来源:mikechen的互联网架构
最近有同学参加阿里面试时,被问到了这道题目。
2 亿条数据实现秒查,MySQL 索引为什么那么快?
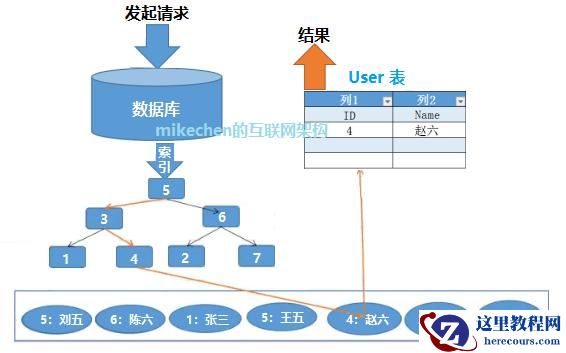
在 2 亿条数据中,查询一条数据:
不使用索引:耗时约 200 万秒,逐行查找,全表遍历;
使用索引:耗时 1 秒不到,快速定位数据行,加快查询速度。
MySQL 索引是数据库性能优化的关键,它可以提高数据库的查询效率,数据量越大,这种优势就越明显。
大家好,我是 mikechen,本文主要介绍 MySQL 索引。先来简单回顾下索引的概念。
索引是存储引擎用于快速查询记录的一种数据结构,通过规则的数据结构和实际目标关联,根据特定规则算法,快速实现寻址的功能。
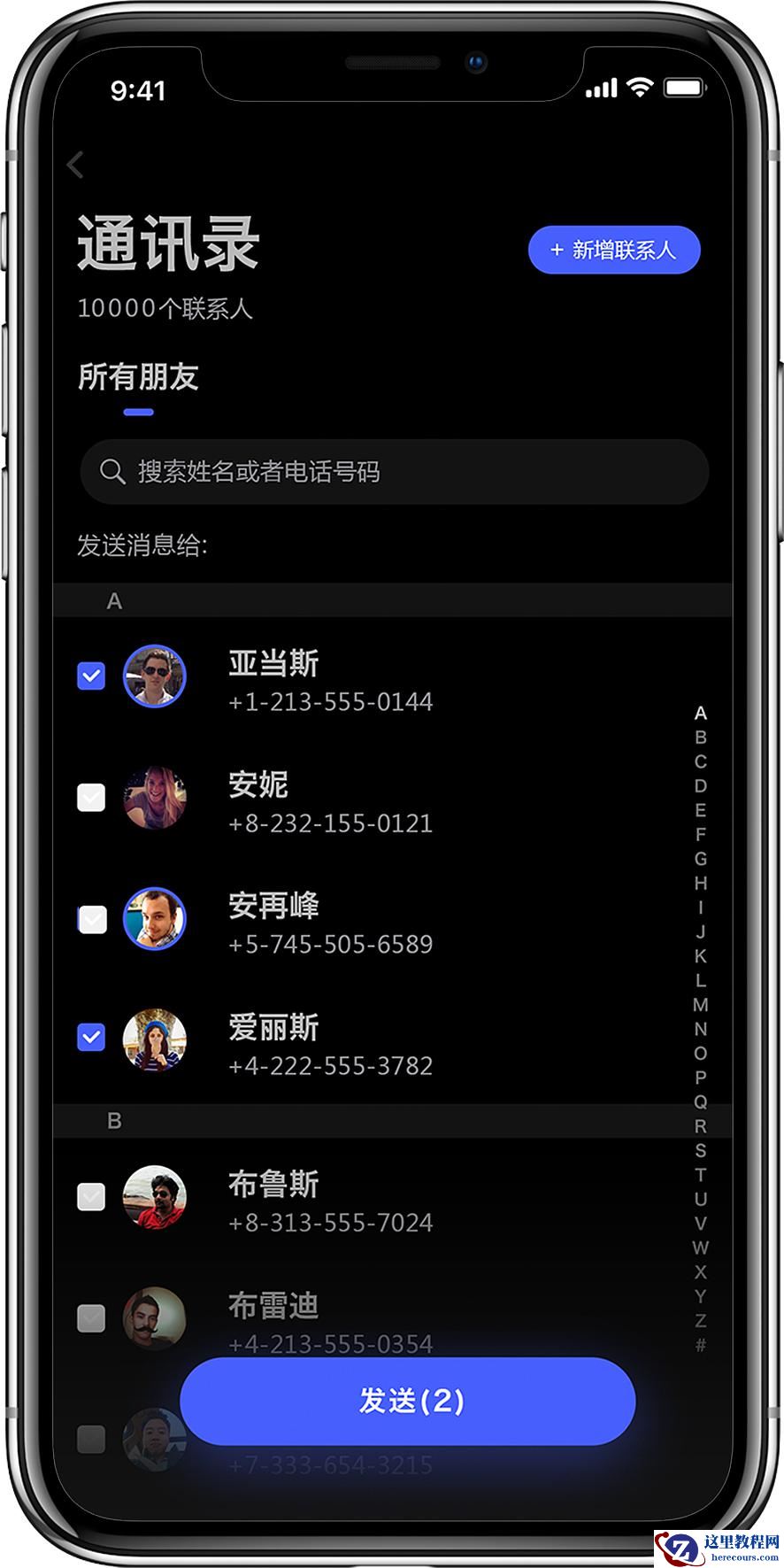
索引类似于手机通讯录的首字母检索。
当我们想要查找某个人的电话号码时,是依据联系人姓名的首字母查询,从而找到其电话号码的。
试想下,如果手机通讯录没有首字母检索,就需要逐一查找,有 10000 个联系人,就 GG 了......
为了便于理解,下面通过具体例子,来了解索引的使用原理。
假设:
有一个用户表,需要查询 ID 为【 4 、赵六】的数据。
select*from User where ID=4
我们先来看看,在不使用索引的情况下,数据库是如何查询数据的。
1)不使用索引
不使用索引,数据库默认是全文搜索查询,采用的是全表扫描。
即:先遍历所有的页面,再遍历页面中的记录,逐条记录比对,最后找到需要查询的记录。
在大数据量中查询数据时,就会消耗大量的时间和资源。
不使用索引,数据库查询数据的过程:
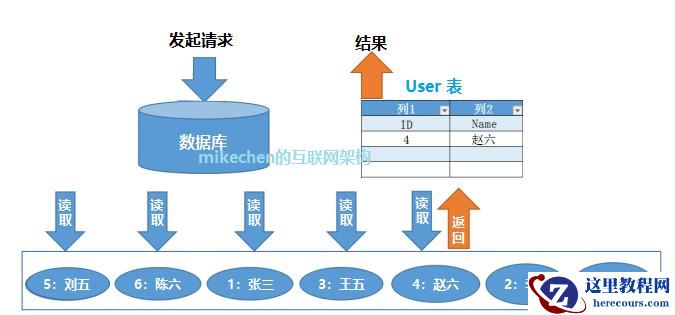
如图,经过顺序查找、进行 5 次寻址,查询到了 ID 为【 4 、赵六】的数据。
按照这个方法,我们来计算下,如果要在 2 亿条数据中,查询指定的某条数据,需要使用多长时间?
时间复杂度是 O(N),N 是指总的记录条数。
MySQL 数据是写在磁盘上的,一次磁盘寻址所需要的时间是 10 ms。
2 亿条数据,执行一次查询耗时 20 亿毫秒,即 200 万秒。
也就是说,不使用索引,在 2 亿条数据中查询某一条数据,需要使用约 23 天。差不多小 1 个月,查询效率太低。
如果我们使用索引,查询效率会有多大的改善呢?我们接着往下看。
2)使用索引
使用索引,数据库查询数据的过程:
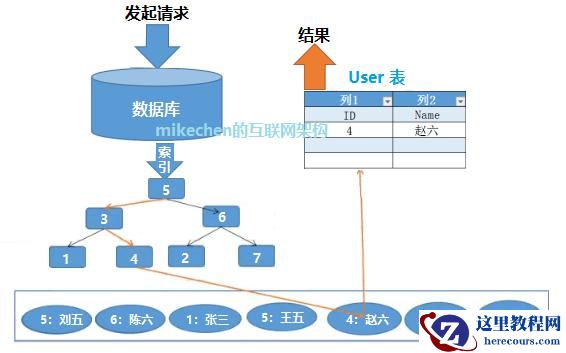
如图,使用平衡二叉树索引,只用 3 次就完成了数据查询。
一个简单的索引实现,我们把所有的数据排序,通过二分查找的方式来查找,查询的时间复杂度是 O(logN)。
2 亿条数据中查询一条数据,只需要 40 多次查询,耗时小于 1 秒。
显然,在使用索引后,查询效率显著提高。且数据量越大,索引的这种优势就越明显。
提高查询效率:通过快速定位数据行,加快查询操作的执行速度;
优化排序:在排序操作中,减少数据的扫描和比较次数,提高排序效率;
保证数据的唯一性:唯一索引可以确保特定列上的数据唯一性,防止重复值的插入;
提供约束:通过主键和唯一索引,可以对数据的完整性和唯一性进行约束。
索引最主要的优点是提高查询效率,但同时也会带来一些性能和存储方面的开销。
索引的主要优点:
索引极大减少了服务器需要扫描的数据量,提高了数据的检索速度;
可以帮助服务器避免排序和创建临时表;
可以将随机 IO 变成顺序 IO;
通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性;
在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。
索引的主要缺点:
创建索引和维护索引需要耗费时间,这种时间随着数据量的增加而增加;
需要占用物理空间;
对表中的数据进行增、删、改时,索引也要动态的维护,增加了维护成本。
在实际应用中,综合权衡索引的优缺点、以及具体查询场景,合理使用索引。
PS.
对于非常小的表,多数情况下用全表扫描更高效。
另外,如果某个数据列包含许多重复的内容,建立索引也没有太大的实际效果。
通过本文,我们了解并掌握了索引的概念、作用、原理及优缺点。这部分内容既是精进 MySQL 的基石,也是 MySQL 面试的高频知识点,非常重要。












