来源:PostgreSQL学徒
前言
最近一直在恶补网络有关的知识,主要在学习如何分析网络丢包以及网络性能优化,我会分成两篇来总结,第一篇先总结下网络丢包,对于DBA来说,网络和数据库息息相关,我碰到因为丢包导致莫名其妙的流复制冲突导致备库卡住,也遇到过丢包导致PostgreSQL性能骤降的案例,因此作为全干工程师,掌握基本的网络分析技能是十分重要的!
协议
首先是耳熟能详的协议了,也是了解入门网络的基础之一。就如同人与人之间相互交流是需要遵循一定的规则一样,计算机之间的相互通信也同样需要遵守一定的规则,这些规则就是网络协议。
以OSI标准模型为例,分为物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。
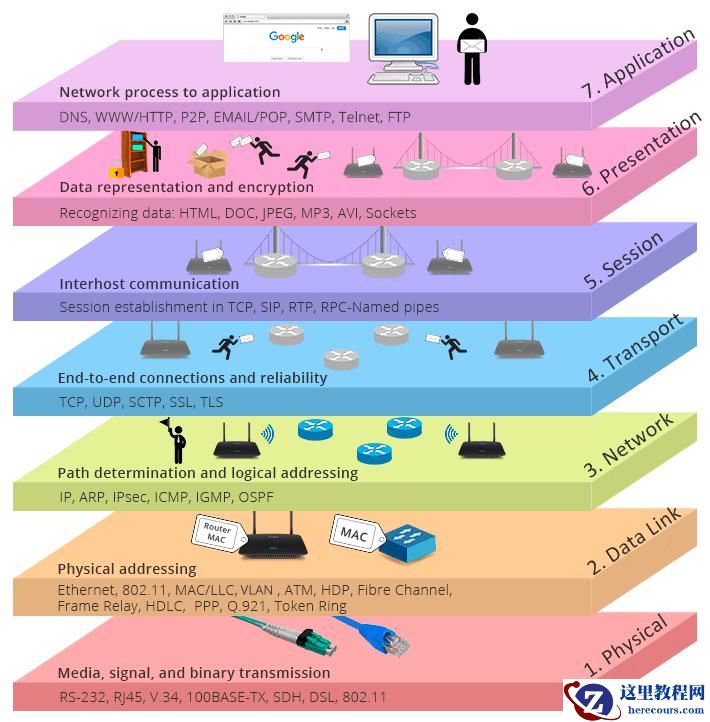
每一层都有自己的功能,各司其职,就像建筑物一样,每一层都靠下一层支持,每一层传输单位都有不同的名词,数据链路层的传输单位是帧,IP 层的传输单位是包,TCP 层的传输单位是段,HTTP 的传输单位则是消息或报文,这些名词可以统称为数据包。参照下图????????
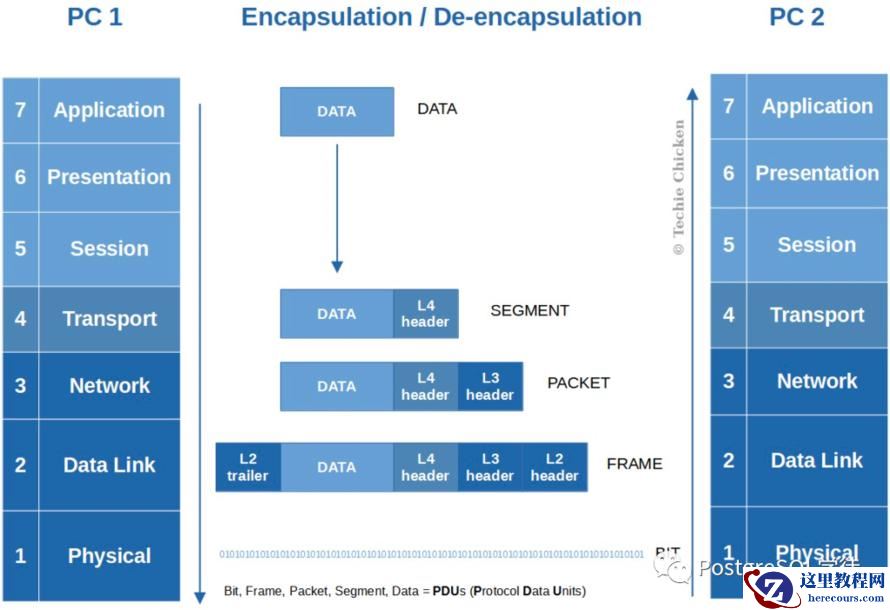
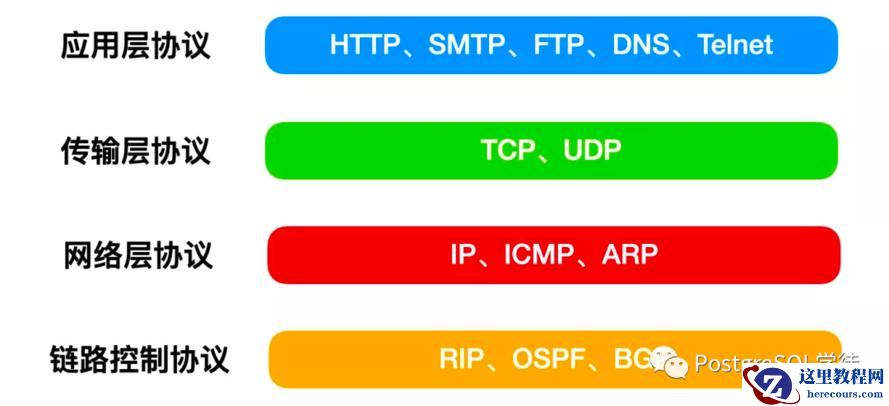
网络收发流程
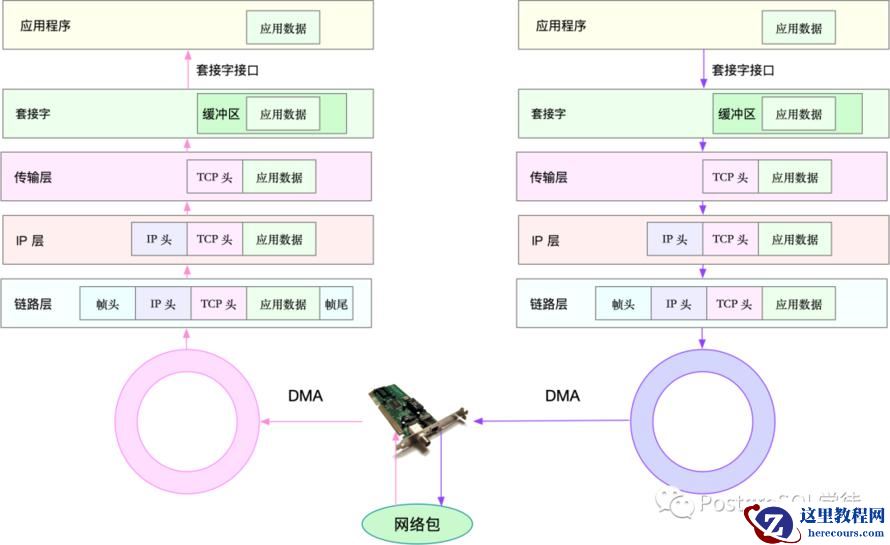
可以看到,在数据包的发送过程中,各层依次对数据包添加了首部信息,每个首部都包含发送端和接收端地址以及上一层的协议类型。以太网会使用 MAC 地址、IP 会使用 IP 地址、TCP/UDP 则会用端口号作为识别两端主机的地址。
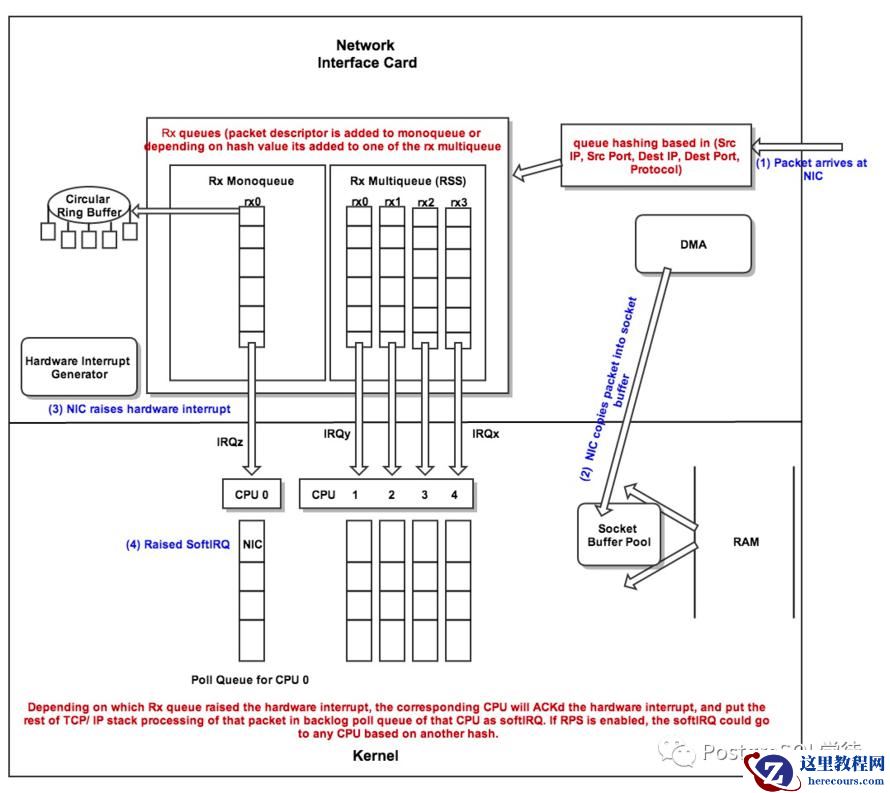
从宏观角度看收包过程:
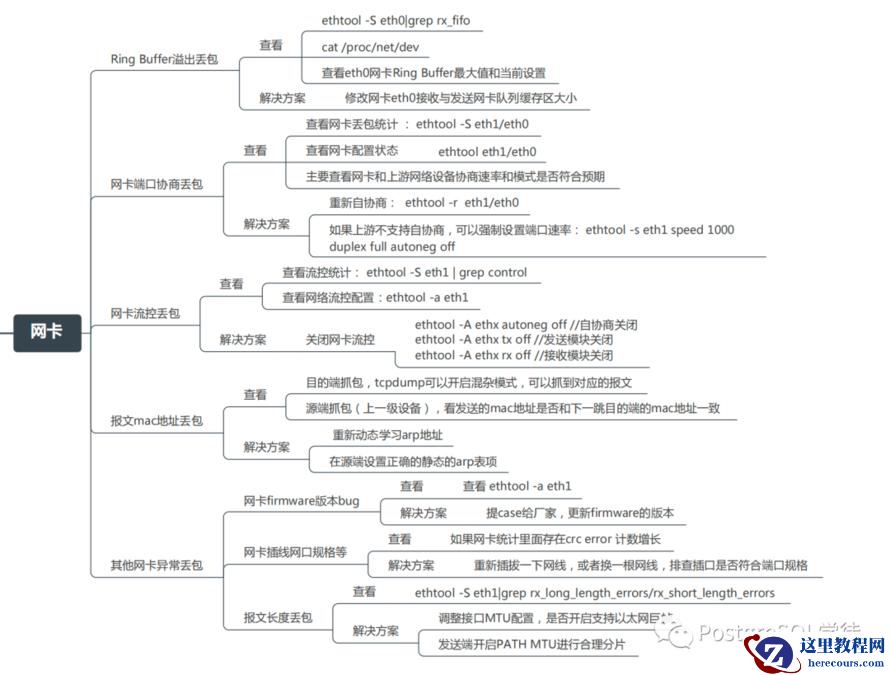
因此丢包会涉及到⽹卡、驱动、内核协议栈三⼤类,每一层都有可能会丢包:
此处推荐阅读下飞哥的图解 Linux 网络包发送过程
“在Linux内核实现中,链路层协议靠网卡驱动来实现,内核协议栈来实现网络层和传输层。内核对更上层的应用层提供socket接口来供用户进程访问。
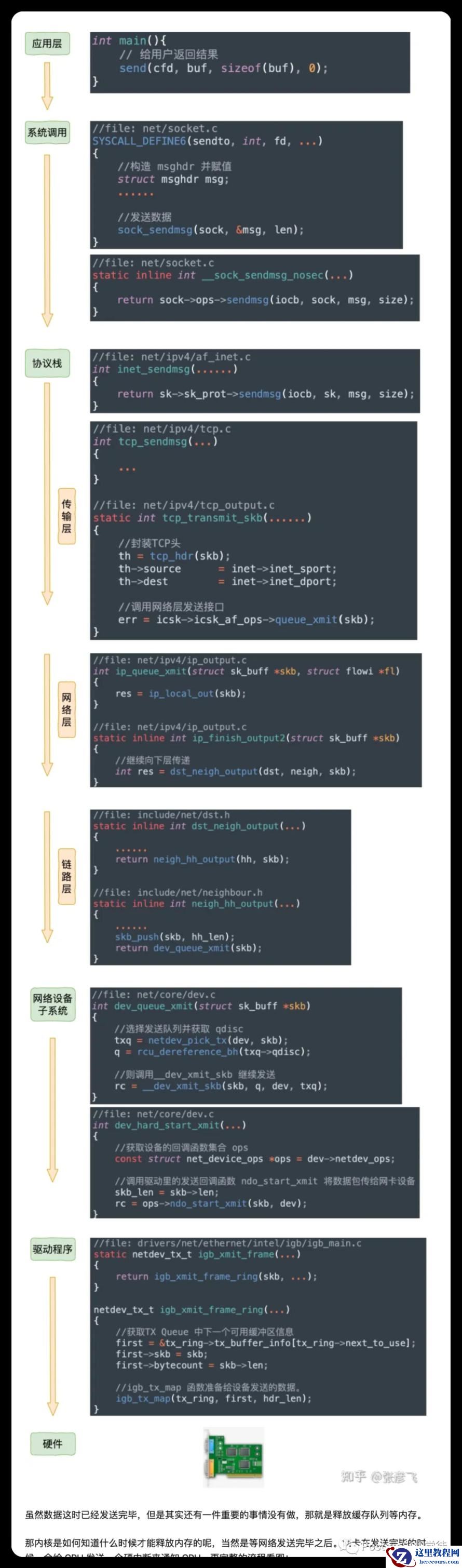
硬件网卡层
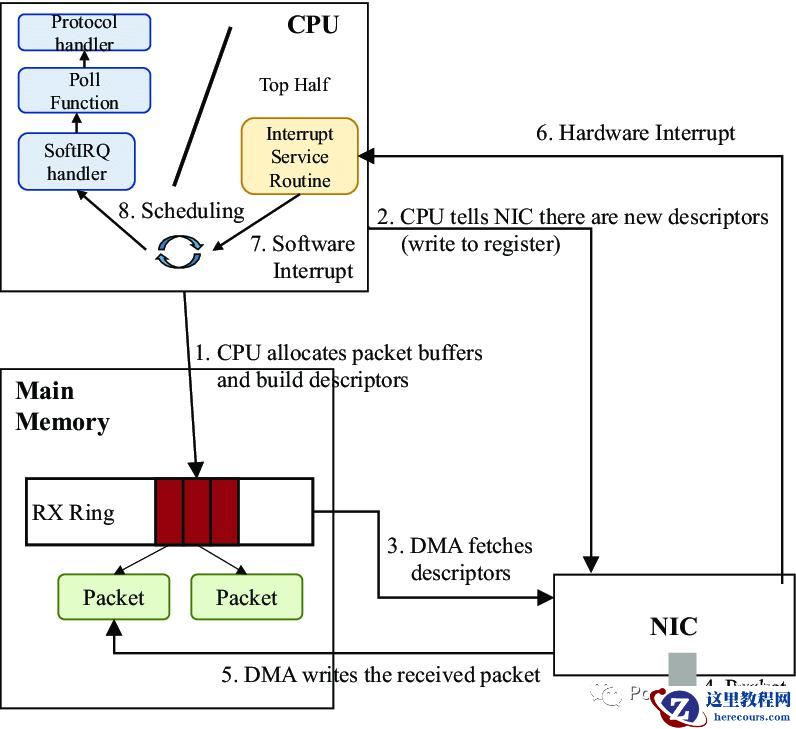
物理介质上的数据帧到达后首先由NIC读取,写入设备内部缓冲区Ring Buffer中,再由中断处理程序触发Softirq从中消费,Ring Buffer的大小因网卡设备而异。当网络数据包到达(生产)的速率快于内核处理(消费)的速率时,Ring Buffer很快会被填满,新来的数据包将被丢弃;
我们可以通过ethtool、netstat或者cat /proc/net/dev查看因Ring Buffer满而丢弃的包统计
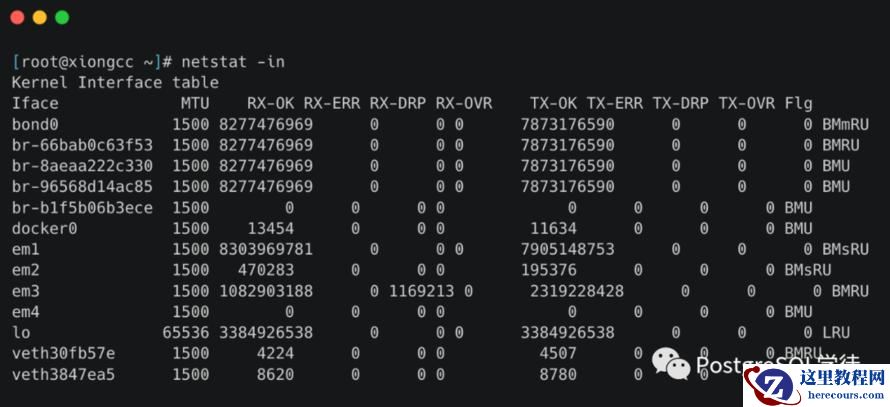
ring buffer的大小我们可以通过ethtool进行查看以及修改
-g :Display the rx/tx ring parameter information of the specified ethernet card。-G :change the rx/tx ring setting of the specified ethernet card。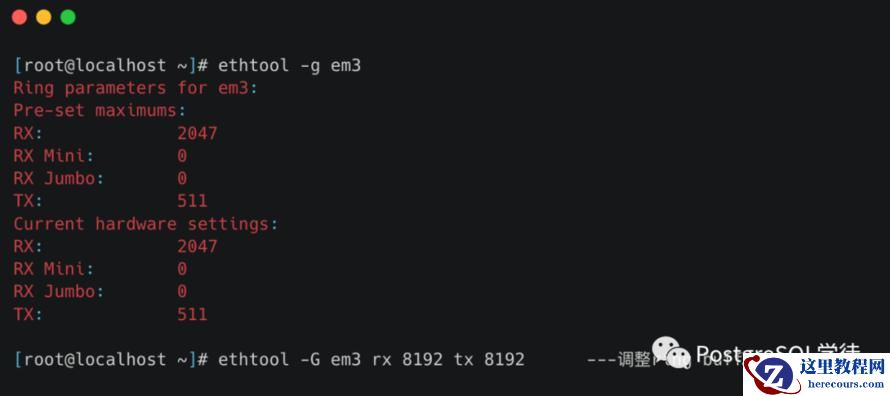
思维导图 (From Alex——网络排障全景指南v1.0精简版)
驱动层
我们可以使用ifconfig查看
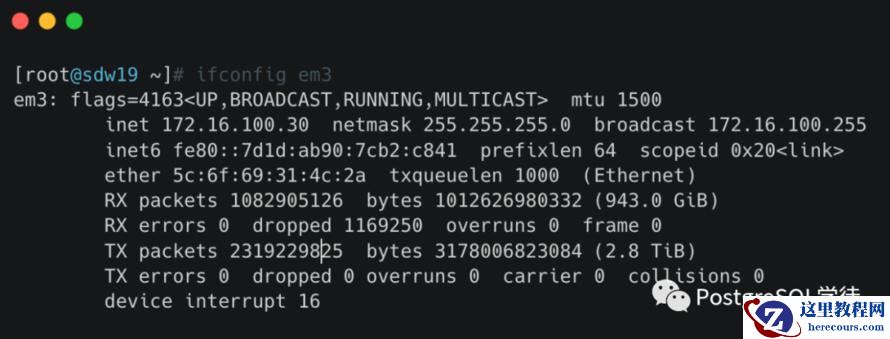
至于 TX 相关的类似,指发送时对应的各个指标。
另外一个常见原因是单核CPU软中断占有高,导致应用没有机会收发或者收包比较慢,我们可以使用 ethtool -x查看,这些指标显示了接口如何处理入站网络流量,通过散列函数和转向表来分配到不同的接收环,从而实现在多处理器系统中的负载均衡。
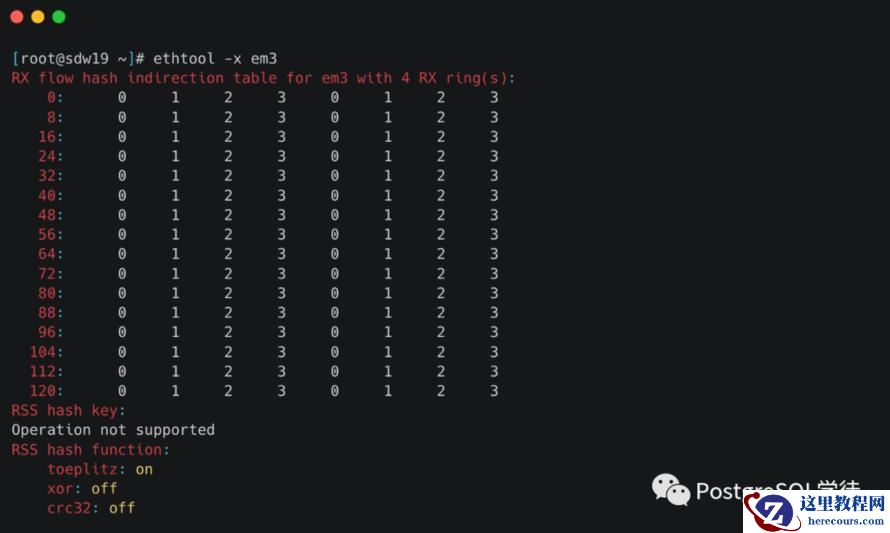
这里要提一下网卡多队列 RSS(Receive Side Scaling)是网卡的硬件特性(需要硬件支持),实现了多队列,多队列是RX/TX多个通路,分别负责各种的中断,可以将不同的流分发到不同的CPU上;
我们可以使用ethtool -l查看支持的队列数,以及ethtool -L eth0 combined 4修改队列数
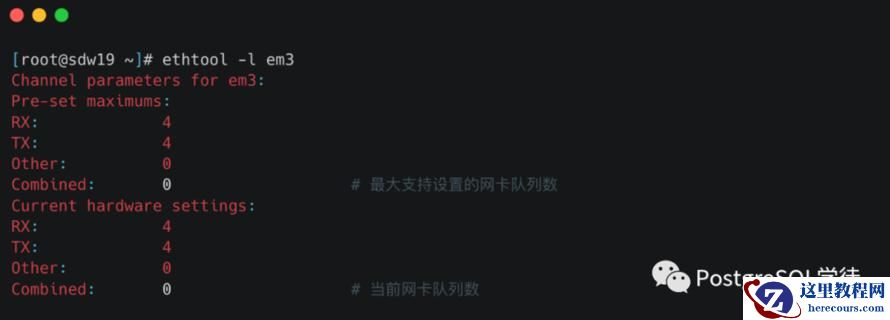
配置了之后,我们可以使用cat /proc/interrupts查看当前是否已经开启了网卡多队列,通过查看网卡的中断集中分布在哪些CPU上,如果分布在多个CPU上,则当前已经开启了网卡多队列。以及通过绑核的方式将中断绑定到具体的CPU上
echo "1" > /proc/irq/31/smp_affinity
echo "1" > /proc/irq/32/smp_affinity
echo "2" > /proc/irq/33/smp_affinity
echo "2" > /proc/irq/34/smp_affinity
echo "4" > /proc/irq/35/smp_affinity
echo "4" > /proc/irq/36/smp_affinity
echo "8" > /proc/irq/37/smp_affinity
echo "8" > /proc/irq/38/smp_affinity
当然也可以通过irqbalance,irqbalance避免所有的IRQ请求都由单一的CPU负担,从而将硬件中断分布到多处理器系统的各个处理器以便能够提高性能,安装方式为:yum -y install irqbalance;
思维导图 (From Alex——网络排障全景指南v1.0精简版)

网络层
网络层我们可以使用 netstat -s 进行过滤
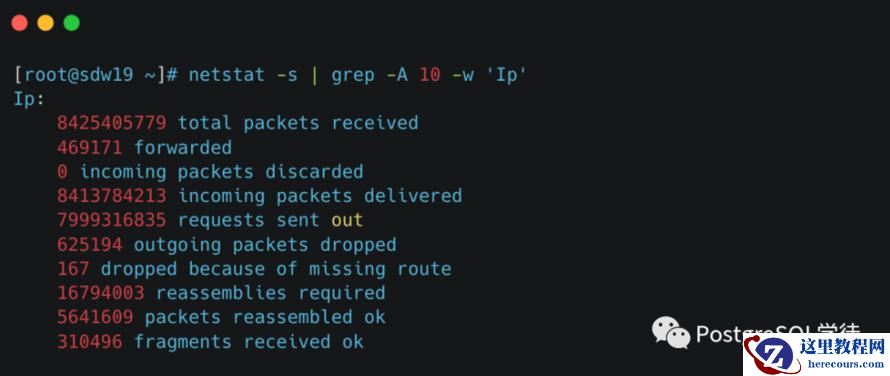
以下是来自GPT4的回答:
ICMP也是类似,此处就不再演示了。
另外一类可能的原因就是防火墙了, iptables -nvL |grep DROP ;
思维导图 (From Alex——网络排障全景指南v1.0精简版)

传输层
传输层协议包括TCP和UDP,也可以使用netstat查看
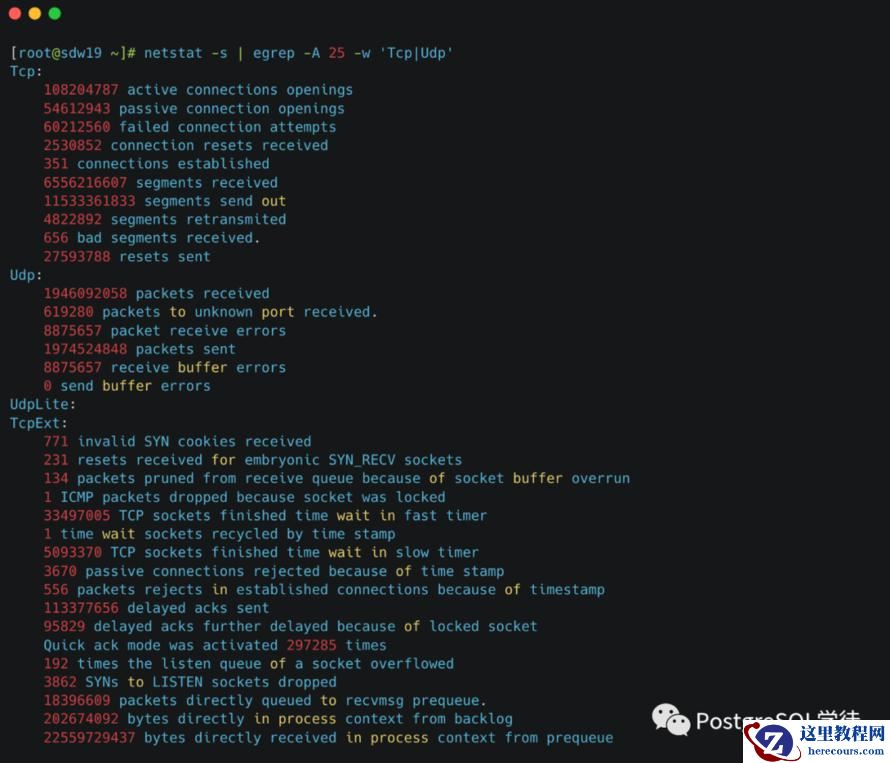
可以看到 retransmitted 就是 TCP重传次数,bad 就是错误报文数,这个结果告诉我们TCP 协议有多次重传。至于下方的TcpExt,各个指标就不细展开了,可以询问GPT。
另外需要提及的是TIME_WAIT过多丢包,大量TIME_WAIT出现,并且需要解决的场景,在高并发短连接的TCP服务器上,当服务器处理完请求后立刻按照主动正常关闭连接。这个场景下,会出现大量socket处于TIMEWAIT状态。如果客户端的并发量持续很高,此时部分客户端就会显示连接不上,新建立 TCP 连接会出错,address already in use : connect 异常
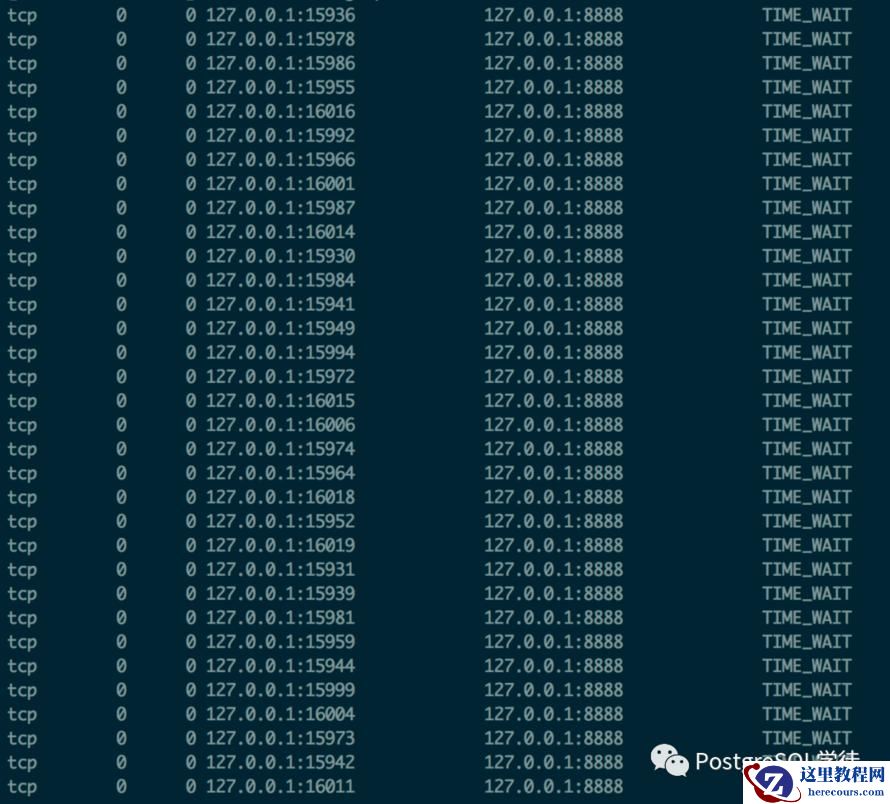
我们可以调整允许 time_wait 状态的 socket 被重用,tw_reuse,tw_recycle ,以及内存足够的话调整tcp_max_tw_buckets大小。
思维导图 (From Alex——网络排障全景指南v1.0精简版)
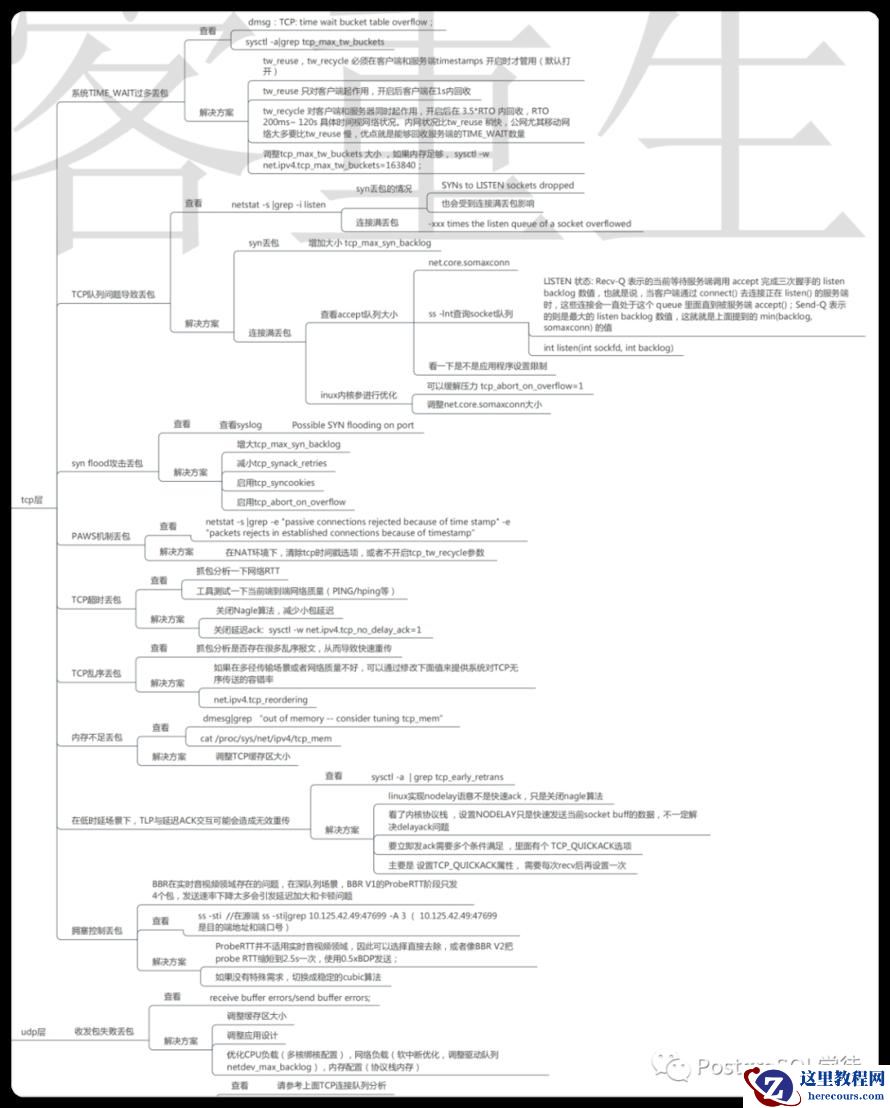
套接字
[root@localhost ~]# netstat -s|grep "packet receive errors"
8878816 packet receive errors
可以看到有大量的socket缓存区接收丢包,我们可以调整socket缓冲区大小
# Default Socket Receive Buffer
net.core.rmem_default = 31457280
# Maximum Socket Receive Buffer
net.core.rmem_max = 67108864
类似的还有应用发送太快导致丢包,以类似方式优化。
[root@localhost ~]# netstat -s|grep "send buffer errors
# Default Socket Send Buffer
net.core.wmem_default = 31457280
# Maximum Socket Send Buffer
net.core.wmem_max = 33554432
思维导图 (From Alex——网络排障全景指南v1.0精简版)

实用工具
除了前文提到的ethtool、netstat之类的命令,还推荐一个命令——sar,
看个例子,比如 sar -n DEV 1 | awk 'NR == 3 || $3 == "eth0"'只分析eth0
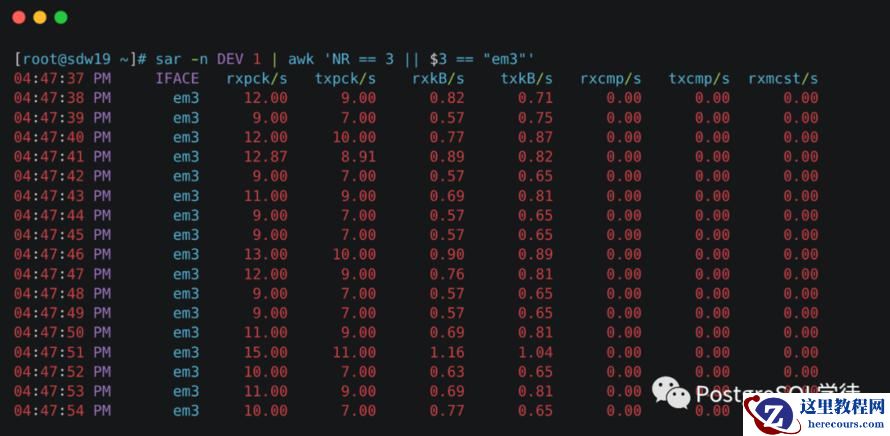
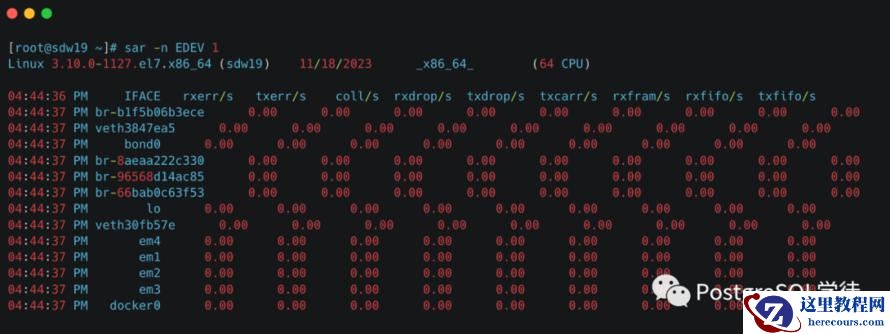
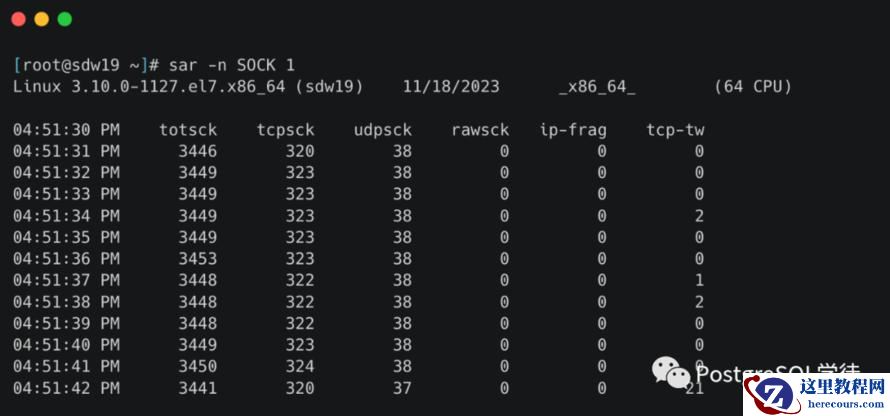








")


")