背景
客户收到了SQL专家云告警邮件,在凌晨2点到3点之间带有资源等待的会话数暴增,请我们协助分析。
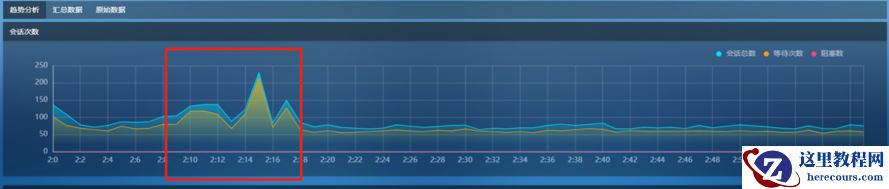
现象 1
登录SQL专家云,进入活动会话的趋势分析页面,下钻到2点钟一个小时内的数据,看到每分钟的等待数都在100左右,2点15分时达到200。
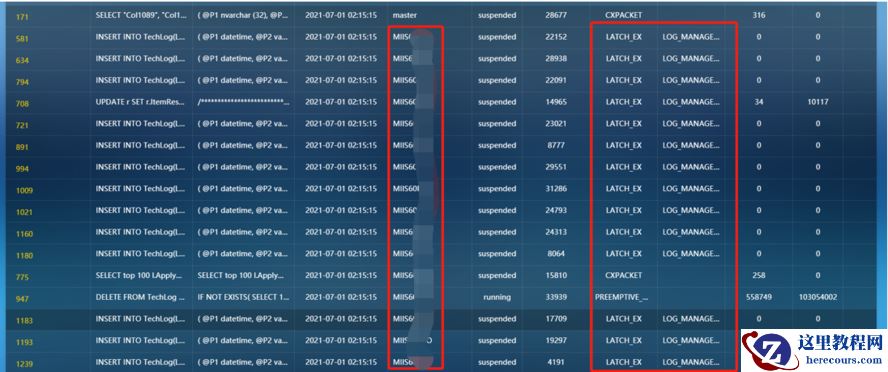
 转到活动会话原始数据页面,看到大量会话都在等待,等待类型是
LATCH_EX,等待资源是
LOG_MANAGER,数据库都是
MIIS****。SQL语句是INSERT、UPDATE、DELETE等写入的语句。
转到活动会话原始数据页面,看到大量会话都在等待,等待类型是
LATCH_EX,等待资源是
LOG_MANAGER,数据库都是
MIIS****。SQL语句是INSERT、UPDATE、DELETE等写入的语句。
分析 2
 接下来分析
LOG_MANAGER的等待,日志文件空间不够时就会触发自动增长,
文件
增长时
,写入数据的
会话必须等
待,此时会看到Lat
c
h
等待类型
,
增长花费的
时间越长,等待的时间越长,造成的性能抖动越严重。
接下来分析
LOG_MANAGER的等待,日志文件空间不够时就会触发自动增长,
文件
增长时
,写入数据的
会话必须等
待,此时会看到Lat
c
h
等待类型
,
增长花费的
时间越长,等待的时间越长,造成的性能抖动越严重。
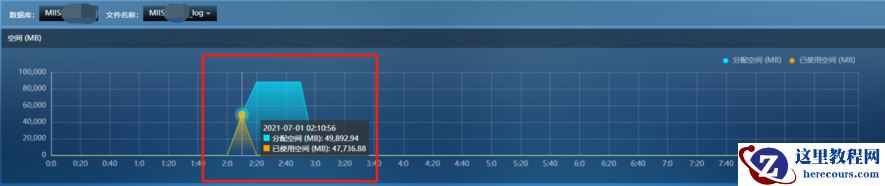
从2点钟开始日志文件频繁自动增长,日志文件的自动增长增量设置为10%,随着日志文件的空间越来越大,每次增加会达到几GB甚至更多,基于磁盘的性能,最少造成
十几秒的性能抖动。

解决 3
-
修改数据文件和日志文件的自动增长为200MB。 每次自动增长很快就能完成,基本不会有性能抖动。 -
调整自动收缩日志文件的维护计划,每次收缩的时候预留10GB的空间,避免频繁的自动增长。 -
定期检查数据文件的空间,一次性增长一定的空间, 避免频繁的自动增长。
其它 4
除非磁盘空间严重不足,否则不要收缩数据文件,详细请参考: 数据库自动收缩造成的阻 塞。








")



