索引下推(index condition pushdown ,ICP)是MySQL数据库优化器的一项优化技术,目的是为了提高通用索引检索数据的效率,尤其是在InnoDB存储引擎中。这项技术在MySQL5.6中引入,专门用于减少从表中读取不必要的行,提高查询性能。工作原理:在没有索引下推的情况下,当查询使用复合索引时,MySQL可能需要访问主表来评估不能完全通过索引条件确定的行。
索引下推允许数据库存储引擎在存储层直接应用WHERE子句中的过滤条件,而不是先将所有匹配的数据行返回给查询处理层(server层)再进行过滤。因此它能在使用索引时减少回表查询次数,提高查询效率。
假设有一个包含许多列的用户表 users,复合索引为name_age(name,age)。
例如,执行下面一条SQL语句:
select * from users where name like 'a%' and age = 10;
在Mysql5.6之前的执行流程是这样的:
1.根据最左前缀原则,执行name like 'a%'可以快速检索出id的值为1,2。
+------+------+------+| id | name | age |+------+------+------+| 1 | aaaa | 10 || 2 | abc | 40 |+------+------+------+2 rows in set (0.03 sec)
2.然后根据id的值进行回表操作,再次进行过滤age=10的数据,
查询id=1回表1次,id=2回表1次,这个过程总共回表了2次。
可能到这里都会有疑问:
为什么不在索引里面直接过滤age=10的数据,因为复合索引里面也存了age的数据,这样明明可以减少回表1次。
恭喜啦,Mysql5.6以后就这么做了,这就是索引下推。无索引下推:
过程使用数字符号标示,如①②③等)
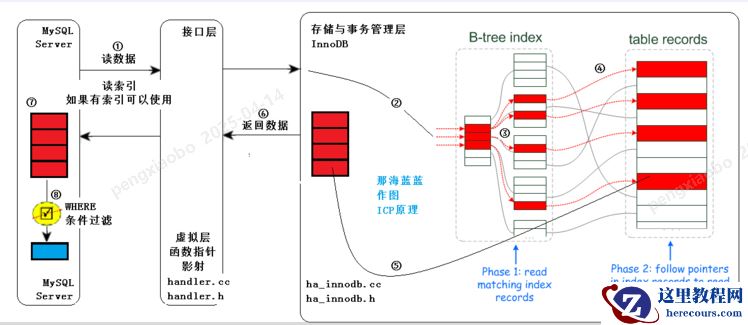 执行的过程:
①:MySQL Server发出读取数据的命令,这是在执行器中执行如下代码段,通过函数指针和handle接口
调用存储引擎的索引读或全表表读。此处进行的是索引读。
②、③:进入存储引擎,读取索引树,在索引树上查找,把满足条件的(经过查找,红色的满足)
从表记录中读出(步骤④,通常有IO),从存储引擎返回⑤标识的结果。
此处,不仅要在索引行进行索引读取(通常是内存中,速度快。步骤③),还要进行进行步骤④,通常有IO。
⑥:从存储引擎返回查找到的多条元组给MySQL Server,MySQL Server在⑦得到较多的元组。
⑦--⑧:⑦到⑧依据WHERE子句条件进行过滤,得到满足条件的元组。
注意在MySQL Server层得到较多元组,然后才过滤,最终得到的是少量的、符合条件的元组。
有索引下推:
过程使用数字符号标示,如①②③等)
执行的过程:
①:MySQL Server发出读取数据的命令,这是在执行器中执行如下代码段,通过函数指针和handle接口
调用存储引擎的索引读或全表表读。此处进行的是索引读。
②、③:进入存储引擎,读取索引树,在索引树上查找,把满足条件的(经过查找,红色的满足)
从表记录中读出(步骤④,通常有IO),从存储引擎返回⑤标识的结果。
此处,不仅要在索引行进行索引读取(通常是内存中,速度快。步骤③),还要进行进行步骤④,通常有IO。
⑥:从存储引擎返回查找到的多条元组给MySQL Server,MySQL Server在⑦得到较多的元组。
⑦--⑧:⑦到⑧依据WHERE子句条件进行过滤,得到满足条件的元组。
注意在MySQL Server层得到较多元组,然后才过滤,最终得到的是少量的、符合条件的元组。
有索引下推:
过程使用数字符号标示,如①②③等)
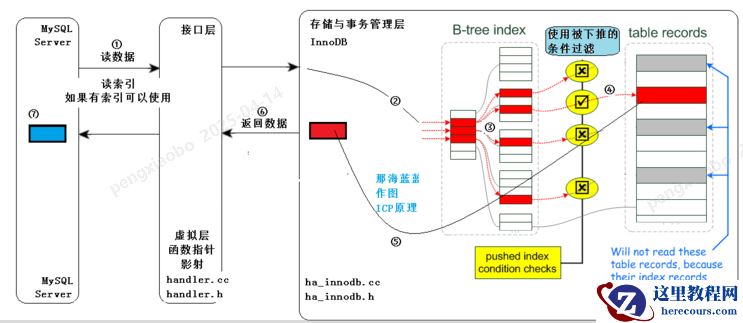 执行的过程:
①:MySQL Server发出读取数据的命令,过程同图一。
②、③:进入存储引擎,读取索引树,在索引树上查找,把满足已经下推的条件的(经过查找,红色的满足)
从表记录中读出(步骤④,通常有IO),从存储引擎返回⑤标识的结果。
此处,不仅要在索引行进行索引读取(通常是内存中,速度快。步骤③),还要在③这个阶段依据下推的条件进行进行判断,
不满足条件的,不去读取表中的数据,直接在索引树上进行下一个索引项的判断,直到有满足条件的,才进行步骤④,
这样,较没有ICP的方式,IO量减少。(通过过滤也相当于减少数据量,也是减少io了)
⑥:从存储引擎返回查找到的少量元组给MySQL Server,MySQL Server在⑦得到少量的元组。
因此比较图一
无索引下推的方式,返回给MySQL Server层的即是少量的、符合条件的元组。
适用场景索引下推非常适合于查询条件中涉及多个列的过滤,且这些列存在符合索引的情况下,它可以在索引扫描过程中应用额外的过滤条件来减少所需的行访问。多列索引:索引下推在多列索引的情况下效果更好,可以同时利用多个列的顺序性和范围性进行过滤。范围查询:索引下推在范围查询的情况下效果更好,可以直接在索引上进行过滤,避免了不必要的数据读取和传输。优势1.减少I/O操作:因为避免了对不必要的表记录的读取,所以可以大幅减少I/O操作。2.提高查询效率: 直接在索引层面过滤筛选数据,进一步减少了需要处理的数据量。3.更快的响应时间:整体上更有效的索引应用提高了查询响应速度。4.节省资源:减轻了内存和CPU的压力。5.减少临时表的创建和排序:索引下推可以减少不符合条件的记录的读取和传输,从而减少了临时表的创建和排序操作。索引下推是MySQL优化器更加智能,更加成熟发展的一个体现。熟练使用理解该功能有助于优化复杂查询和提高查询性能。
执行的过程:
①:MySQL Server发出读取数据的命令,过程同图一。
②、③:进入存储引擎,读取索引树,在索引树上查找,把满足已经下推的条件的(经过查找,红色的满足)
从表记录中读出(步骤④,通常有IO),从存储引擎返回⑤标识的结果。
此处,不仅要在索引行进行索引读取(通常是内存中,速度快。步骤③),还要在③这个阶段依据下推的条件进行进行判断,
不满足条件的,不去读取表中的数据,直接在索引树上进行下一个索引项的判断,直到有满足条件的,才进行步骤④,
这样,较没有ICP的方式,IO量减少。(通过过滤也相当于减少数据量,也是减少io了)
⑥:从存储引擎返回查找到的少量元组给MySQL Server,MySQL Server在⑦得到少量的元组。
因此比较图一
无索引下推的方式,返回给MySQL Server层的即是少量的、符合条件的元组。
适用场景索引下推非常适合于查询条件中涉及多个列的过滤,且这些列存在符合索引的情况下,它可以在索引扫描过程中应用额外的过滤条件来减少所需的行访问。多列索引:索引下推在多列索引的情况下效果更好,可以同时利用多个列的顺序性和范围性进行过滤。范围查询:索引下推在范围查询的情况下效果更好,可以直接在索引上进行过滤,避免了不必要的数据读取和传输。优势1.减少I/O操作:因为避免了对不必要的表记录的读取,所以可以大幅减少I/O操作。2.提高查询效率: 直接在索引层面过滤筛选数据,进一步减少了需要处理的数据量。3.更快的响应时间:整体上更有效的索引应用提高了查询响应速度。4.节省资源:减轻了内存和CPU的压力。5.减少临时表的创建和排序:索引下推可以减少不符合条件的记录的读取和传输,从而减少了临时表的创建和排序操作。索引下推是MySQL优化器更加智能,更加成熟发展的一个体现。熟练使用理解该功能有助于优化复杂查询和提高查询性能。
第37期 MySQL索引下推
来源:这里教程网
时间:2026-03-01 18:30:51
作者:
编辑推荐:
- 第37期 MySQL索引下推03-01
- 第36期 MySQL开启optimizer trace功能03-01
- 一起免费考 MySQL OCP 认证啦03-01
- mysql如何保证主从一致性03-01
- YashanDB:统计信息未触发导致 SQL 性能下降03-01
- 第39期 MySQL给邮箱,身份证类似的字段添加索引的方法03-01
- 数据库管理-第329期 MySQL 30周年生日快乐(20250525)03-01
- 第25期 MySQL部分复制03-01
下一篇:
相关推荐
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-

雷神推出 MIX PRO II 迷你主机:基于 Ultra 200H,玻璃上盖 + ARGB 灯效
2 月 9 日消息,雷神 (THUNDEROBOT) 现已宣布推出基于英
-

制造商 Musnap 推出彩色墨水屏电纸书 Ocean C:支持手写笔、第三方安卓应用
2 月 10 日消息,制造商 Musnap 现已在海外推出一款 Oce
热文推荐
- 第37期 MySQL索引下推

第37期 MySQL索引下推
26-03-01 - 一起免费考 MySQL OCP 认证啦

一起免费考 MySQL OCP 认证啦
26-03-01 - 第39期 MySQL给邮箱,身份证类似的字段添加索引的方法

第39期 MySQL给邮箱,身份证类似的字段添加索引的方法
26-03-01 - 数据库管理-第329期 MySQL 30周年生日快乐(20250525)
")
数据库管理-第329期 MySQL 30周年生日快乐(20250525)
26-03-01 - 第25期 MySQL部分复制

第25期 MySQL部分复制
26-03-01 - 百亿大表的实时分析:华安基金 HTAP 数据库的选型历程与 TiDB 使用体验
- 主从从库MTS HANG死一列

主从从库MTS HANG死一列
26-03-01 - 主从从库MTS HANG死一列

主从从库MTS HANG死一列
26-03-01 - 慢查询中关于MDL LOCK记录的变化

慢查询中关于MDL LOCK记录的变化
26-03-01 - 主从半同步降级异步分析

主从半同步降级异步分析
26-03-01