为有效存储及分析这些数据,Apache Doris 针对不同应用场景提供了 Array、Map、Struct、JSON、VARIANT半结构化数据存储分析解决方案。
本文我们将聚焦企业最普遍使用的 JSON 数据,分别介绍业界传统方案以及
半结构化数据特点及挑战
业界通常将数据分为结构化数据、非结构化数据、半结构化数据这三大类型:
结构化数据:关系型数据库是一种典型的结构化数据存储方式,其核心特点是结构严格且固定。例如,一个包含五列数据的表,其数据类型可能是字符串(string)、整数(int)或日期(date)等。字段名和类型均是预先设定、不可轻易改变,具备读写性能出色的优势。
非结构化数据:非结构化数据指没有固定结构的数据,例如文本、音频和视频等,这类数据缺乏明显的结构特征。例如,进行文本检索时,需要查找特定的关键字或短语。 (Apache Doris 从 2.0 版本开始,提供了倒排索引等功能,可以实现对非结构化文本数据的高效检索,包括关键词检索、短语检索等。)
半结构化数据: 半结构化数据虽然拥有一定的结构,但不严格固定,具有很强的灵活性。比较典型的是 JSON 格式,可以便捷地增加新字段或删除不需要的字段,以适应数据交互和存储的需求。
Github 用户操作记录日志 是典型的半结构化 JSON 数据,通过下方示例 CreateEvent 和 PushEvent ,展示真实的数据。
CreateEvent
{ "id": "37066529202", "type": "CreateEvent", "actor": { "id": 151583193, "login": "BlankTMing", "display_login": "BlankTMing", "gravatar_id": "", "url": "https://api.github.com/users/BlankTMing", "avatar_url": "https://avatars.githubusercontent.com/u/151583193?" }, "repo": { "id": 780596894, "name": "BlankTMing/ManifestAutoUpdate-", "url": "https://api.github.com/repos/BlankTMing/ManifestAutoUpdate-" }, "payload": { "ref": "2715611_469785097560218038", "ref_type": "tag", "master_branch": "main", "description": null, "pusher_type": "user" }, "public": true, "created_at": "2024-04-01T23:00:00Z" }
PushEvent
{ "id": "37066529220", "type": "PushEvent", "actor": { "id": 73488070, "login": "hafsa1319", "display_login": "hafsa1319", "gravatar_id": "", "url": "https://api.github.com/users/hafsa1319", "avatar_url": "https://avatars.githubusercontent.com/u/73488070?" }, "repo": { "id": 746560097, "name": "hafsa1319/akademi_report", "url": "https://api.github.com/repos/hafsa1319/akademi_report" }, "payload": { "repository_id": 746560097, "push_id": 17799451996, "size": 1, "distinct_size": 1, "ref": "refs/heads/main", "head": "fc7a15d71539a3588f43e41f9034bfb4b4464358", "before": "e29be382e67485ff5a8a88264f9b3272b2366c3a", "commits": [ { "sha": "fc7a15d71539a3588f43e41f9034bfb4b4464358", "author": { "email": "73488070+hafsa1319@users.noreply.github.com", "name": "hafsa1319" }, "message": "Add or update home/hafsa-report/htdocs/report.hafsa.de/akademi/csv/telcHS2402.csv", "distinct": true, "url": "https://api.github.com/repos/hafsa1319/akademi_report/commits/fc7a15d71539a3588f43e41f9034bfb4b4464358" } ] }, "public": true, "created_at": "2024-04-01T23:00:00Z" }
参考 ,结合实际业务落地的经验,半结构化数据具有以下特点:

不严格遵循结构化表模型 :半结构化数据不严格遵循关系数据库中的表格结构,通常包含标签(tags)或其他形式的标记,以表明其语义或字段名。以上方 GH Archive 示例,"id", "type", "payload" 是标签或者字段名。
自描述结构但不固定:
半结构化数据具有一定自描述性,一般通过键值对(Key-Value Pairs)描述内部结构。这种结构并不固定,可能包含不同数量的字段或类型。以上方 Github Event 示例,PushEvent 的
payload
字段就比 CreateEvent 多了ref head commits 等字段。
通常有嵌套结构:
嵌套结构的复杂性较高,表现为一个结构体内部嵌套另一个结构体,甚至结构体或数组中再嵌套其他结构体或数组,形成多层次、复杂的数据结构。以上方 GH Archive 示例,CreateEvent 中
actor repo payload
有简单的嵌套子字段,而 PushEvent 的 payload 中
commits
字段则出现了数组嵌套结构体、结构体再嵌套结构体的复杂结构。
上述特点为半结构化数据的存储和分析带来很大的挑战,也是业界数据库要解决的主要问题:
如何支持灵活的 Schema :半结构化数据具备较高的灵活性,字段随着业务发展而增加/减少,类型也可能变化,数据中的嵌套结构也让字段变的更加复杂,因此要求数据库能够支持灵活的 Schema。
如何高效存储 :半结构化数据中包含大量重复的自描述内容,比如大量重复的字段名,通常是由机器产生。如果按原始数据存储,数据冗余存储带来的资源浪费非常高,因此要求数据库能够高效存储。
如何极速分析 :半结构化数据通常为文本形式,直接对文本解析和分析虽然可行但性能较差。特别是在分组、聚合、过滤等操作时,要从大量的字段中分析其中的几个字段,将带来很多不必要的 IO 和解析开销。
接下来,我们就以 JSON 数据为例,了解业界为应对这些挑战的常见解决方案。
传统解决方案
01 通过 ETL 转为结构化数据
方案一是在 ETL 过程将半结构化数据转化为结构化数据,主要借助 ETL 工具 / 数据库导入过程中实现。比如在 Doris 中,可以借助导入的 JSON 字段映射功能,将数据映射到预设的表结构中。
该方案的优势是:转化为结构化形式后,可充分利用结构化数据处理的优势,提供较高的存储压缩率和出色的分析性能。
该方案的问题是:当上游数据源字段发生变化(如增加或删除字段)时,下游表结构也进行相应修改。如不修改表结构,新增的数据将无法完整写入。而修改过程非常繁琐,通常需要多个团队协作与配合,处理起来并不高效,且这种方式也丧失了半结构化数据的灵活性。
02 String 存储和 JSON 函数分析
方案二是将 JSON 数据转存到 String 字段中,String 支持存储任意文本数据,可解决 Schema 灵活性差的问题。当需要对这些 JSON 数据查询分析时,可使用专门的 JSON 函数提取所需字段,如可通过
json_extract
、
json_extract_int
、
json_extract_double
等函数解析并提取特定字段值。
该方案的问题是:每次查询都需要使用 JSON 函数解析和遍历整行 JSON 文本,效率低、分析性能差。此外,由于 JSON 文本以行为单位进行存储,其压缩效率不如列式存储高。
03 Elasticsearch Dynamic Mapping
方案三为 Elasticsearch 的 Dynamic Mapping ,该方案可自动识别新增 JSON 数据的字段名和类型,并将字段动态添加到 Elasticsearch Index Mapping (类似 Table Schema) 中。
该方案的问题是:
字段类型一旦确定不可更改,若字段首 次被写入为整型(int),后续则必须保持为整型;如果尝试写入非整型数据(如浮点型 float 或者字符串类型 string),Elasticsearch 将拒绝写入并可能丢弃这条数据,限制了数据类型随业务发展而演变的灵活性。
当写入数据包含大量字段时,Elasticsearch Mapping 会迅速膨胀,这是因为 Elasticsearch 会将每个字段展开,字段多的时候(比如超过 500)元数据压力增大,严重影响查询,而且 Mapping 只增不减,即便删除字段多的行也不能减少元数据。
基于 Apache Doris 的半结构化数据存储及分析方案
针对传统方案存在的问题,Apache Doris 结合不同场景下对半结构化数据存储和分析的需求,提供了三种解决方案,用户可以根据实际场景灵活选择。
01 Array Map Struct
、 、 数据类型支持 嵌套的固定 Schema ,常用于用户行为和画像分析、查询数据湖中 Parquet ORC 等格式数据的场景。
Array Map Struct 可以存储复杂结构数据,Array 存储相同类型的数组,Map 存储键值对(Key-Value ),Struct 存储 n 元组,它们之间可以相互嵌套。
优势:采用列式存储,可实现较高的压缩率,节省大量存储空间;因嵌套结构的字段和类型是预先定义且相对固定的,在写入和查询时不再需要动态推断数据的 Schema,执行效率较高。
不足:虽可以预先定义出复杂的嵌套结构,但是一旦定义后结构不能随着数据变化自适应。
02 JSON
数据类型支持 嵌套的不固定 Schema, 常用于点查和部分分析场景。
JSON 数据类型是二进制存储类型,具备 JSON String 的灵活性,任意合法的 JSON 数据均可进行存储,分析时通过 JSON 函数来提取对应字段。
优势:点查性能好,JSON 采用行存形式进存储,且 JSON 在写入过程中已完成 JSON 的解析,可从二进制中直接读取数据,查询效率至少比 JSON String 快 2 倍。
不足:JSON 存储压缩率低于列存,存储成本也相对较高。同时,因在查询时需要先读取整行 JSON 二进制数据、再读取需要分析的字段,读取效率不如行存高效。
03 VARIANT
数据类型支持 嵌套的不固定 Schema ,常用于 Log、 Trace、 IoT 等分析场景,业界类似的解决方案还有前文所述的 Elasticsearch Dynamic Mapping。
VARIANT 数据类型可以存储任何合法的 JSON,可自动从 JSON 中抽取字段并推断其类型,并将这些字段存储为 VARIANT 列的子列。这种列式存储方式使得 VARIANT 具备很好的分析性能,当进行聚合/过滤/排序等查询时,只需要读取 Variant 子列数据即可,不会产生额外的数据解析开销,查询性能可获得数量级的提升。
相比于 Elasticsearch Dynamic Mapping ,Doris VARIANT 的优势在于:
允许写入不同字段类型,数据文件内部使用最小公共类型存储,数据文件之间采用不同类型存储,互不影响。查询时,可以使用最小公共类型或者用户指定的类型查询。
可以将出现频次较低的字段合并为二进制 JSON 存储,以此避免字段过多引发子列和文件膨胀的问题,可以兼顾性能和数据结构的灵活性。
在基于 ClickBench 的测试数据集上,VARIANT 有很好的性能表现。
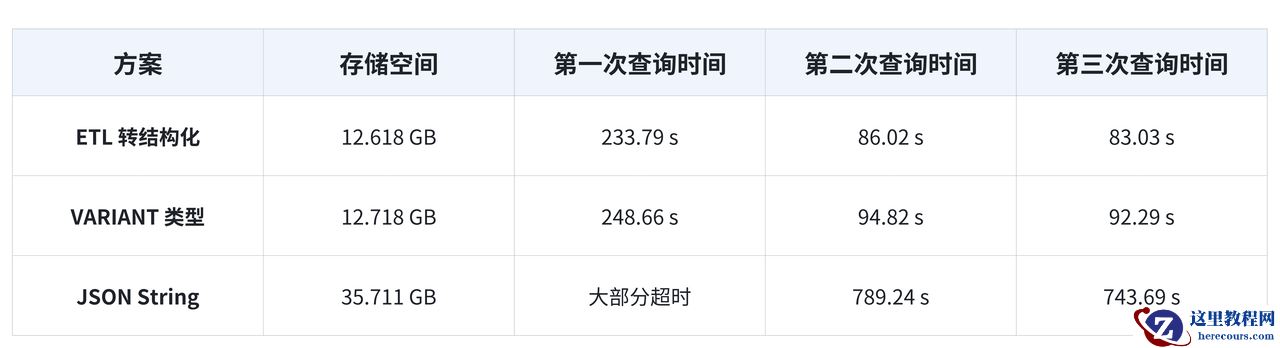
在存储方面,其性能与 ETL 转结构化方案相当,均有较低的存储占用;相较于 JSON String, 存储资源节省达65% 。
在查询方面,其性能与 ETL 转结构化方案相当,冷热查询性能差异在 10% 以内;相较于 JSON String 来说, 冷查询有 10 倍以上提升、热查询有 8.4 倍的提升 ,在用户实际的应用场景中,也验证了相似的结果。
方案对比
为直观比较各方案,我们通过图表来展示 ETL 转结构化、JSON String/Binary、Elasticsearch Dynamic Mapping 、Array Map Struct、JSON、VARIANT 等方案的特点,从 Schema 的灵活性、存储效率和分析性能等维度评估各方案的优势和局限性。 (横坐标轴为 Schema 灵活性、纵坐标轴为 存储效率 & 分析性能 )
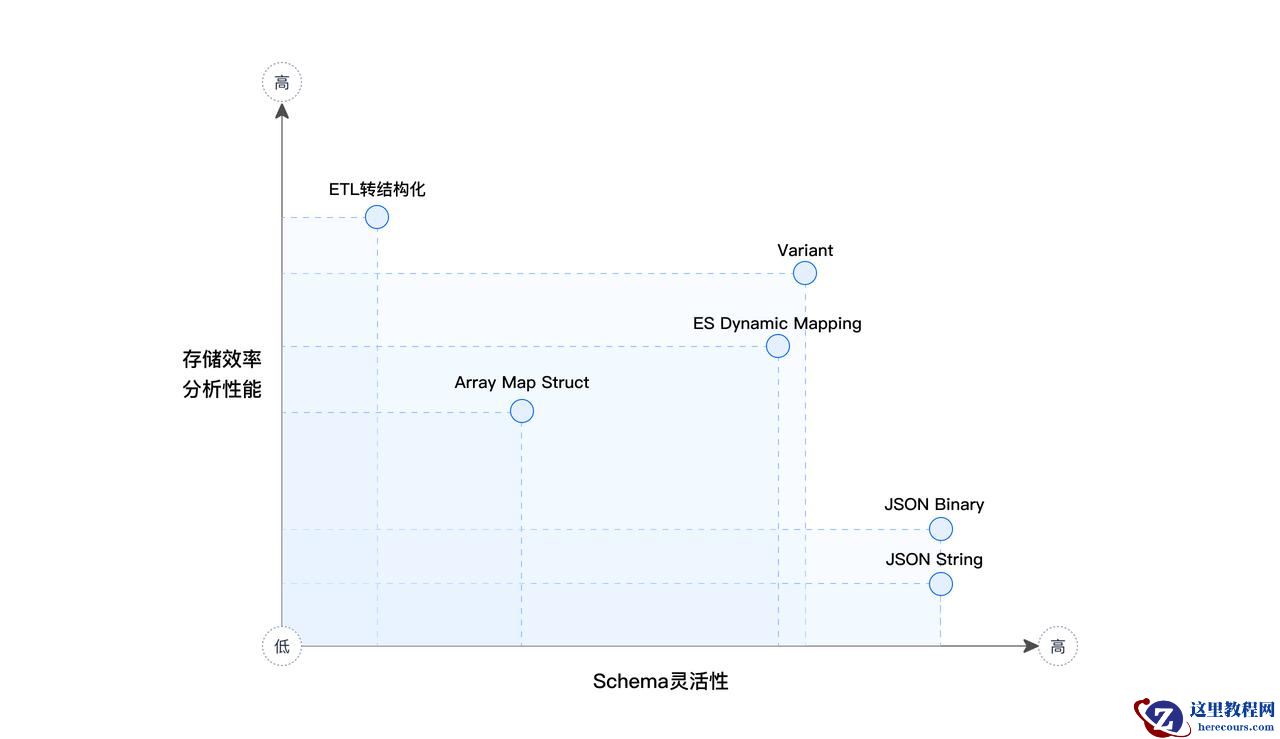
由上图可得出结论:
ETL 转结构化方案的的分析性能表现最佳,但 Schema 灵活性最差。
JSON String / Binary 的 Schema 灵活性最佳,但是其分析性能均比较低。
Doris VARIANT 和 Dynamic Mapping 在灵活性和性能方面表现均比较好,但整体而言 Doris VARIANT 更优,不仅是存储和分析性能强于 Dynamic Mapping,还体现在 VARIANT 能够很好解决字段类型固定和字段个数膨胀的痛点问题。










