AWR生成
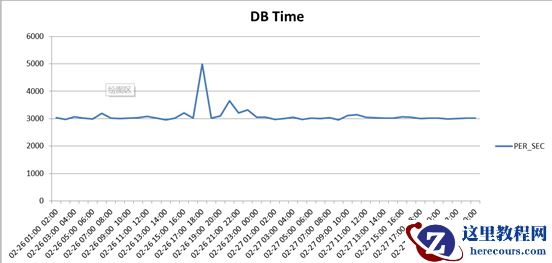
1、 读取项目生产环境CPU 运行情况,生成图形如下:
Sql 脚本为:
WITH sysstat AS (SELECT sn.begin_interval_time begin_interval_time ,sn.end_interval_time end_interval_time ,ss.stat_name stat_name ,ss.snap_id ,ss.dbid ,ss.instance_number ,ss.value e_value ,lag(ss.value ,1) over(ORDER BY ss.snap_id) b_value FROM dba_hist_sysstat ss ,dba_hist_snapshot sn WHERE trunc(sn.begin_interval_time) >= SYSDATE - 6 and trunc(sn.begin_interval_time) <trunc(sysdate)-4 AND ss.snap_id = sn.snap_id AND ss.dbid = sn.dbid AND ss.instance_number = sn.instance_number AND ss.dbid = (SELECT dbid FROM v$database) AND ss.instance_number = (SELECT instance_number FROM v$instance) AND ss.stat_name = 'DB time')SELECT to_char(begin_interval_time ,'mm-dd hh24:mi') || to_char(end_interval_time ,' hh24:mi') date_time ,stat_name ,snap_id ,dbid ,instance_number ,round((e_value - nvl(b_value,0)) / (extract(DAY FROM(end_interval_time - begin_interval_time)) * 24 * 60 * 60 + extract(hour FROM(end_interval_time - begin_interval_time)) * 60 * 60 + extract(minute FROM(end_interval_time - begin_interval_time)) * 60 + extract(SECOND FROM(end_interval_time - begin_interval_time))) ,0) per_secFROM sysstatWHERE (e_value - nvl(b_value ,0)) > 0AND nvl(b_value ,0) > 0
2、 AWR 报告生成。
l Sql 生成qwr 报告
根据时间段找出对应的 begin_snap id 和 end_snap id ,根据需要命名 awr 报告文件名, 则完成 awr 报告的生成; 注: awr报告文件的路径就是当前的文件夹所在的目录,可退出 sql,通过 pwd获取当前路径。
l Plsql 调用生成
SELECT output FROM TABLE(dbms_workload_repository.awr_report_html( l_dbid => 2725556469 –dbid 可根据第1步中的SQL获取 ,l_inst_num => 1 --instance_number 可根据第1步中的SQL获取 ,l_bid => 3215 --begin snap_id ,l_eid => 3227 --end snap_id ));
Awr报告分析
基本信息
根据AWR 报告可知CPU 及版本相关信息如下:
物理CPU 数目( Sockets) 为4 个, CPU 核数(Cores) 为40 ,逻辑CPU( CPU) 为80 ;数据库为RAC 机制的,且数据库版本为11.2.0.4.0
由上图可知该AWR 报告获取了13 个快照,根据时间可以算出2 个小时一个快照
CPU 的利用率为DB Time/(Elapsed*CPUs)=958/(720*80)=1.66% ,说明负载不高,不过这只能说明这一个时间段的平均负载。
查看负载分析报告
Redo size :每秒产生的日志大小(单位字节),可标志数据变更频率, 可以用来估量update/insert/delete的频率。
Logical reads 、Block changes 、Physical reads 、Physical writes : ,评估数据库的读/ 写繁忙程度,判断数据库的活动性质和规模。
Parses 、Hard parses :SQL 软解析以及硬解析的次数,评估SQL 是否需要优化。
Parses: SQL解析的次数 .每秒解析次数,包括 fast parse, soft parse和 hard parse三种数量的综合。软解析每秒超过 300次意味着你的 "应用程序 "效率不高,调整 session_cursor_cache。
在这里, fast parse指的是直接在 PGA中命中的情况(设置了 session_cached_cursors=n);
soft parse是指在 shared pool中命中的情形; hard parse则是指都不命中的情况。
Hard parses:其中硬解析的次数,硬解析太多,说明 SQL重用率不高。每秒产生的硬解析次数 , 每秒超过 100次,就可能说明你绑定使用的不好,也可能是共享池设置不合理。这时候可以启用参数 cursor_sharing=similar|force,该参数默认值为 exact。但该参数设置为 similar时,存在 bug,可能导致执行计划的不优。
Executes 、Transactions : 每秒/ 每事务SQL 执行次数、每秒事务数. 每秒产生的事务数,反映数据库任务繁重与否。
Recursive Call : 递归调用占所有操作的比率. 递归调用的百分比,如果有很多PL/SQL ,那么这个值就会比较高。
Rollback : 每秒回滚率及每事物回滚率,因为回滚很耗资源,如果回滚率过高,可能说明你的数据库经历了太多的无效操作 , 过多的回滚可能还会带来Undo Block 的竞争。
SQL Statics
SQL ordered by Elapsed Time:记录了执行总时间最长的Top SQL,其中Elpsed Time=CPU Time+Wait Time SQL ordered by CPU Time:记录了占CPU时间最长的Top SQL SQL ordered by User I/O Wait Time:记录了执行过程中等待IO时间最长的Top SQL SQL ordered by Gets:记录了执行最多逻辑读(逻辑IO)的Top SQL SQL ordered by Reads:记录了执行最多物理读(物理IO)的Top SQL SQL ordered by Physical Reads (UnOptimized):记录了执行占磁盘物理读(物理IO)的Top SQL(注意的是监控范围内该SQL的执行占磁盘物理读总和,而不是单次SQL执行所占的磁盘物理读) SQL ordered by Executions:记录了执行次数最多的Top SQL,即便单条SQL运行速度飞快,任何被执行几百万次的操作都将耗用大量的时间 SQL ordered by Parse Calls:记录了软解析最多的Top SQL SQL ordered by Sharable Memory:记录了占用library cache的大小的Top SQL。Sharable Mem(b):占用了library cache的大小,单位是byte SQL ordered by Version Count:记录了SQL的打开子游标的Top SQL SQL ordered by Cluster Wait Time:记录了收集间的等待时间的Top SQL
SQL 分析
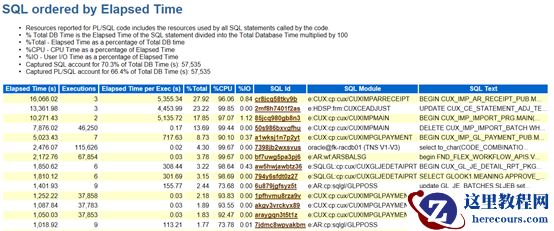 由上图可看出CPU
执行时间最长的前两个:第一个是一个存储过程,第二个是一个更新语句。
第一个SQL_Id
虽然执行时间最长,但CPU
消耗也不算太高,如果要理细致的分析SQL
执行情况,则需要对对应的程序做trace
,更加具体的看程序中某一步执行快和慢。
根据第二段SQL
可发现还有优化的空间,SQL
执行效率低,对SQL
进行优化
由上图可看出CPU
执行时间最长的前两个:第一个是一个存储过程,第二个是一个更新语句。
第一个SQL_Id
虽然执行时间最长,但CPU
消耗也不算太高,如果要理细致的分析SQL
执行情况,则需要对对应的程序做trace
,更加具体的看程序中某一步执行快和慢。
根据第二段SQL
可发现还有优化的空间,SQL
执行效率低,对SQL
进行优化
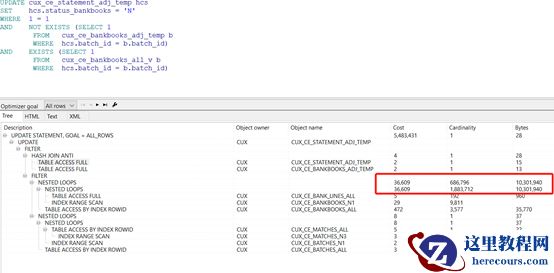 对SQL
进行优化,发现更新的语句比较简单,其中有用到视图,而视图有取标量子查询,因而优化策略直接将视图替换成基表,执行计划如下:
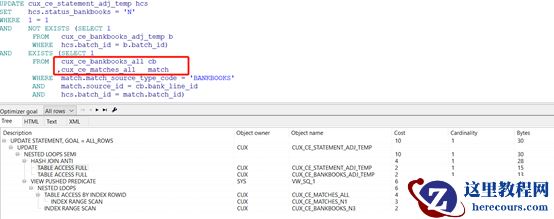
对SQL
进行优化,发现更新的语句比较简单,其中有用到视图,而视图有取标量子查询,因而优化策略直接将视图替换成基表,执行计划如下:
常用SQL
根据hash_value 查完整的SQL
SELECT sql_text FROM V$sqltext WHERE hash_value = '3556164644' --&hash_value ORDER BY piece;
SQL ordered by Elapsed Time
SELECT * FROM (SELECT substr(sql_text ,1 ,40) SQL ,disk_reads ,executions ,disk_reads / executions "Reads/Exec" ,hash_value ,address FROM v$sqlarea WHERE disk_reads > 0 AND executions > 0 ORDER BY elapsed_time DESC) WHERE rownum <= 10;
SQL ordered by CPU Time
SELECT * FROM (SELECT substr(sql_text ,1 ,40) SQL ,buffer_gets ,executions ,buffer_gets / executions "Gets/Exec" ,hash_value ,address FROM v$sqlarea WHERE buffer_gets > 0 AND executions > 0 ORDER BY buffer_gets DESC) WHERE rownum <= 10;
SQL ordered by Reads
SELECT * FROM (SELECT substr(sql_text ,1 ,40) SQL ,disk_reads ,executions ,disk_reads / executions "Reads/Exec" ,hash_value ,address FROM v$sqlarea WHERE disk_reads > 0 AND executions > 0 ORDER BY disk_reads DESC) WHERE rownum <= 10;
SQL ordered by Executions
SELECT * FROM (SELECT substr(sql_text ,1 ,40) SQL ,disk_reads ,executions ,disk_reads / executions "Reads/Exec" ,hash_value ,address FROM v$sqlarea WHERE disk_reads > 0 AND executions > 0 ORDER BY executions DESC) WHERE rownum <= 10;
SQL ordered by Parse Calls
这一部分主要显示PARSE 与EXECUTIONS 的对比情况。如果PARSE/EXECUTIONS>1, 往往说明这个语句可能存在问题:没有使用绑定变量,共享池设置太小,cursor_sharing 被设置为exact ,没有设置session_cached_cursors 等等问题。
SELECT * FROM (SELECT substr(sql_text ,1 ,40) SQL ,parse_calls ,executions ,hash_value ,address FROM v$sqlarea WHERE parse_calls > 0 ORDER BY parse_calls DESC) WHERE rownum <= 10;
SQL ordered by Sharable Memory
SELECT * FROM (SELECT substr(sql_text ,1 ,40) SQL ,sharable_mem ,executions ,hash_value ,address FROM v$sqlarea WHERE sharable_mem > 1048576 ORDER BY sharable_mem DESC) WHERE rownum <= 10;
Running Time top 10 sql
SELECT * FROM (SELECT t.sql_fulltext ,(t.last_active_time - to_date(t.first_load_time ,'yyyy-mm-dd hh24:mi:ss')) * 24 * 60 ,disk_reads ,buffer_gets ,rows_processed ,t.last_active_time ,t.last_load_time ,t.first_load_time FROM v$sqlarea t ORDER BY t.first_load_time DESC) WHERE rownum < 10;
通过语句查看执行计划
SELECT id
,parent_id
,lpad(' '
,4 * (LEVEL - 1)) || operation || ' ' || options || ' ' || object_name "Execution plan"
,cost
,cardinality
,bytes
FROM ( SELECT p.*
FROM v$sql_plan p
,v$sql s
WHERE p.address = s.address
AND p.hash_value = s.hash_value
AND p.sql_id = '6csrdyxcafcnu'
-- AND p.hash_value = 'cw0munxf2kkmm'
)
CONNECT BY PRIOR id = parent_id
START WITH id = 0;






及实例名(Instance_name or Service_name)")




