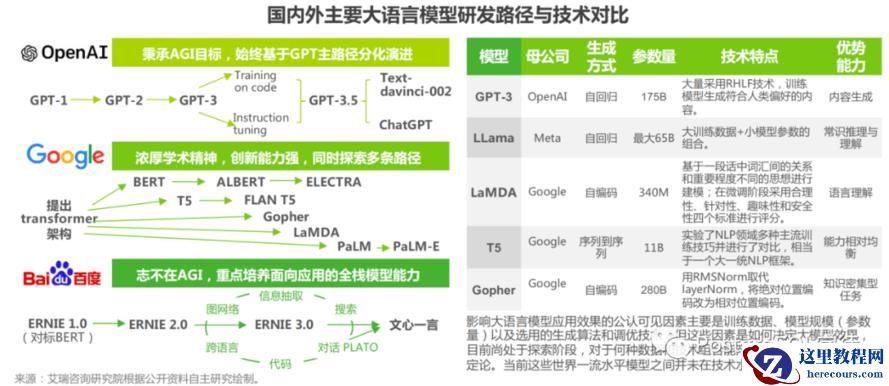
"大"模型,就是模型中比较"大"的那一类,大的具体含义也就是数学公式更复杂,它的参数更多。这些模型通常在训练过程中需要大量的数据和计算能力,并且具有数百万到数十亿个参数。大模型的设计目的是为了提高模型的表示能力和性能,在处理复杂任务时能够更好地捕捉数据中的模式和规律。大模型的典型例子是深度神经网络中的巨大模型,如 GPT-3、BERT 和 AlphaGo Zero。现在比较热门的五款大语言模型,比如OpenAI 的 Chatgpt、百度的文心一言、阿里的通义千问、微软的 newbing 和 谷歌的 Bard。
向量检索
既然我们知道了可以通过比较向量之间的距离来判断它们的相似度,那么如何将它应用到真实的场景中呢?如果想要在一个海量的数据中找到和某个向量最相似的向量,我们需要对数据库中的每个向量进行一次比较计算,但这样的计算量是非常巨大的,所以我们需要一种高效的算法来解决这个问题。
最简单暴力的方式是平坦搜索 Flat search (类似传统关系型数据库的顺序扫描) ,即不采用任何算法进行索引,遍历数据库中所有的数据, 依次比较所有向量和查询向量的相似度,之后按照相似度倒序返回 topN 条。这种方式一般也称着暴力检索,召回率和准确率都是最高的,但是在数据量大的情况下遍历计算相似度是非常耗时的,需要一些策略算法进行优化,在召回率,内存占用和响应时间之间权衡。
比较两个向量相似的方法有很多,常见的有:
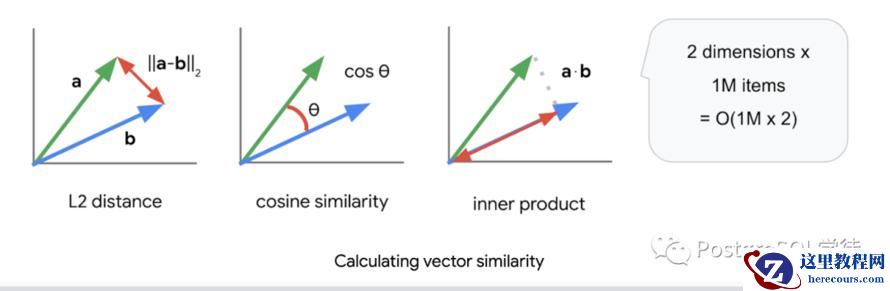
但是前面也说了,这种暴力毫无技术含量的搜索方式将导致极高的搜索时间,对于小规模的数据还可以适用,但是这种方式有其自己独到的好处:搜索质量是完美的,因为它会和所有的向量挨个依次比较。对于成千上万的向量,这种方式无疑是无法接受的,所以,必须找出一些方式进行优化:
高效的搜索算法有很多,其主要思想是通过两种方式提高搜索效率:
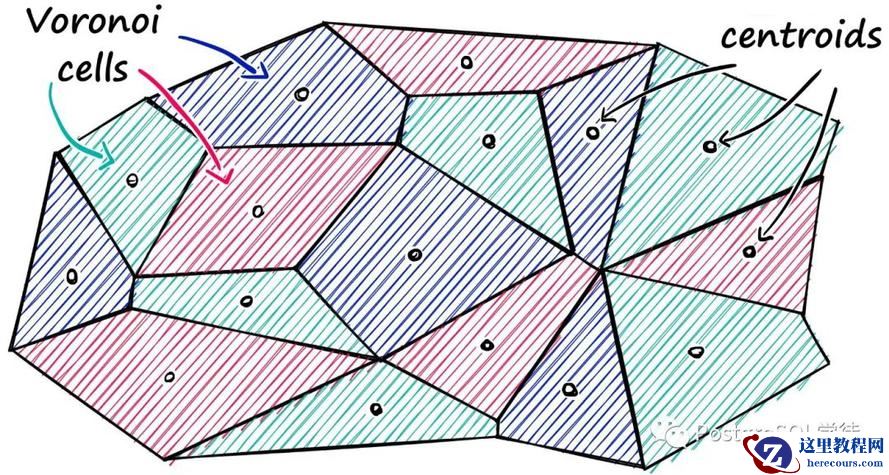
向量聚类
向量聚类指根据给定的相似度度量,将数据库中的向量分类,举个例子——找人,比如我现在要在 A 城市找这个人

最粗暴的方式当然是根据公安人口信息按个比较,但是这种方式会耗费海量的时间。那么聚类的思想就是先进行特征提取,进行归类划分,比如这个人胸前带有红领巾,判断他来自小学,于是将搜索范围先缩小到这个城市的所有小学,这便是聚类。以 K-Means 为例,它将数据分成 k 个类别,其中 k 是预先指定的。以下是 k-means 算法的基本步骤:

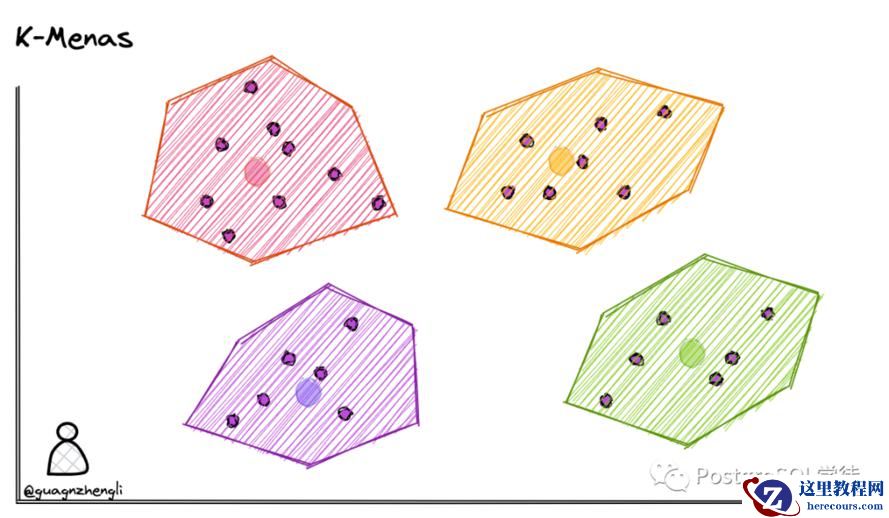
这样我们在搜索向量的时候只需要查找距离向量最近的那个聚类中心即可。
但是这种搜索方式也有一些缺点,例如在搜索的时候,如果搜索的内容正好处于两个分类区域的中间,就很有可能遗漏掉最相似的向量。我们可以通过增加聚类数量,同时指定搜索多个聚类中心来缩小这种误差,但是这又势必会影响到搜索的速度,所以搜索质量和搜索速度往往是难以调和的矛盾。
所以除了暴力的平坦式搜索,所有的搜索算法只能得到一个近似的搜索结果, 所以这些算法被称作为——ANN (Approximate Nearest Neighbor),近似最近邻搜索。
LSH 位置敏感哈希
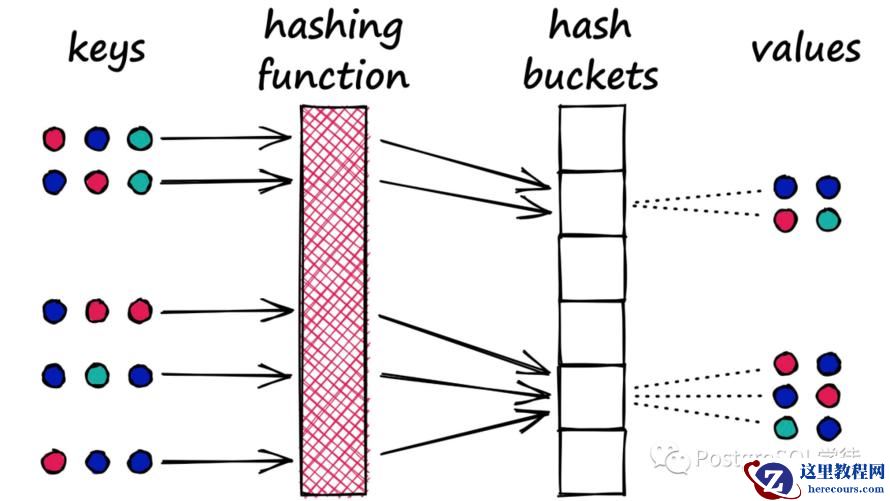
除了向量聚类之外,还有一种——位置敏感哈希 (Locality-Sensitive Hashing),这种哈希方式反其道而行之,力求增大"碰撞"的概率,这样的话哈希值一样的向量就被分到了一个 bucket 中,越相似的向量发生"碰撞"的概率就越高,通过这种方式找到相似的向量。
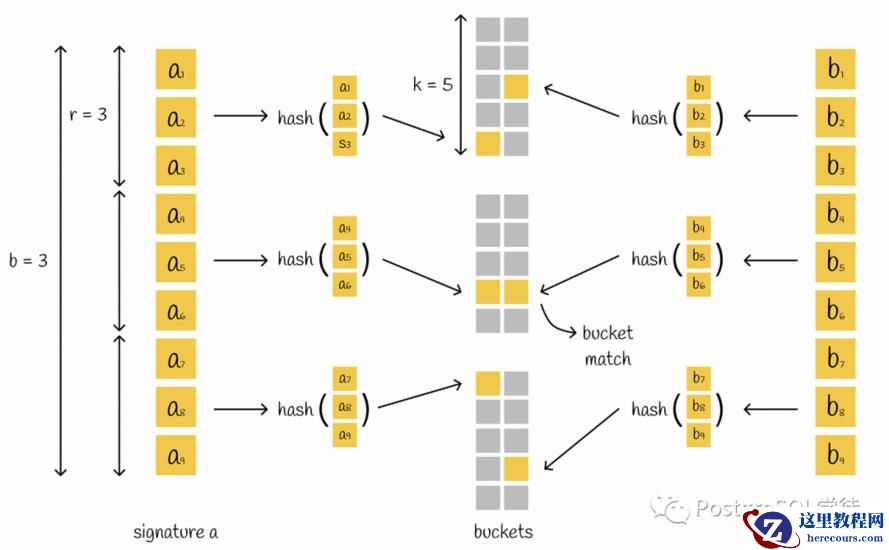
Product Quantization (PQ)
在大规模数据集中,聚类算法最大的问题在于内存占用太大。这主要体现在两个方面,首先因为需要保存每个向量的坐标,而每个坐标都是一个浮点数,占用的内存就已经非常大了。除此之外,还需要维护聚类中心和每个向量的聚类中心索引,这也会占用大量的内存。
乘积量化——Product Quantization (PQ),意思是指把原来的向量空间分解为若干个低维向量空间的笛卡尔积,并对分解得到的低维向量空间分别做量化(quantization)。这样每个向量就能由多个低维空间的量化code组合表示。PQ 先将 D 维空间切分成 M 份,现在考虑一个 D=128 维的原始向量,它被切分成了 M=8 个 D=16 维的短向量。
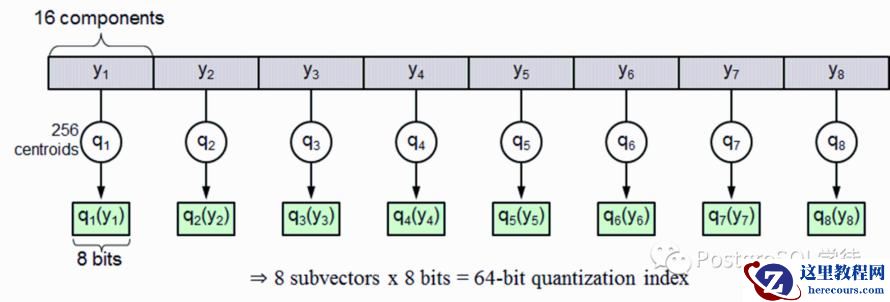
同时每个短向量都对应一个量化的索引值,索引值即该短向量距离最近的聚类中心的编号,每一个原始向量就可以压缩成 M 个索引值构成的压缩向量,只要设计好了数据结构,就可以获得所有 1M 数据的压缩向量。压缩向量其实就是 M 个索引值,每个索引值对应一个聚类中心,所以要同时保存压缩向量和聚类中心,下图中的矩阵为压缩后的向量。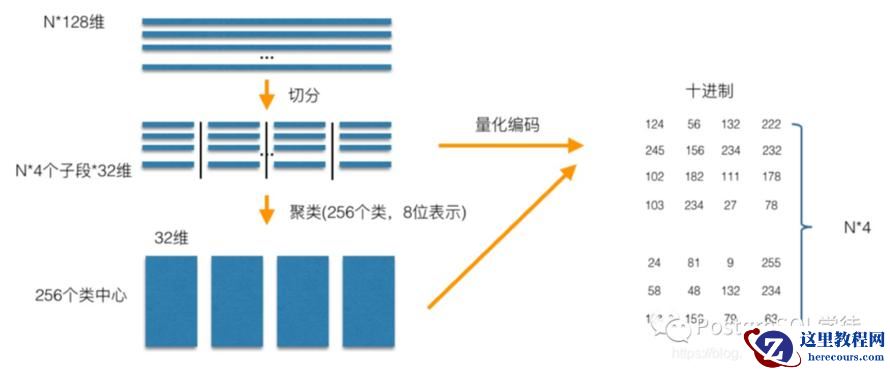
Navigable Small Worlds (NSW)
除了聚类以外,也可以通过构建树或者构建图的方式来实现近似最近邻搜索。NSW 的基本思想是每次将向量加到数据库中的时候,就先找到与它最相邻的向量,然后将它们连接起来,这样就构成了一个图。当需要搜索的时候,就可以从图中的某个节点开始,不断的进行最相邻搜索和最短路径计算,直到找到最相似的向量。这里必须要提一下六度分隔 (Six Degrees of Separation) 理论。简单地说:"你和任何一个陌生人之间所间隔的人不会超六个,也就是说,最多通过六个人你就能够认识任何一个陌生人。" 1967年,哈佛大学的心理学教授 Stanley Milgram (1933~1984) 想要描绘一个连结人与社区的人际连系网,NSW 与六度分隔理论异曲同工
让我们把人看做是向量点,把搜索看做是某个人人去找另外一个人的过程
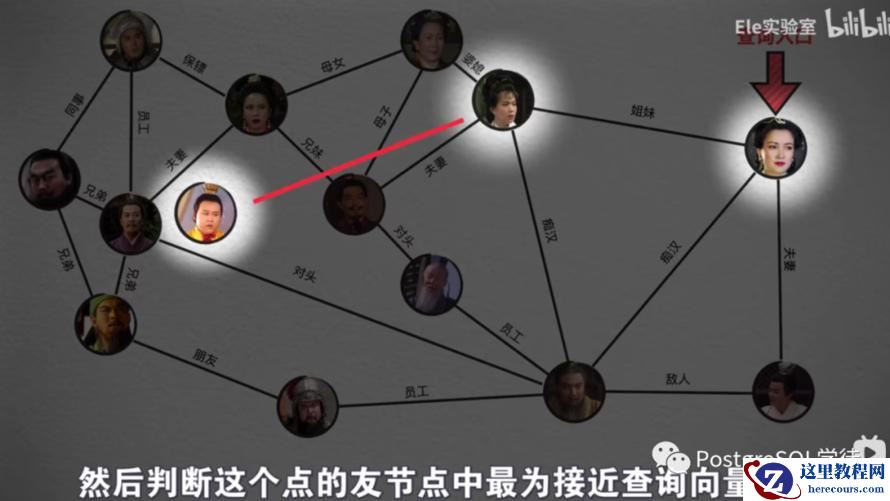
搜索算法随机从某个点开始,查找最为接近的向量点,如此反复递归,直到搜索到一个所有友节点都没有自己距离目标近的点,便完成了搜索,这便是 NSW (Navigable Small World),这个算法还有个有趣的名字——导航小世界。
Hierarchical Navigable Small Worlds (HNSW)
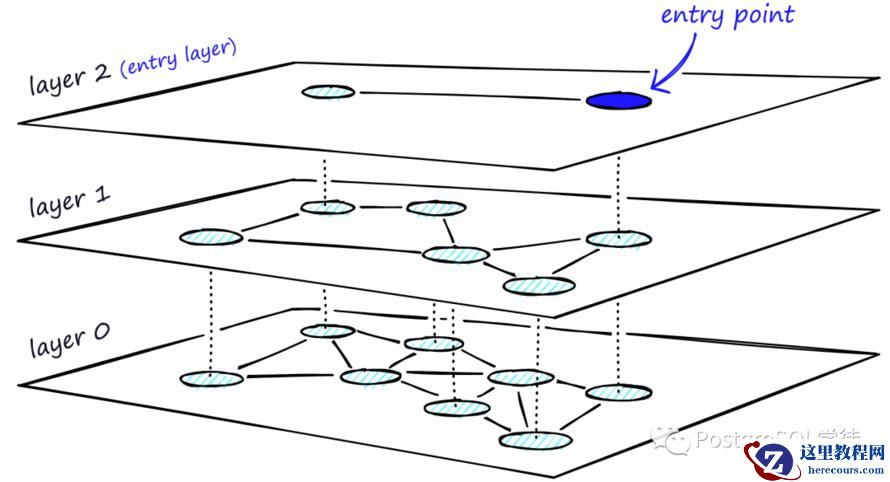
HNSW (Hierarchical Navigating Small World) 是一种基于图的索引算法,也是对 NSW 方法的改进,它由多层的邻近图组成,因此称为分层的 NSW 方法。它会为一张图按规则建成多层导航图,并让越上层的图越稀疏,结点间的距离越远;越下层的图越稠密,结点间的距离越近。HNSW 算法是一种经典的空间换时间的算法,它的搜索质量和搜索速度都比较高,但是它的内存开销也比较大,因为不仅需要将所有的向量都存储在内存中。还需要维护一个图的结构,也同样需要存储。所以这类算法需要根据实际的场景来选择。
KD-tree
基于树的结构进行快速检索的主要思想是通过对 K 维空间进行多次划分,类似二叉树搜索。优点是简单易实现,缺点是不适合高维度向量场景。
KD-tree 是 K-dimension tree 的缩写,是对数据点在 k 维空间如二维 (x,y),三维 (x,y,z),k维 (x,y,z..)中划分的一种数据结构,就是把整个空间划分为特定的几个部分,然后在特定空间的部分内进行相关搜索操作。每次切分点为树的节点,最终构造的树结构如下,右侧的X和Y分别表示基于第一个维度和第二个维度进行切分。
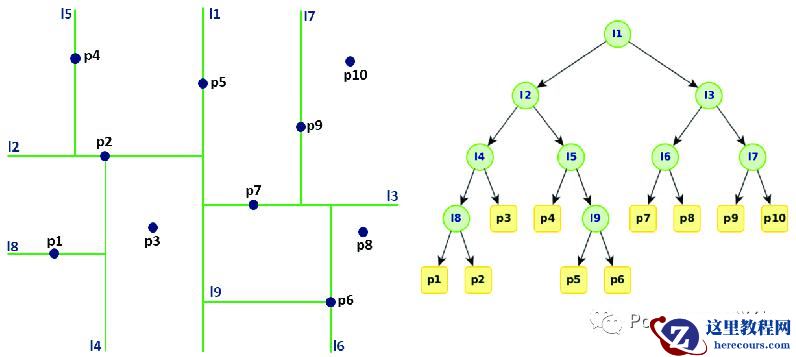
一般而言,在空间维度 (d<=30) 比较低的时候,KD 树是比较高效的,针对高维数据提出了优化的 KD-tree with BBF (Best Bin First) 算法。
向量数据库分类
ANN 是向量数据库的核心,一个成熟的向量数据库集成了大量的 ANN 算法, 并根据各种指标选择最合适的策略。另外就是其还是一个数据库,仅仅有向量检索还不行,还要有数据库的常用功能,比如易用的访问接口、备份监控、ACID、访问控制、增删改查、横向扩展等等。向量数据库同时也属于计算密集型,近似计算对于计算能力要求很高,因此也需要硬件的加持,比如 CPU/GPU/FPGA/ASIC等。
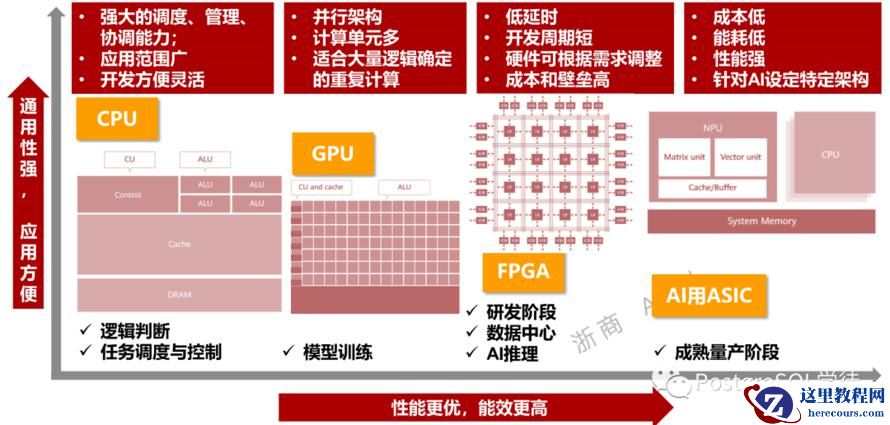
目前市面上的向量数据库百花齐放,其中 pgvector / pg_embedding / pgvecto.rs 等属于一个独特的存在,以插件的形式存在,站在 PostgreSQL 的肩膀上。

pgvector
在所有现有向量数据库中,pgvector 是一个独特的存在 —— 它选择了在现有的世界上最强大的开源关系型数据库 PostgreSQL 上以插件的形式添砖加瓦,而不是另起炉灶做成另一个专用的"数据库" 。
“市面上有许多向量数据库产品,商业的有 Pinecone,Zilliz,开源的有 Milvus,Qdrant 等,基于已有流行数据库以插件形式提供的则有 pgvector 与 Redis Stack。
在所有现有向量数据库中,pgvector 是一个独特的存在 —— 它选择了在现有的世界上最强大的开源关系型数据库 PostgreSQL 上以插件的形式添砖加瓦,而不是另起炉灶做成另一个专用的"数据库" [1]。pgvector 有着优雅简单易用的接口,不俗的性能表现,更是继承了PG生态的超能力集合。
另外一个选择站在 PostgreSQL 肩膀上的插件是 pg_embedding,号称比 pgvector 快 20 倍,基于 HNSW
“The pg_embedding extension enables the using the Hierarchical Navigable Small World (HNSW) algorithm for vector similarity search in PostgreSQL.
This extension is based on ivf-hnsw implementation of HNSW the code for the current state-of-the-art billion-scale nearest neighbor search system
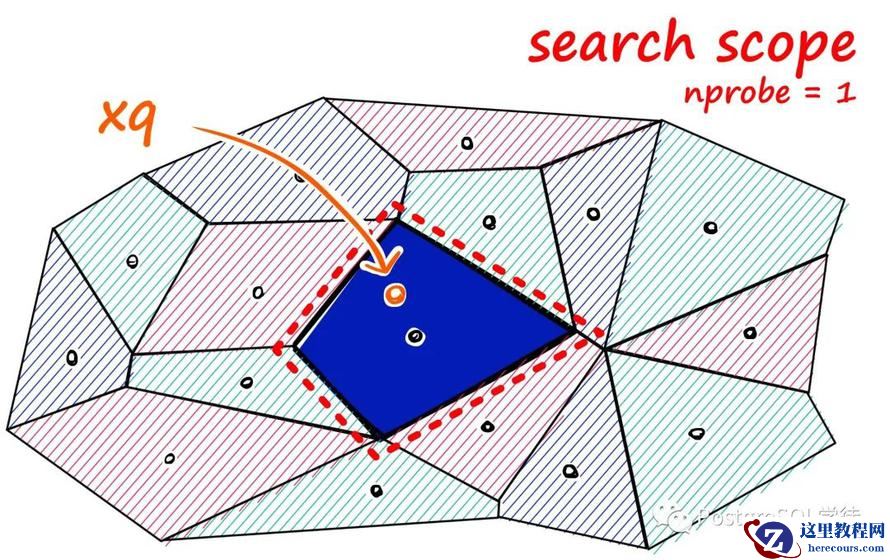
此处以 pgvector 为例,pgvector 提供了 ivfflat 算法以近似搜索,它的工作原理是将相似的向量聚类为区域,并建立一个倒排索引,将每个区域映射到其向量。这使得查询可以集中在数据的一个子集上,从而实现快速搜索。通过调整列表和探针参数,ivfflat 可以平衡数据集的速度和准确性,使 PostgreSQL 有能力对复杂数据进行快速的语义相似性搜索。通过简单的查询,应用程序可以在数百万个高维向量中找到与查询向量最近的邻居。对于自然语言处理、信息检索等,ivfflat 是一个比较好的解决方案。
“A higher value provides better recall at the cost of speed, and it can be set to the number of lists for exact nearest neighbor search (at which point the planner won’t use the index)
“Let’s look at the
ivfflat method as an example. When building anivfflat index, you decide how manylists you want to have in it. Eachlist represents a “center”; these centers are calculated using a k-means algorithm. Once you determine all of your centers,ivfflat determines what center each vector is closest to and adds it to the index. When it’s time to query your vector data, you then decide how many centers to check, which is determined by theivfflat.probes parameter. This is where you see the ANN performance/recall tradeoff: the more centers you visit, the more precise your results, but at the expense of performance.Because of the popularity of storing the output of AI/ML in “vector databases” and of
pgvector, there are plenty of examples for how to usepgvector. So instead, I’ll focus on where things are heading.让我们以 ivfflat 方法为例。在建立 ivfflat 索引时,你需要决定索引中包含多少个 list。每个 list 代表一个 "中心";这些中心通过 k-means 算法计算而来。一旦确定了所有中心,ivfflat 就会确定每个向量最靠近哪个中心,并将其添加到索引中。当需要查询向量数据时,你可以决定要检查多少个中心,这由 ivfflat.probes 参数决定。这就是 ANN 性能/召回率的结果:访问的中心越多,结果就越精确,但这是以牺牲性能为代价的。
由于在 "向量数据库 "和 pgvector 中存储 AI/ML 输出的做法很流行,因此有很多例子可以说明如何使用 pgvector。因此,我将专注于事情的发展方向。
可以看到 pgvector 支持余弦、欧式和内积操作符。内积 (inner product) 一般用在内积空间中,点积 (dot product) 一般用在欧几里得空间中,数量积 (scalar product) 通常认为与点积是相等的。

虽说 pgvector just a extention,但是其性能相较于专用数据库也不遑多让,满足大多数业务场景。
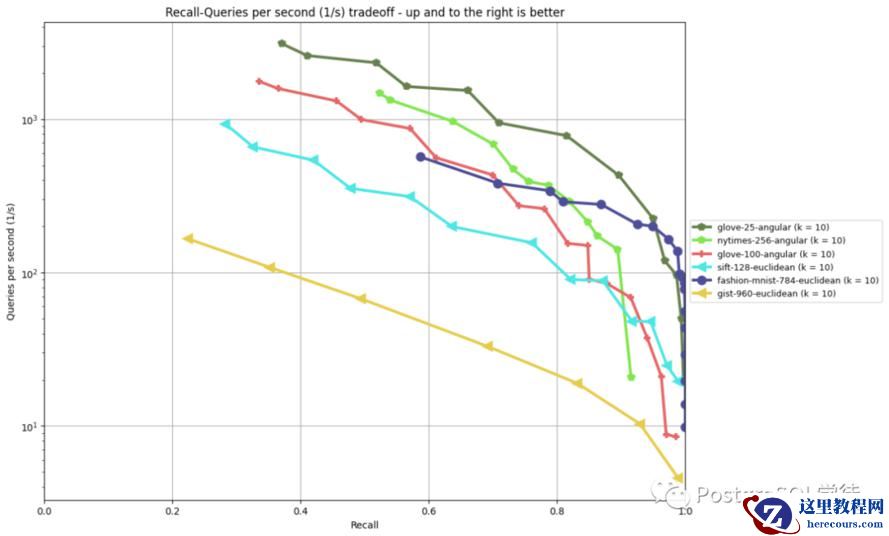
不过 pgvector 的索引算法对磁盘并不友好,是为在内存中使用而设计的。目前 Pigsty 团队正在致力于改进 pgvector 的实现,实现了另外一种主流向量索引算法 HNSW,在一些场景下较 IVFFLAT 有着 20 倍的性能提升。让我们拭目以待。
小结
目前向量数据库的赛道仍处于发展初期,随着大模型日趋成熟,越来越多玩家瞄准向量数据库的机会并选择加入赛道,呈现百花齐放的竞争格局。而 pgvector 选择了站在 PostgreSQL 肩膀上,高屋建瓴,让PostgreSQL 的能力更上一层楼, 成为 AI 浪潮下的翘楚。Give it a try !
参考文献
AI大模型与向量数据库 PGVECTOR
VECTORS ARE THE NEW JSON IN POSTGRESQL
向量数据库
十分钟带你入门向量检索技术
向量检索简述
10分钟了解向量数据库
【上集】向量数据库技术鉴赏
【下集】向量数据库技术鉴赏
PostgreSQL向量数据库pgvector之ivfflat实践
向量数据库——AI时代的技术基座
向量数据库——大模型引发爆发式增长
大白话聊聊“深度学习”和“大模型”
2022年10月中国数据库行业分析报告-向量启航,引擎加持
https://oi-wiki.org/ds/kdt/
近似最近邻算法 HNSW 学习笔记(一)介绍
干货 | 一文读懂 ANN
https://github.com/pgvector/pgvector







")



