来源:MySQL数据库联盟
作者简介
马听,多年 DBA 实战经验,对MySQL、 Redis、MongoDB、Go等有一定了解,书籍《MySQL DBA精英实战课》作者,慕课网DBA体系课(https://class.imooc.com/sale/dba)讲师。
尽管现在很多SQL可以借助AI来优化,比如小编前面写的一篇文章:如何通过ChatGPT优化MySQL的SQL语句。
但是有些场景,可能ChatGPT并不能完全正确的优化,或者ChatGPT优化的SQL,需要我们再去校验,这个时候就需要用到执行计划的基本功了。
这一节我们就来详细介绍一下MySQL的执行计划工具explain。
Explain 可以获取 MySQL 优化器考虑使用的 SQL 语句执行计划,比如语句是否使用了关联查询、是否使用了索引、扫描行数等。可以帮我们选择更好地索引和写出更优的 SQL 。
使用方法:在查询语句前面加上 explain 运行就可以了。
这也是分析 SQL 时最常用的,也是最推荐的一种分析慢查询的方式。
这篇文章详细讲了执行计划各个字段的含义,大部分是不用记的,只要在使用时,再找到这篇文章对照就行。
1 准备
准备测试数据
为了便于理解,先创建两张测试表,建表及数据写入语句如下:
CREATE DATABASE martin;
use martin;
drop table if exists t1;
CREATE TABLE `t1` (
`id` int NOT NULL auto_increment,
`a` int DEFAULT NULL,
`b` int DEFAULT NULL,
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间',
PRIMARY KEY (`id`),
KEY `idx_a` (`a`),
KEY `idx_b` (`b`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
drop procedure if exists insert_t1;
delimiter ;;
create procedure insert_t1()
begin
declare i int;
set i=1;
while(i<=1000)do
insert into t1(a,b) values(i, i);
set i=i+1;
end while;
end;;
delimiter ;
call insert_t1();
drop table if exists t2;
create table t2 like t1;
insert into t2 select * from t1;
尝试explain的用法
下面尝试使用 explain 分析一条 SQL,例子如下:
explain select * from t1 where b=100;

2 Explain的结果各字段解释
如下:
加粗的列为需要重点关注的项。
列名 | 解释 |
id | 查询编号 |
select_type | 查询类型:显示本行是简单还是复杂查询 |
table | 涉及到的表 |
partitions | 匹配的分区:查询将匹配记录所在的分区。仅当使用 partition 关键字时才显示该列。对于非分区表,该值为 NULL。 |
type | 本次查询的表连接类型 |
possible_keys | 可能选择的索引 |
key | 实际选择的索引 |
key_len | 被选择的索引长度:一般用于判断联合索引有多少列被选择了 |
ref | 与索引比较的列 |
rows | 预计需要扫描的行数,对 InnoDB 来说,这个值是估值,并不一定准确 |
filtered | 按条件筛选的行的百分比 |
Extra | 附加信息 |
其中 explain 各列都有各种不同的值,这里介绍几个比较重要列常包含的值:
下面将列出它们常见的一些值,可稍微过一遍,不需要完全记下来,在后续分析SQL时,可以返回查询这篇文章的内容并对比各种值的区别。
3 select_type各种值的解释
select_type 的值 | 解释 |
SIMPLE | 简单查询(不使用关联查询或子查询) |
PRIMARY | 如果包含关联查询或者子查询,则最外层的查询部分标记为primary |
UNION | 联合查询中第二个及后面的查询 |
DEPENDENT UNION | 满足依赖外部的关联查询中第二个及以后的查询 |
UNION RESULT | 联合查询的结果 |
SUBQUERY | 子查询中的第一个查询 |
DEPENDENT SUBQUERY | 子查询中的第一个查询,并且依赖外部查询 |
DERIVED | 用到派生表的查询 |
MATERIALIZED | 被物化的子查询 |
UNCACHEABLE SUBQUERY | 一个子查询的结果不能被缓存,必须重新评估外层查询的每一行 |
UNCACHEABLE UNION | 关联查询第二个或后面的语句属于不可缓存的子查询 |
4 type各种值的解释
type的值 | 解释 |
system | 查询对象表只有一行数据,且只能用于 MyISAM 和 Memory 引擎的表,这是最好的情况 |
const | 基于主键或唯一索引查询,最多返回一条结果 |
eq_ref | 表连接时基于主键或非 NULL 的唯一索引完成扫描 |
ref | 基于普通索引的等值查询,或者表间等值连接 |
fulltext | 全文检索 |
ref_or_null | 表连接类型是 ref,但进行扫描的索引列中可能包含 NULL 值 |
index_merge | 利用多个索引 |
unique_subquery | 子查询中使用唯一索引 |
index_subquery | 子查询中使用普通索引 |
range | 利用索引进行范围查询 |
index | 全索引扫描 |
ALL | 全表扫描 |
上表的这些情况,查询性能从上到下依次是最好到最差。
5 key_len各种字段类型对应的长度
explain 中的 key_len 列用于表示这次查询中,所选择的索引长度有多少字节,常用于判断联合索引有多少列被选择了。下表总结了常用字段类型的 key_len:
列类型 | KEY_LEN | 备注 |
int | key_len = 4+1 | int 为 4 bytes,允许为 NULL,加 1 byte |
int not null | key_len = 4 | 不允许为 NULL |
bigint | key_len=8+1 | bigint 为 8 bytes,允许为 NULL 加 1 byte |
bigint not null | key_len=8 | bigint 为 8 bytes |
char(30) utf8 | key_len=30*3+1 | char(n)为:n * 3 ,允许为 NULL 加 1 byte |
char(30) not null utf8 | key_len=30*3 | 不允许为 NULL |
varchar(30) not null utf8 | key_len=30*3+2 | utf8 每个字符为 3 bytes,变长数据类型,加 2 bytes |
varchar(30) utf8 | key_len=30*3+2+1 | utf8 每个字符为 3 bytes,允许为 NULL,加 1 byte,变长数据类型,加 2 bytes |
datetime | key_len=8+1 (MySQL 5.6.4之前的版本);key_len=5+1(MySQL 5.6.4及之后的版本) | 允许为 NULL,加 1 byte |
6 Extra常见值的解释
Extra 常见的值 | 解释 | 例子 |
Using filesort | 将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序 | explain select * from t1 order by create_time; |
Using temporary | 需要创建一个临时表来存储结构,通常发生对没有索引的列进行 GROUP BY 时 | explain select * from t1 group by create_time; |
Using index | 使用覆盖索引 | explain select a from t1 where a=111; |
Using where | 使用 where 语句来处理结果 | explain select * from t1 where create_time='2019-06-18 14:38:24'; |
Impossible WHERE | 对 where 子句判断的结果总是 false 而不能选择任何数据 | explain select * from t1 where 1<0; |
Using join buffer (hash join) | 关联查询中,被驱动表的关联字段没索引 | explain select * from t1 straight_join t2 on (t1.create_time=t2.create_time); |
Using index condition | 先条件过滤索引,再查数据 | explain select * from t1 where a >900 and a like '%9'; |
Select tables optimized away | 使用某些聚合函数(比如 max、min)来访问存在索引的某个字段是 | explain select max(a) from t1; |
...... |
|
|
7 对比有无索引的执行计划
条件字段是主键的执行计划
explain select * from t1 where id=100;

type是const,表示基于主键或唯一索引的查询
key 是PRIMARY,表示走了主键索引
row 表示扫描的行数,只扫描了一行。
条件字段有索引的执行计划
explain select * from t1 where b=100;

重点关注
type,这里是ref,表示:基于普通索引的等值查询,或者表间等值连接
key这个字段,这里可以看出来,是走了索引的。
然后再看rows,发现只扫描了1行
条件字段没索引的执行计划
删除b字段上的索引
alter table t1 drop index idx_b;
再来看刚才这条语句的执行计划
explain select * from t1 where b=100;

type,是ALL,表示:全表扫描。
key,是NULL,表示没走索引。
rows,这里其实是扫描了很多行,这里是估值,所以不一定准确。
8 获取分区信息
创建测试表并写入数据
CREATE TABLE sales (
sale_id INT,
sale_date DATE,
amount DECIMAL(10, 2)
) PARTITION BY RANGE (YEAR(sale_date)) (
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN MAXVALUE
);
INSERT INTO sales (sale_id, sale_date, amount)
VALUES
(1, '2022-01-01', 100.50),
(2, '2022-02-15', 200.75),
(3, '2022-03-20', 150.00),
(4, '2023-04-10', 300.20),
(5, '2023-05-05', 250.80),
(6, '2023-06-12', 180.30),
(7, '2023-07-08', 220.40),
(8, '2024-08-23', 270.60),
(9, '2024-09-17', 320.90),
(10, '2024-10-05', 280.75);
查询分区表里面的数据
select * from sales where sale_date='2024-09-17';
查看执行计划
explain select * from sales where sale_date='2024-09-17';

explain select * from sales where sale_date>'2023-01-01';

可以看到,在这种情况下,执行计划就可以显示分区信息。
9 获取正在执行语句的执行计划
在一个窗口构造一条慢查询
select *,sleep(100) from t1 limit 1;
在另外一次窗口查看当前连接
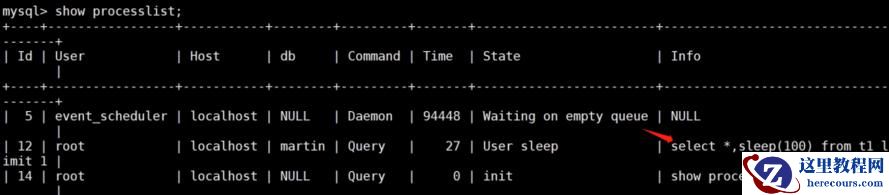
再来查询给定连接的执行计划
EXPLAIN FOR CONNECTION 12;

就可以看到,这个连接正在执行SQL的执行计划。
这个通常用来分析正在执行的问题SQL。
10 MySQL 8.0执行计划的新用法
树状执行计划
从MySQL 8.0.16开始,可以输出树状执行计划,并且能返回预估成本和预估的返回行数
explain format=tree select * from t1 where a=100;
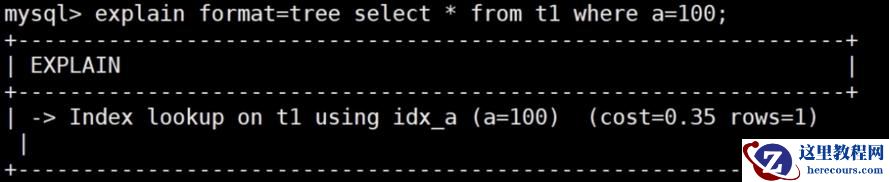
cost表示预估成本信息;
rows表示预估扫描行数。
explain analyze
从MySQL 8.0.18开始,引入了EXPLAIN ANALYZE
使用这个,会执行SQL,并返回有关执行成本,返回行数,执行时间,循环次数等信息
explain analyze select * from t1 where a=100;

cost 表示预估的成本信息
rows 前面的表示预估值,后面的表示实际返回的行数
actual time 第一个值是获取第一行的实际时间,第二个值获取所有行的时间,如果循环了多次就是平均时间,单位毫秒
loops 循环次数












